Сравнить коммиты
44 Коммитов
{kind=link}
|
После Ширина: | Высота: | Размер: 7.1 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 7.0 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 11 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 221 B |
{kind=link}
|
После Ширина: | Высота: | Размер: 189 B |
{kind=link}
|
После Ширина: | Высота: | Размер: 242 B |
{kind=link}
|
После Ширина: | Высота: | Размер: 244 B |
@ -0,0 +1,692 @@
|
||||
# Отчёт по лабораторной работе №1
|
||||
## по теме: "Архитектура и обучение глубоких нейронных сетей"
|
||||
|
||||
---
|
||||
Выполнили: Бригада 2, Мачулина Д.В., Бирюкова А.С., А-02-22
|
||||
|
||||
---
|
||||
### 1. Создание блокнота в Google Collab и настройка директории
|
||||
```python
|
||||
import os
|
||||
os.chdir('/content/drive/MyDrive/Colab Notebooks')
|
||||
```
|
||||
**Импорт библиотек**
|
||||
```python
|
||||
from tensorflow import keras
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
import sklearn
|
||||
```
|
||||
|
||||
---
|
||||
### 2. Загрузка набора данных MNIST
|
||||
```python
|
||||
from keras.datasets import mnist
|
||||
(X_train, y_train), (X_test, y_test) = mnist.load_data()
|
||||
```
|
||||
___
|
||||
### 3. Разбиение набора данных на обучающие и тестовые данные
|
||||
```python
|
||||
from sklearn.model_selection import train_test_split
|
||||
```
|
||||
**Объединение обучающих и тестовых данных в один набор**
|
||||
```python
|
||||
X = np.concatenate((X_train, X_test))
|
||||
y = np.concatenate((y_train, y_test))
|
||||
```
|
||||
**Разбиение набора случайным образом (номер бригады - 2)**
|
||||
```python
|
||||
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 10000, train_size = 60000, random_state = 7)
|
||||
```
|
||||
**Вывод размерностей**
|
||||
```python
|
||||
print('Shape of X train:', X_train.shape)
|
||||
print('Shape of y train:', y_train.shape)
|
||||
```
|
||||
*Shape of X train: (60000, 28, 28);
|
||||
Shape of y train: (60000,)*
|
||||
|
||||
### 4. Вывод элементов обучающих данных
|
||||
```python
|
||||
fig, axes = plt.subplots(1, 4, figsize=(10, 3))
|
||||
|
||||
for i in range(4):
|
||||
axes[i].imshow(X_train[i], cmap=plt.get_cmap('gray'))
|
||||
axes[i].set_title(f'Label: {y_train[i]}')
|
||||
|
||||
plt.show()
|
||||
```
|
||||
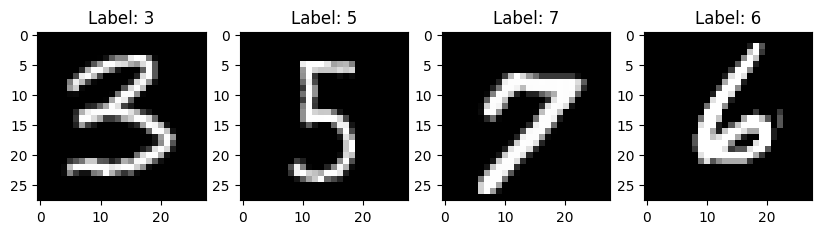
|
||||
|
||||
---
|
||||
### 5. Предобработка данных
|
||||
**Преобразование данных из массива в вектор**
|
||||
```python
|
||||
num_pixels = X_train.shape[1] * X_train.shape[2]
|
||||
X_train = X_train.reshape(X_train.shape[0], num_pixels) / 255
|
||||
X_test = X_test.reshape(X_test.shape[0], num_pixels) / 255
|
||||
print('Shape of transformed X train:', X_train.shape)
|
||||
```
|
||||
*Shape of transformed X train: (60000, 784)*
|
||||
|
||||
**Кодировка метод цифр по принципу one-hot encoding**
|
||||
```python
|
||||
from keras.utils import to_categorical
|
||||
y_train = to_categorical(y_train)
|
||||
y_test = to_categorical(y_test)
|
||||
print('Shape of transformed y train:', y_train.shape)
|
||||
num_classes = y_train.shape[1]
|
||||
```
|
||||
*Shape of transformed y train: (60000, 10)*
|
||||
|
||||
---
|
||||
### 6. Реализация модели нейронной сети
|
||||
```python
|
||||
from keras.models import Sequential
|
||||
from keras.layers import Dense
|
||||
```
|
||||
|
||||
**Создание и компиляция модели**
|
||||
```python
|
||||
model_01 = Sequential()
|
||||
model_01.add(Dense(units=num_classes,input_dim=num_pixels, activation='softmax'))
|
||||
model_01.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
|
||||
model_01.summary()
|
||||
```
|
||||
*Model: "sequential_5"*
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Layer (type)</th>
|
||||
<th>Output Shape</th>
|
||||
<th>Param #</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td rowspan=1 align="center">dense_10 (Dense)</td>
|
||||
<td rowspan=2 align="center">(None, 10)</td>
|
||||
<td align="center">7,850</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
*Total params: 7,850 (30.66 KB)*
|
||||
|
||||
*Trainable params: 7,850 (30.66 KB)*
|
||||
|
||||
*Non-trainable params: 0 (0.00 B)*
|
||||
|
||||
**Обучение модели**
|
||||
```python
|
||||
H = model_01.fit(
|
||||
X_train, y_train,
|
||||
validation_split=0.1,
|
||||
epochs=100,
|
||||
batch_size = 512
|
||||
)
|
||||
```
|
||||
**Вывод графика ошибки**
|
||||
```python
|
||||
plt.figure(figsize=(12, 5))
|
||||
|
||||
plt.subplot(1, 2, 1)
|
||||
plt.plot(H.history['loss'], label='Обучающая ошибка')
|
||||
plt.plot(H.history['val_loss'], label='Валидационная ошибка')
|
||||
plt.title('Функция ошибки по эпохам')
|
||||
plt.xlabel('Epochs')
|
||||
plt.ylabel('loss')
|
||||
plt.legend()
|
||||
plt.grid(True)
|
||||
```
|
||||
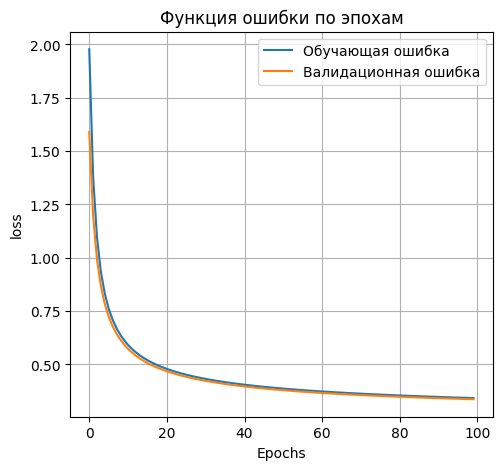
|
||||
|
||||
### 7. Применение модели к тестовым данным
|
||||
```python
|
||||
scores=model_01.evaluate(X_test,y_test)
|
||||
print('Loss on test data:', scores[0])
|
||||
print('Accuracy on test data:', scores[1])
|
||||
```
|
||||
*Loss on test data: 0.3511466085910797;*
|
||||
|
||||
*Accuracy on test data: 0.9067999720573425*
|
||||
|
||||
### 8. Повторные эксперименты с добавлением первого скрытого слоя
|
||||
**100 нейронов в первом скрытом слое:**
|
||||
```python
|
||||
model_01_100 = Sequential()
|
||||
model_01_100.add(Dense(units=100,input_dim=num_pixels, activation='sigmoid'))
|
||||
model_01_100.add(Dense(units=num_classes, activation='softmax'))
|
||||
model_01_100.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
|
||||
model_01_100.summary()
|
||||
```
|
||||
*Model: "sequential_6"*
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Layer (type)</th>
|
||||
<th>Output Shape</th>
|
||||
<th>Param #</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center">dense_11 (Dense)</td>
|
||||
<td align="center">(None, 100)</td>
|
||||
<td align="center">78,500</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">dense_12(Dense)</td>
|
||||
<td align="center">(None,10)</td>
|
||||
<td align="center">1,010</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
*Total params: 79,510 (310.59 KB)*
|
||||
|
||||
*Trainable params: 79,510 (310.59 KB)*
|
||||
|
||||
*Non-trainable params: 0 (0.00 B)*
|
||||
```python
|
||||
H_01_100 = model_01_100.fit(
|
||||
X_train, y_train,
|
||||
validation_split=0.1,
|
||||
epochs=100,
|
||||
batch_size = 512
|
||||
)
|
||||
```
|
||||
```python
|
||||
plt.figure(figsize=(12, 5))
|
||||
|
||||
plt.subplot(1, 2, 1)
|
||||
plt.plot(H_01_100.history['loss'], label='Обучающая ошибка')
|
||||
plt.plot(H_01_100.history['val_loss'], label='Валидационная ошибка')
|
||||
plt.title('Функция ошибки по эпохам')
|
||||
plt.xlabel('Epochs')
|
||||
plt.ylabel('loss')
|
||||
plt.legend()
|
||||
plt.grid(True)
|
||||
```
|
||||
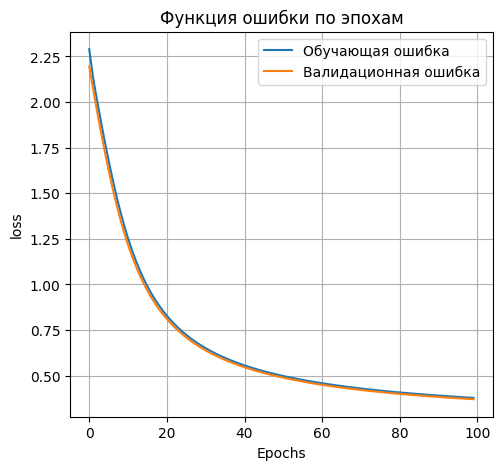
|
||||
```python
|
||||
scores_01_100=model_01_100.evaluate(X_test,y_test)
|
||||
print('Loss on test data:', scores_01_100[0])
|
||||
print('Accuracy on test data:', scores_01_100[1])
|
||||
```
|
||||
*Loss on test data: 0.3824511766433716*
|
||||
|
||||
*Accuracy on test data: 0.9000999927520752*
|
||||
|
||||
**300 нейронов в первом скрытом слое**
|
||||
```python
|
||||
model_01_300 = Sequential()
|
||||
model_01_300.add(Dense(units=300,input_dim=num_pixels, activation='sigmoid'))
|
||||
model_01_300.add(Dense(units=num_classes, activation='softmax'))
|
||||
model_01_300.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
|
||||
model_01_300.summary()
|
||||
```
|
||||
*Model: "sequential_7"*
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Layer (type)</th>
|
||||
<th>Output Shape</th>
|
||||
<th>Param #</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center">dense_13 (Dense)</td>
|
||||
<td align="center">(None, 300)</td>
|
||||
<td align="center">235,500</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">dense_14(Dense)</td>
|
||||
<td align="center">(None,10)</td>
|
||||
<td align="center">3,010</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
*Total params: 238,510 (931.68 KB)*
|
||||
|
||||
*Trainable params: 238,510 (931.68 KB)*
|
||||
|
||||
*Non-trainable params: 0 (0.00 B)*
|
||||
|
||||
```python
|
||||
H_01_300 = model_01_300.fit(
|
||||
X_train, y_train,
|
||||
validation_split=0.1,
|
||||
epochs=100,
|
||||
batch_size = 512
|
||||
)
|
||||
```
|
||||
```python
|
||||
plt.figure(figsize=(12, 5))
|
||||
|
||||
plt.subplot(1, 2, 1)
|
||||
plt.plot(H_01_300.history['loss'], label='Обучающая ошибка')
|
||||
plt.plot(H_01_300.history['val_loss'], label='Валидационная ошибка')
|
||||
plt.title('Функция ошибки по эпохам')
|
||||
plt.xlabel('Epochs')
|
||||
plt.ylabel('loss')
|
||||
plt.legend()
|
||||
plt.grid(True)
|
||||
```
|
||||
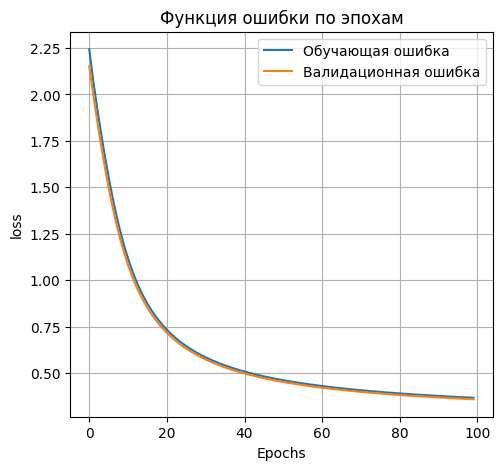
|
||||
```python
|
||||
scores_01_300=model_01_300.evaluate(X_test,y_test)
|
||||
print('Loss on test data:', scores_01_300[0])
|
||||
print('Accuracy on test data:', scores_01_300[1])
|
||||
```
|
||||
|
||||
*Loss on test data: 0.37091827392578125*
|
||||
|
||||
*Accuracy on test data: 0.9013000130653381*
|
||||
|
||||
**500 нейронов в первом скрытом слое**
|
||||
```python
|
||||
model_01_500 = Sequential()
|
||||
model_01_500.add(Dense(units=500,input_dim=num_pixels, activation='sigmoid'))
|
||||
model_01_500.add(Dense(units=num_classes, activation='softmax'))
|
||||
model_01_500.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
|
||||
model_01_500.summary()
|
||||
```
|
||||
*Model: "sequential_8"*
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Layer (type)</th>
|
||||
<th>Output Shape</th>
|
||||
<th>Param #</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center">dense_15 (Dense)</td>
|
||||
<td align="center">(None, 500)</td>
|
||||
<td align="center">392,500</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">dense_16(Dense)</td>
|
||||
<td align="center">(None,10)</td>
|
||||
<td align="center">5,010</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
*Total params: 397,510 (1.52 MB)*
|
||||
|
||||
*Trainable params: 397,510 (1.52 MB)*
|
||||
|
||||
*Non-trainable params: 0 (0.00 B)*
|
||||
|
||||
```python
|
||||
H_01_500 = model_01_500.fit(
|
||||
X_train, y_train,
|
||||
validation_split=0.1,
|
||||
epochs=100,
|
||||
batch_size = 512
|
||||
)
|
||||
```
|
||||
```python
|
||||
plt.figure(figsize=(12, 5))
|
||||
|
||||
plt.subplot(1, 2, 1)
|
||||
plt.plot(H_01_500.history['loss'], label='Обучающая ошибка')
|
||||
plt.plot(H_01_500.history['val_loss'], label='Валидационная ошибка')
|
||||
plt.title('Функция ошибки по эпохам')
|
||||
plt.xlabel('Epochs')
|
||||
plt.ylabel('loss')
|
||||
plt.legend()
|
||||
plt.grid(True)
|
||||
```
|
||||
|
||||
```python
|
||||
scores_01_500=model_01_500.evaluate(X_test,y_test)
|
||||
print('Loss on test data:',scores_01_500[0])
|
||||
print('Accuracy on test data:',scores_01_500[1])
|
||||
```
|
||||
*Loss on test data: 0.36660370230674744*
|
||||
|
||||
*Accuracy on test data: 0.9010000228881836*
|
||||
|
||||
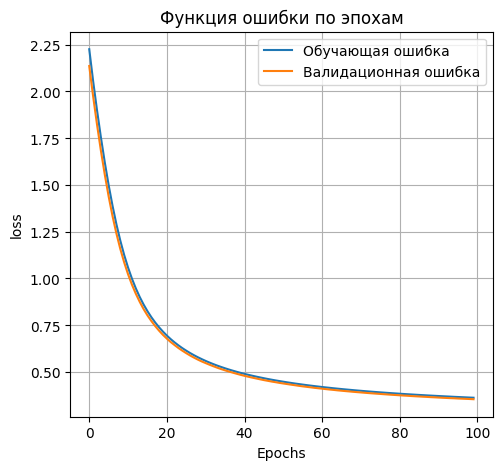
Таким образом, наиболее точной архитектурой со скрытым слоем является архитектура со 300 нейронами в скрытом слое. Для дальнейшей работы будем использовать её.
|
||||
|
||||
### 9. Повторные эксперименты с добавлением второго скрытого слоя
|
||||
**50 нейронов во втором скрытом слое**
|
||||
```python
|
||||
model_01_300_50 = Sequential()
|
||||
model_01_300_50.add(Dense(units=300, input_dim=num_pixels, activation='sigmoid'))
|
||||
model_01_300_50.add(Dense(units=50, activation='sigmoid'))
|
||||
model_01_300_50.add(Dense(units=num_classes, activation='softmax'))
|
||||
model_01_300_50.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
|
||||
model_01_300_50.summary()
|
||||
```
|
||||
*Model: "sequential_11"*
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Layer (type)</th>
|
||||
<th>Output Shape</th>
|
||||
<th>Param #</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center">dense_23 (Dense)</td>
|
||||
<td align="center">(None, 300)</td>
|
||||
<td align="center">235,500</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">dense_24(Dense)</td>
|
||||
<td align="center">(None,50)</td>
|
||||
<td align="center">15,050</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">dense_25 (Dense)</td>
|
||||
<td align="center">(None,10)</td>
|
||||
<td align="center">510</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
*Total params: 251,060 (328.36 KB)*
|
||||
|
||||
*Trainable params: 251,060 (328.36 KB)*
|
||||
|
||||
*Non-trainable params: 0 (0.00 B)*
|
||||
|
||||
```python
|
||||
H_01_300_50 = model_01_300_50.fit(
|
||||
X_train, y_train,
|
||||
validation_split=0.1,
|
||||
epochs=100,
|
||||
batch_size=512
|
||||
)
|
||||
```
|
||||
```python
|
||||
plt.figure(figsize=(12, 5))
|
||||
|
||||
plt.subplot(1, 2, 1)
|
||||
plt.plot(H_01_300_50.history['loss'], label='Обучающая ошибка')
|
||||
plt.plot(H_01_300_50.history['val_loss'], label='Валидационная ошибка')
|
||||
plt.title('Функция ошибки по эпохам')
|
||||
plt.xlabel('Epochs')
|
||||
plt.ylabel('loss')
|
||||
plt.legend()
|
||||
plt.grid(True)
|
||||
```
|
||||
|
||||
```python
|
||||
scores_01_300_50=model_01_300_50.evaluate(X_test,y_test)
|
||||
print('Loss on test data:',scores_01_300_50[0])
|
||||
print('Accuracy on test data:',scores_01_300_50[1])
|
||||
```
|
||||
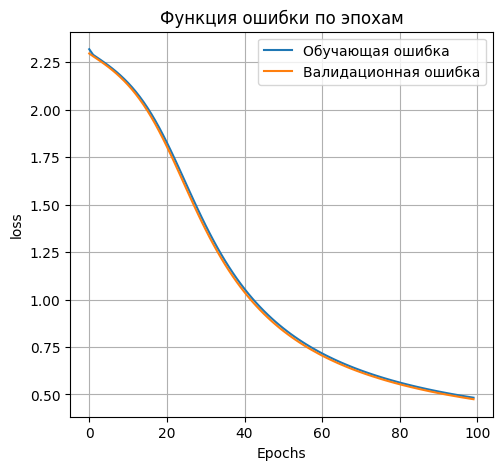
*Loss on test data: 0.4881931245326996*
|
||||
|
||||
*Accuracy on test data: 0.8740000128746033*
|
||||
|
||||
**100 нейронов во втором скрытом слое**
|
||||
```python
|
||||
model_01_300_100 = Sequential()
|
||||
model_01_300_100.add(Dense(units=300, input_dim=num_pixels, activation='sigmoid'))
|
||||
model_01_300_100.add(Dense(units=100, activation='sigmoid'))
|
||||
model_01_300_100.add(Dense(units=num_classes, activation='softmax'))
|
||||
model_01_300_100.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
|
||||
model_01_300_100.summary()
|
||||
```
|
||||
*Model: "sequential_12"*
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Layer (type)</th>
|
||||
<th>Output Shape</th>
|
||||
<th>Param #</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center">dense_26 (Dense)</td>
|
||||
<td align="center">(None, 300)</td>
|
||||
<td align="center">235,500</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">dense_27(Dense)</td>
|
||||
<td align="center">(None,100)</td>
|
||||
<td align="center">30,100</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">dense_28 (Dense)</td>
|
||||
<td align="center">(None,10)</td>
|
||||
<td align="center">1,010</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
*Total params: 266,610 (350.04 KB)*
|
||||
|
||||
*Trainable params: 266,610 (350.04 KB)*
|
||||
|
||||
*Non-trainable params: 0 (0.00 B)*
|
||||
|
||||
```python
|
||||
H_01_300_100 = model_01_300_100.fit(
|
||||
X_train, y_train,
|
||||
validation_split=0.1,
|
||||
epochs=100,
|
||||
batch_size=512
|
||||
)
|
||||
```
|
||||
```python
|
||||
plt.figure(figsize=(12, 5))
|
||||
|
||||
plt.subplot(1, 2, 1)
|
||||
plt.plot(H_01_300_100.history['loss'], label='Обучающая ошибка')
|
||||
plt.plot(H_01_300_100.history['val_loss'], label='Валидационная ошибка')
|
||||
plt.title('Функция ошибки по эпохам')
|
||||
plt.xlabel('Epochs')
|
||||
plt.ylabel('loss')
|
||||
plt.legend()
|
||||
plt.grid(True)
|
||||
```
|
||||
|
||||
```python
|
||||
scores_01_300_100=model_01_300_100.evaluate(X_test,y_test)
|
||||
print('Lossontestdata:',scores_01_300_100[0])
|
||||
print('Accuracyontestdata:',scores_01_300_100[1])
|
||||
```
|
||||
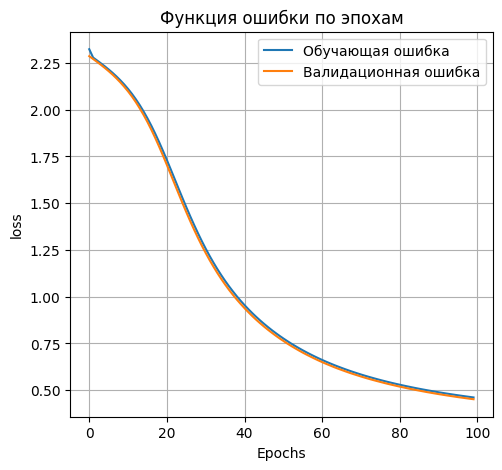
*Loss on test data: 0.4638420343399048*
|
||||
|
||||
*Accuracy on test data: 0.8795999884605408*
|
||||
|
||||
**Сведём результаты в таблицу**
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Количество скрытых слоёв (type)</th>
|
||||
<th>Количество нейронов в первом скрытом слое</th>
|
||||
<th>Количество нейронов во втором скрытом слое </th>
|
||||
<th>Значение метрики качества классификации</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center">0</td>
|
||||
<td align="center">-</td>
|
||||
<td align="center">-</td>
|
||||
<td align="center">0.9067999720573425</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td rowspan = 3 align="center">1</td>
|
||||
<td align="center">100</td>
|
||||
<td rowspan =3 align="center">-</td>
|
||||
<td align="center">0.9000999927520752</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">300</td>
|
||||
<td align="center">0.9013000130653381</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">500</td>
|
||||
<td align="center">0.9010000228881836</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td rowspan = 2 align="center">2</td>
|
||||
<td rowspan = 2 align="center">300</td>
|
||||
<td align="center">50</td>
|
||||
<td align="center">0.8740000128746033</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">100</td>
|
||||
<td align="center">0.8795999884605408</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### 11.Сохранение лучшей модели на диск
|
||||
```python
|
||||
model_01_300.save(filepath='best_model.keras')
|
||||
```
|
||||
|
||||
### 12. Вывод тестовых изображений
|
||||
**Загрузка лучшей модели с диска**
|
||||
```python
|
||||
from keras.models import load_model
|
||||
model = load_model('best_model.keras')
|
||||
```
|
||||
**Вывод изображений**
|
||||
```python
|
||||
n = 123
|
||||
result = model.predict(X_test[n:n+1])
|
||||
print('NN output:', result)
|
||||
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
print('Real mark: ', str(np.argmax(y_test[n])))
|
||||
print('NN answer: ', str(np.argmax(result)))
|
||||
```
|
||||
|
||||
|
||||
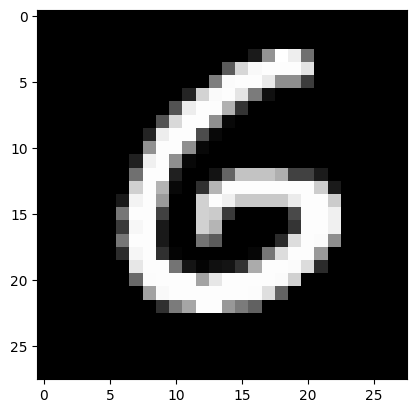
*Real mark: 6*
|
||||
|
||||
*NN answer: 6*
|
||||
|
||||
```python
|
||||
n = 765
|
||||
result = model.predict(X_test[n:n+1])
|
||||
print('NN output:', result)
|
||||
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
print('Real mark: ', str(np.argmax(y_test[n])))
|
||||
print('NN answer: ', str(np.argmax(result)))
|
||||
```
|
||||
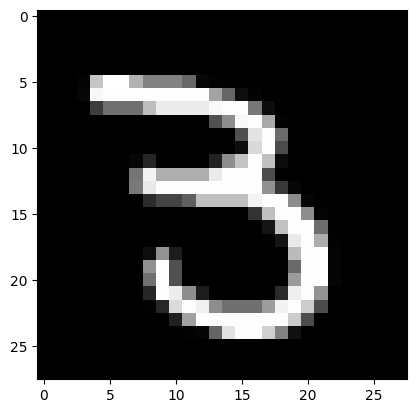
|
||||
|
||||
*Real mark: 3*
|
||||
|
||||
*NN answer: 3*
|
||||
|
||||
### 13. Тестирование на собственных изображениях
|
||||
**Загрузка собственного изображения**
|
||||
```python
|
||||
from PIL import Image
|
||||
file_07_data = Image.open('7.png')
|
||||
file_07_data = file_07_data.convert('L')
|
||||
test_07_img = np.array(file_07_data)
|
||||
```
|
||||
**Вывод изображения**
|
||||
```python
|
||||
plt.imshow(test_07_img, cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
```
|
||||

|
||||
|
||||
**Распознавание изображения**
|
||||
```python
|
||||
test_07_img = test_07_img / 255
|
||||
test_07_img = test_07_img.reshape(1, num_pixels)
|
||||
```
|
||||
*I think it's 7*
|
||||
|
||||
**Второе изображение**
|
||||
```python
|
||||
from PIL import Image
|
||||
file_05_data = Image.open('5.png')
|
||||
file_05_data = file_05_data.convert('L')
|
||||
test_05_img = np.array(file_05_data)
|
||||
```
|
||||
```python
|
||||
plt.imshow(test_05_img, cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
```
|
||||

|
||||
|
||||
|
||||
```python
|
||||
test_05_img = test_05_img / 255
|
||||
test_05_img = test_05_img.reshape(1, num_pixels)
|
||||
```
|
||||
```python
|
||||
result = model.predict(test_05_img)
|
||||
print('I think it\'s ', np.argmax(result))
|
||||
```
|
||||
*I think it's 5*
|
||||
|
||||
Нейросеть распознала изображения корректно
|
||||
|
||||
### 14. Тестирование на собственных перевёрнутых изображениях
|
||||
**Первое изображение**
|
||||
```python
|
||||
from PIL import Image
|
||||
file_07_90_data = Image.open('7-90.png')
|
||||
file_07_90_data = file_07_90_data.convert('L')
|
||||
test_07_90_img = np.array(file_07_90_data)
|
||||
```
|
||||
```python
|
||||
plt.imshow(test_07_90_img, cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
```
|
||||

|
||||
|
||||
|
||||
```python
|
||||
test_07_90_img = test_07_90_img / 255
|
||||
test_07_90_img = test_07_90_img.reshape(1, num_pixels)
|
||||
```
|
||||
```python
|
||||
result = model.predict(test_07_90_img)
|
||||
print('I think it\'s ', np.argmax(result))
|
||||
```
|
||||
*I think it's 2*
|
||||
|
||||
**Второе изображение**
|
||||
```python
|
||||
from PIL import Image
|
||||
file_05_90_data = Image.open('5-90.png')
|
||||
file_05_90_data = file_05_90_data.convert('L')
|
||||
test_05_90_img = np.array(file_05_90_data)
|
||||
```
|
||||
```python
|
||||
plt.imshow(test_05_90_img, cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
```
|
||||

|
||||
|
||||
|
||||
```python
|
||||
test_05_90_img = test_05_90_img / 255
|
||||
test_05_90_img = test_05_90_img.reshape(1, num_pixels)
|
||||
```
|
||||
```python
|
||||
result = model.predict(test_05_90_img)
|
||||
print('I think it\'s ', np.argmax(result))
|
||||
```
|
||||
*I think it's 4*
|
||||
|
||||
Нейросеть не смогла распознать изображения
|
||||
|
||||
**Вывод по архитектуре**: анализируя полученные результаты, можем прийти к выводу, что с ростом количества нейронов точность сначала улучшается - сеть обучается лучше, а при 500 нейронах - немного падает качество классификации, что может свидетельствовать о том, что алгоритм «застревал» в каком-то локальном минимуме; либо слишком малое время обучения - сеть не успевает обучиться, из-за чего страдает качество конечного результата. В данном примере это не критично, так как переобучение не наблюдается, а сама по себе точность достаточно высокая.
|
||||
|
||||
**Вывод по картинкам**: проанализировав результаты работы сети, делаем вывод, что нейросеть справилась только с прямыми изображениями, повёрнутые она распознать не смогла. Это логично, потому что обучали её только на прямых изображениях. Если необходимо, чтобы картинки распознавались в том числе перевёрнутыми, в обучающую выборку стоит включить изображения такого же характера.
|
||||
{kind=link}
|
После Ширина: | Высота: | Размер: 30 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 32 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 32 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 34 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 33 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 32 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 20 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 21 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 34 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 31 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 35 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 34 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 62 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 62 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 60 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 95 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 112 KiB |
@ -0,0 +1,4 @@
|
||||
* [Задание](IS_Lab02_2023.pdf)
|
||||
* [Методические указания](IS_Lab02_Metod_2023.pdf)
|
||||
* [Наборы данных](data)
|
||||
* [Библиотека для автокодировщиков](lab02_lib.py)
|
||||
@ -0,0 +1,976 @@
|
||||
# Отчёт по лабораторной работе №2
|
||||
## по теме: "Обнаружение аномалий"
|
||||
|
||||
---
|
||||
Выполнили: Бригада 2, Мачулина Д.В., Бирюкова А.С., А-02-22
|
||||
|
||||
Данные - WBC
|
||||
|
||||
---
|
||||
|
||||
## Задание 1
|
||||
### 1. Создание блокнота и настройка среды
|
||||
|
||||
```python
|
||||
from google.colab import drive
|
||||
drive.mount('/content/drive')
|
||||
import os
|
||||
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab2')
|
||||
import numpy as np
|
||||
import lab02_lib as lib
|
||||
```
|
||||
|
||||
```python
|
||||
work_dir = '/content/drive/MyDrive/Colab Notebooks/is_lab2'
|
||||
os.makedirs(work_dir, exist_ok=True)
|
||||
os.chdir(work_dir)
|
||||
os.makedirs('out', exist_ok=True)
|
||||
dataset_name = 'WBC'
|
||||
base_url = "http://uit.mpei.ru/git/main/is_dnn/raw/branch/main/labworks/LW2/"
|
||||
!wget -N {base_url}lab02_lib.py
|
||||
!wget -N {base_url}data/{dataset_name}_train.txt
|
||||
!wget -N {base_url}data/{dataset_name}_test.txt
|
||||
```
|
||||
---
|
||||
### 2. Генерация индивидуального набора двумерных данных
|
||||
|
||||
```python
|
||||
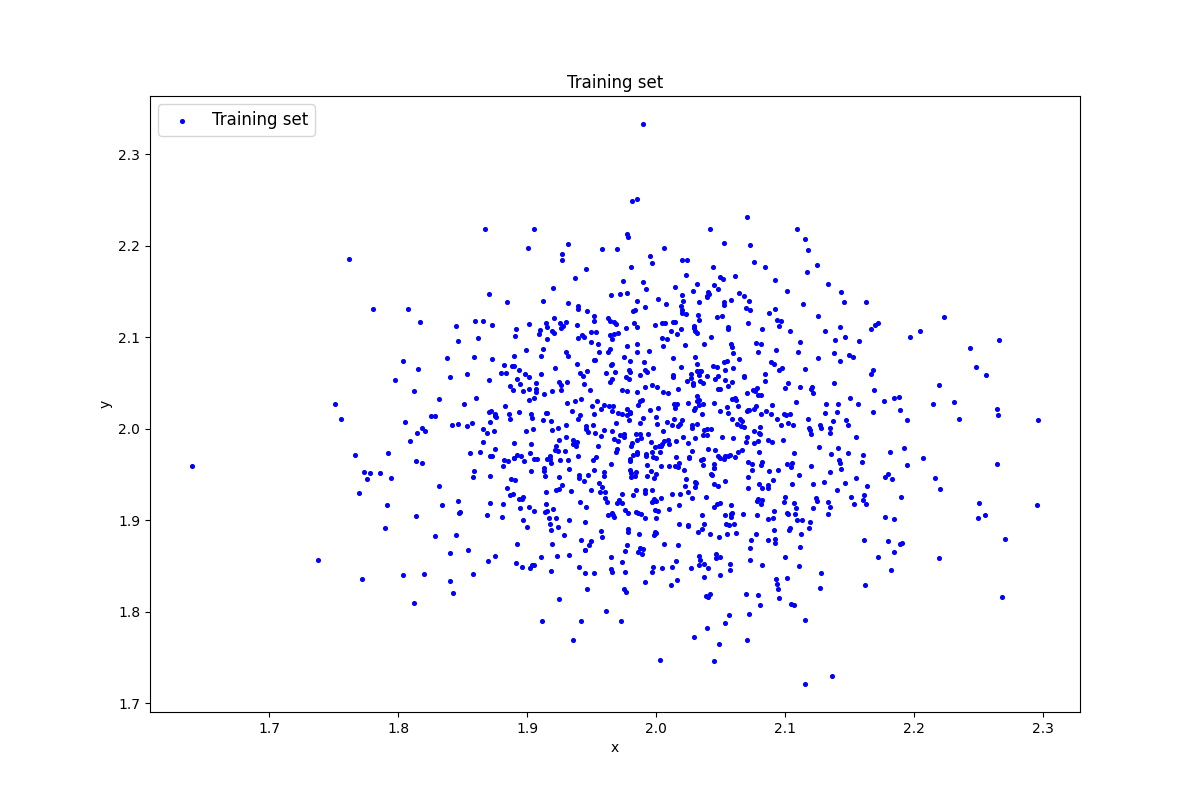
data = lib.datagen(2, 2, 1000, 2)
|
||||
|
||||
print('Исходные данные:')
|
||||
print(data)
|
||||
print('Размерность данных:')
|
||||
print(data.shape)
|
||||
```
|
||||
|
||||
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th colspan=2 align="center">Исходные данные</th></tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>1.9863081 </td>
|
||||
<td>1.86491133</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>2.04641244 </td>
|
||||
<td>1.8589354</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>1.89688572</td>
|
||||
<td>1.89978633</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td colspan =2 align="center">...</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>1.99310837</td>
|
||||
<td>2.06214288</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>1.94695115</td>
|
||||
<td>1.99630611</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>1.79129354</td>
|
||||
<td>1.91688919</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Размерность данных: (1000, 2)
|
||||
|
||||
---
|
||||
### 3. Создание и обучение автокодировщика АЕ1 простой архитектуры
|
||||
```python
|
||||
patience = 300
|
||||
ae1_trained, IRE1, IREth1 = lib.create_fit_save_ae(data,'out/AE1.h5','out/AE1_ire_th.txt',
|
||||
1000, True, patience)
|
||||
```
|
||||
Параметры: (1 скрытый слой, 1 нейрон)
|
||||
|
||||
---
|
||||
### 4. Построение графика ошибки реконструкции
|
||||
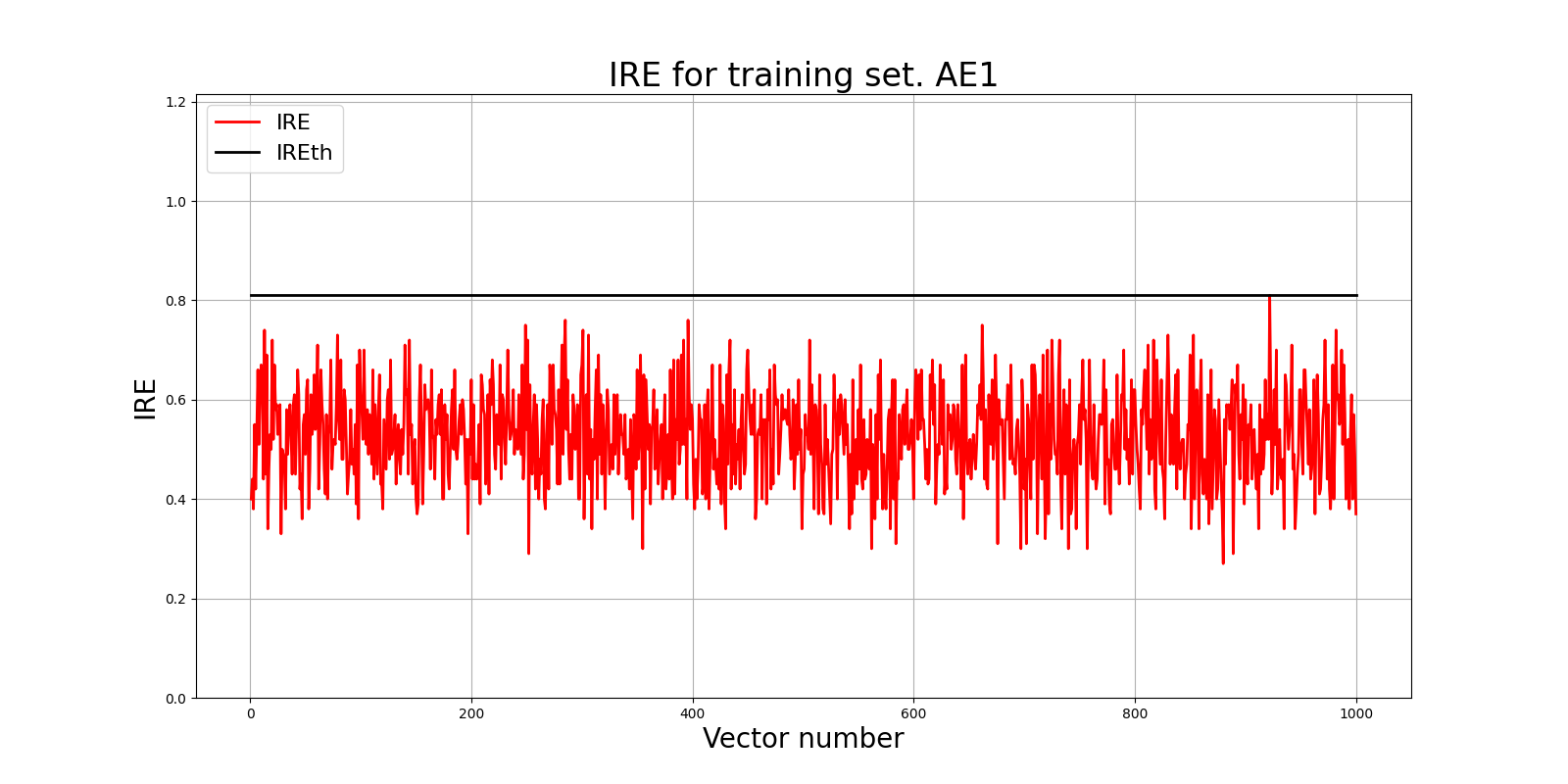
Ошибка MSE_AE1 = 0.1370
|
||||
```python
|
||||
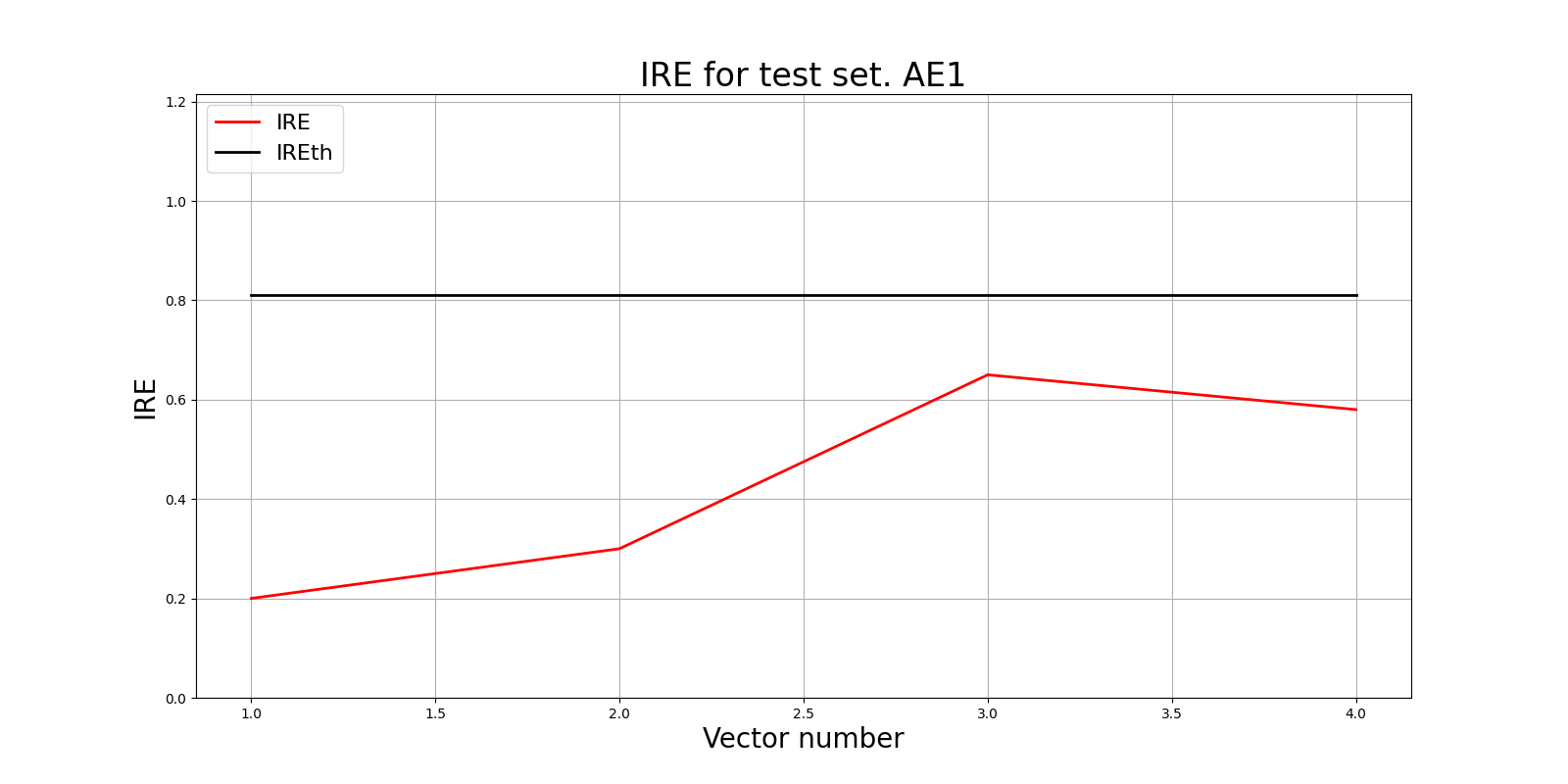
lib.ire_plot('training', IRE1, IREth1, 'AE1')
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
Порог ошибки реконструкции = 0.81
|
||||
|
||||
---
|
||||
### 5. Создание и обучение автокодировщика АЕ2 усложнённой архитектуры
|
||||
```python
|
||||
ae2_trained, IRE2, IREth2 = lib.create_fit_save_ae(data,'out/AE2.h5','out/AE2_ire_th.txt',
|
||||
3000, True, patience)
|
||||
```
|
||||
Параметры: (5 скрытых слоёв; 3 2 1 2 3)
|
||||
|
||||
---
|
||||
### 6. Построение графика ошибки реконструкции
|
||||
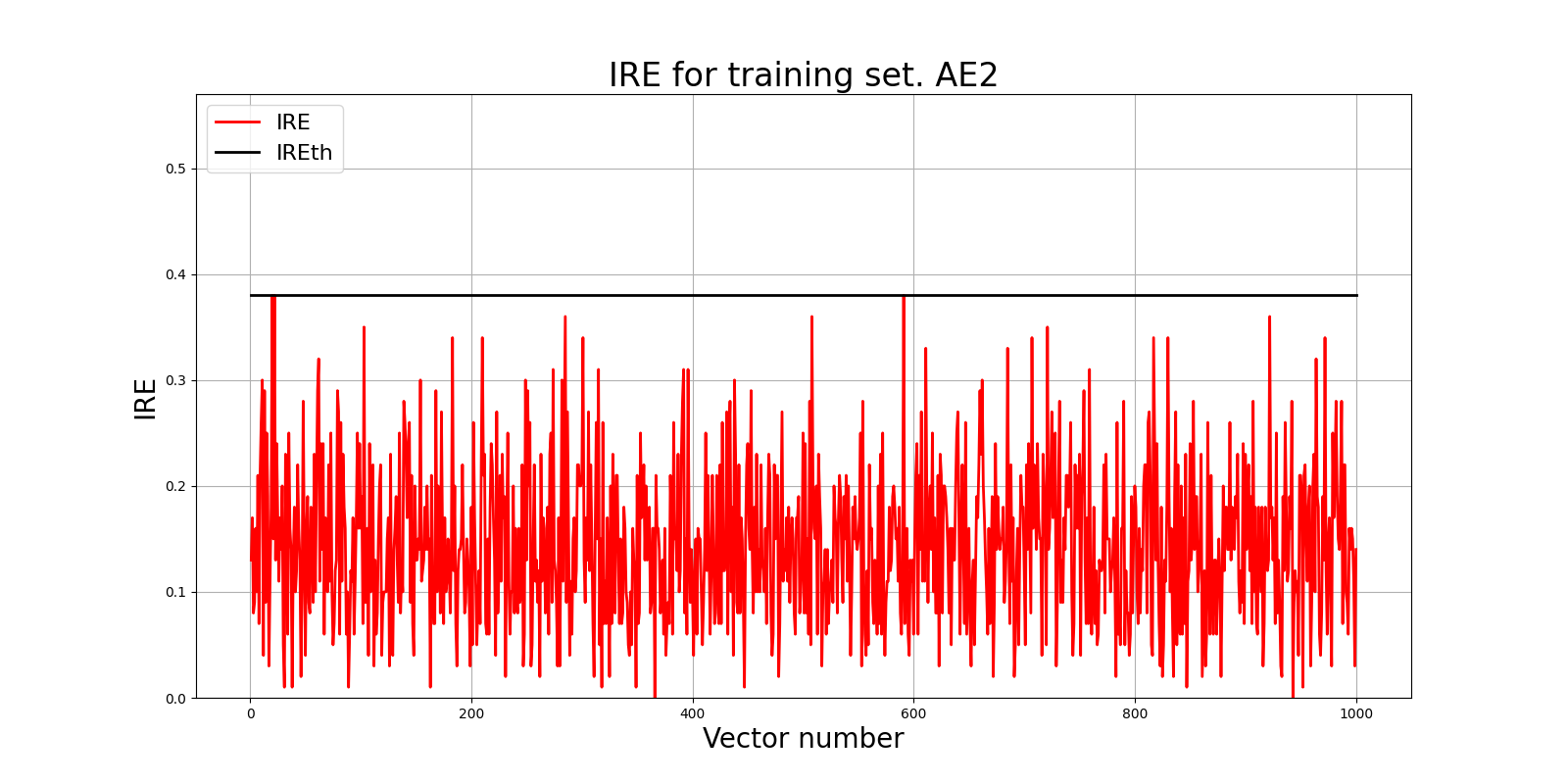
Ошибка MSE_AE2 = 0.0094
|
||||
```python
|
||||
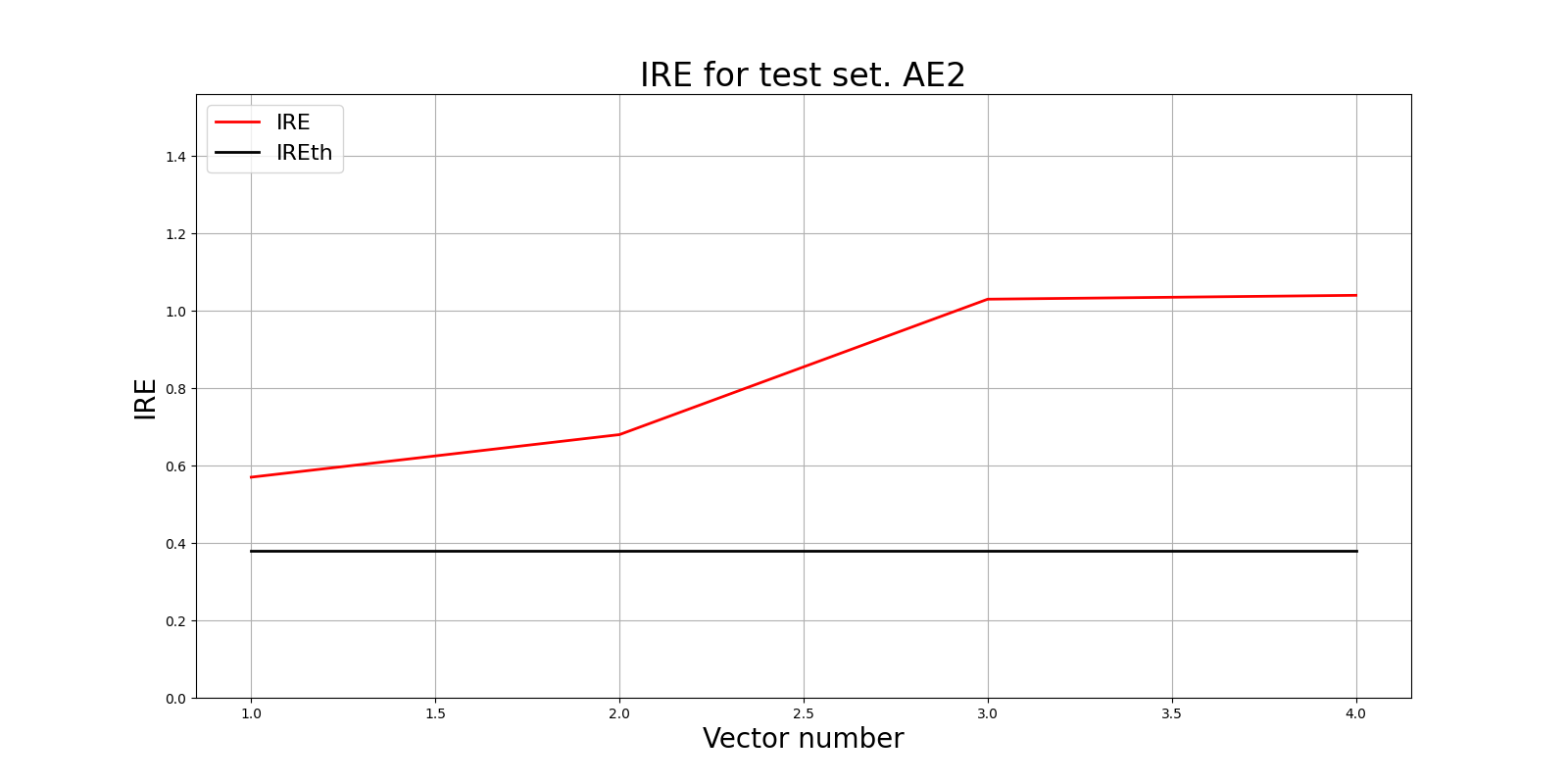
lib.ire_plot('training', IRE2, IREth2, 'AE2')
|
||||
```
|
||||
|
||||
|
||||
|
||||
Порог ошибки реконструкции = 0.38
|
||||
|
||||
---
|
||||
### 7. Расчёт характеристик качества обучения EDCA. Визуализация и сравнение
|
||||
**АЕ1**
|
||||
```python
|
||||
numb_square = 20
|
||||
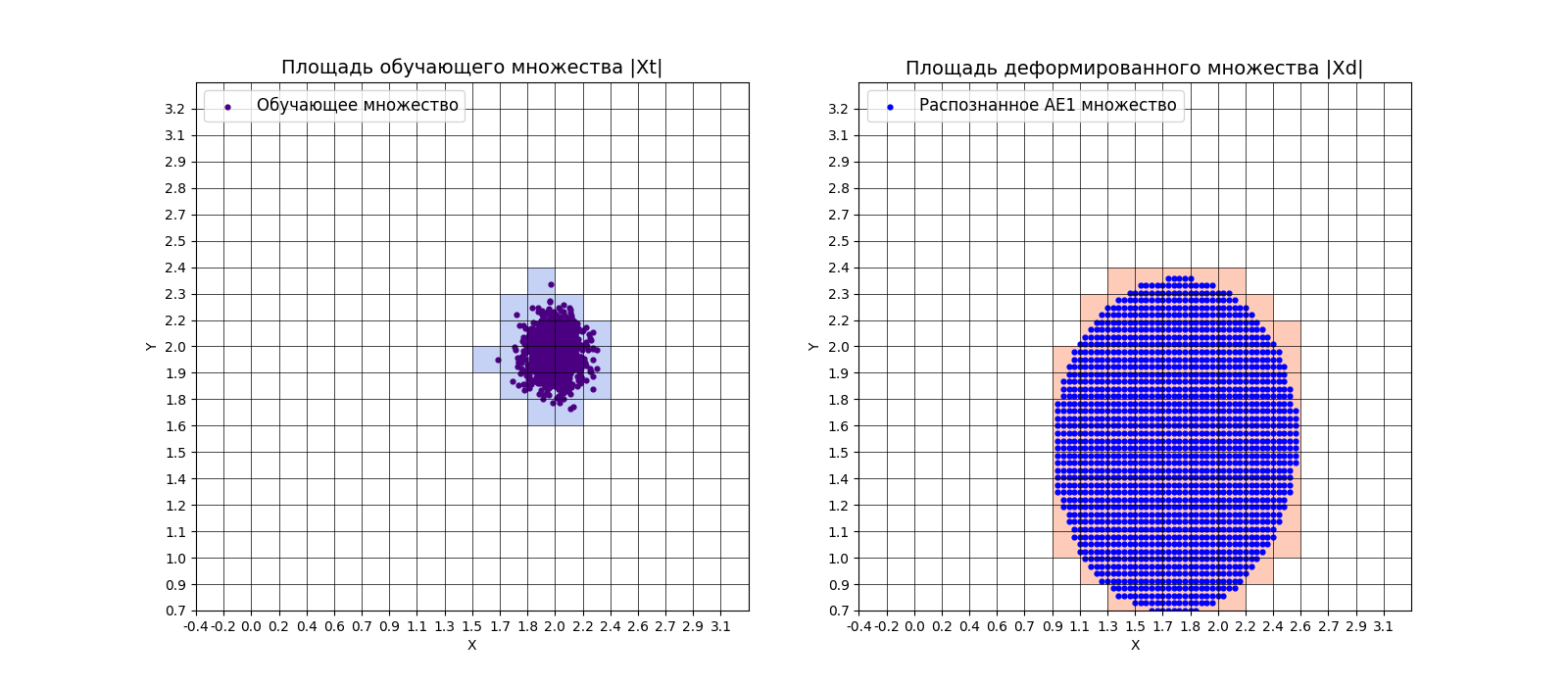
xx, yy, Z1 = lib.square_calc(numb_square, data, ae1_trained, IREth1, '1', True)
|
||||
```
|
||||
|
||||
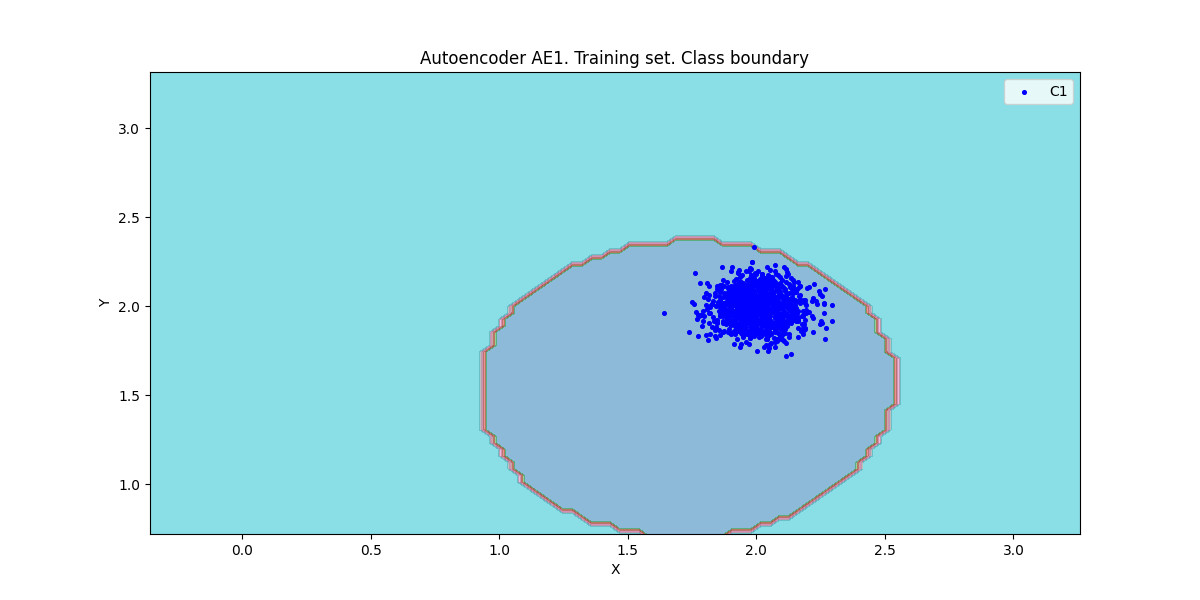
|
||||
|
||||
amount: 19
|
||||
|
||||
amount_ae: 104
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**Оценка качества AE1**
|
||||
|
||||
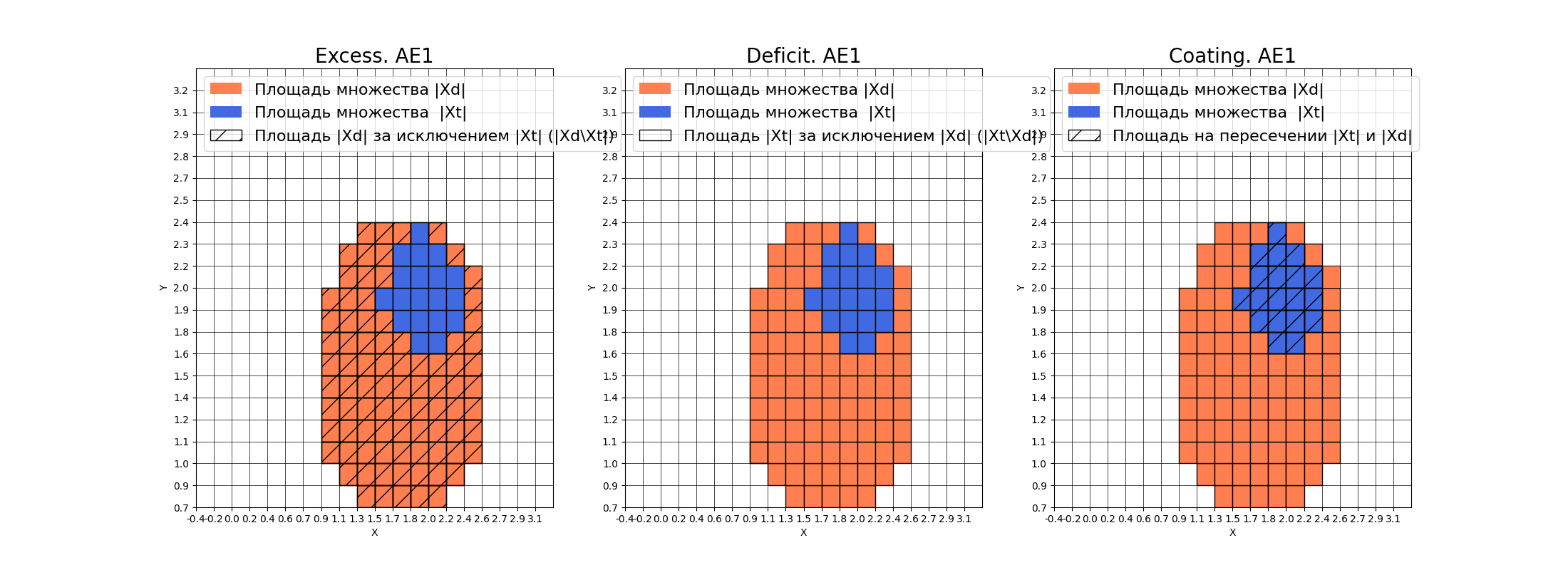
* IDEAL = 0. Excess: 4.473684210526316
|
||||
|
||||
* IDEAL = 0. Deficit: 0.0
|
||||
|
||||
* IDEAL = 1. Coating: 1.0
|
||||
|
||||
* summa: 1.0
|
||||
|
||||
* IDEAL = 1. Extrapolation precision (Approx): 0.18269230769230768
|
||||
|
||||
|
||||
**АЕ2**
|
||||
```python
|
||||
numb_square = 20
|
||||
xx, yy, Z2 = lib.square_calc(numb_square, data, ae2_trained, IREth2, '2', True)
|
||||
```
|
||||
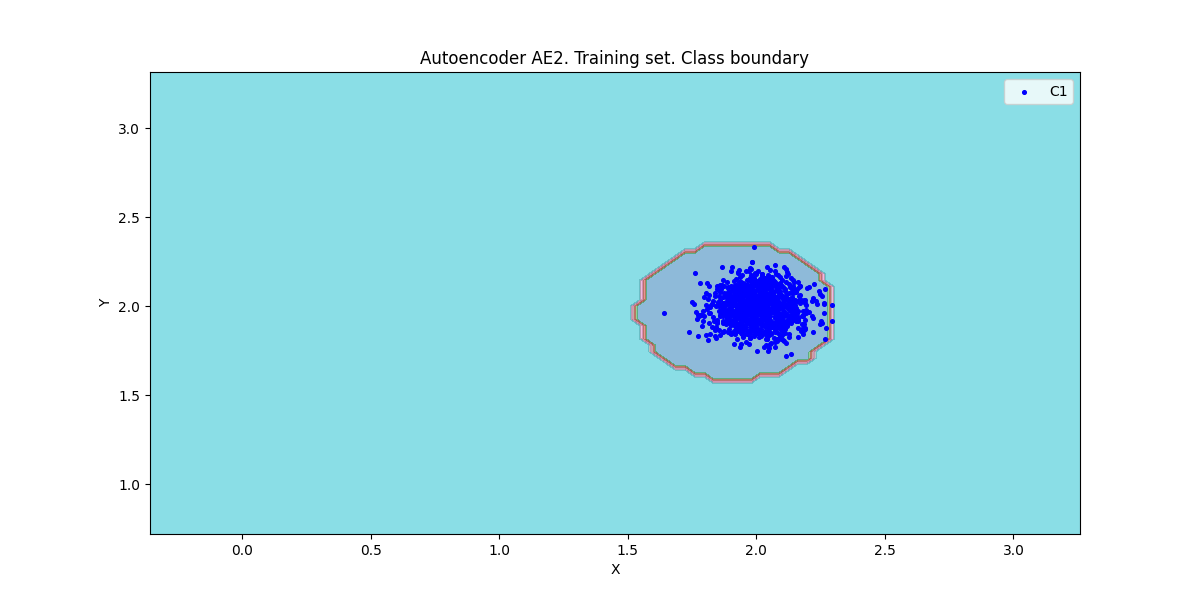
|
||||
|
||||
amount: 19
|
||||
|
||||
amount_ae: 31
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
**Оценка качества АЕ2**
|
||||
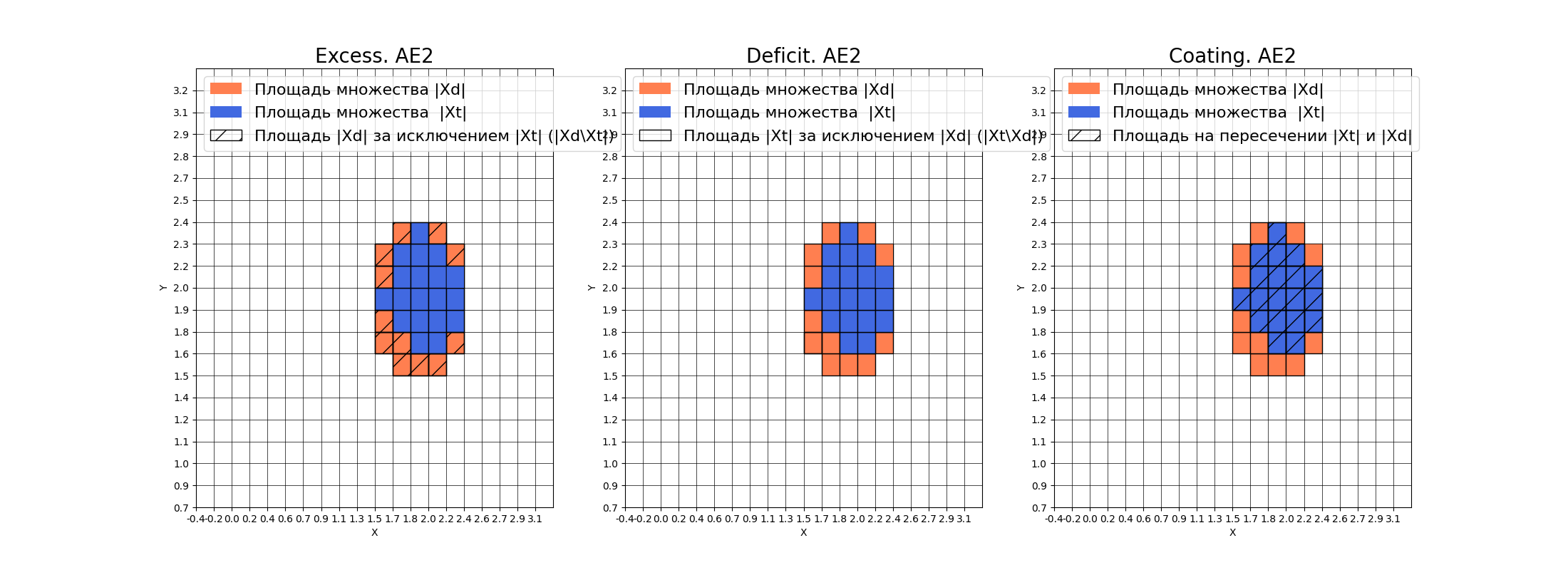
* IDEAL = 0. Excess: 0.631578947368421
|
||||
* IDEAL = 0. Deficit: 0.0
|
||||
* IDEAL = 1. Coating: 1.0
|
||||
* summa: 1.0
|
||||
* IDEAL = 1. Extrapolation precision (Approx): 0.612903225806
|
||||
|
||||
|
||||
**Сравнение**
|
||||
```python
|
||||
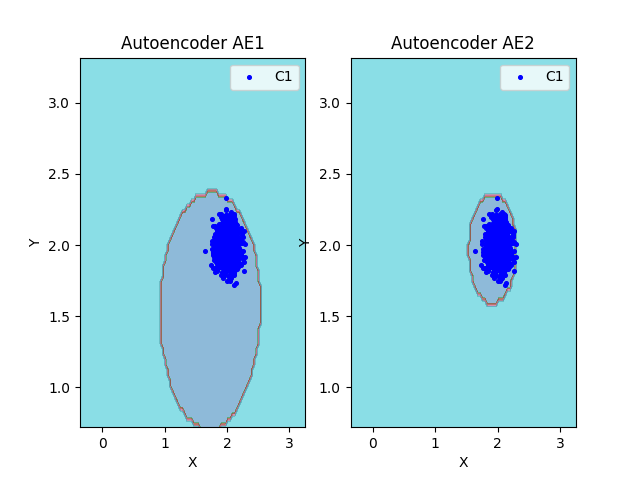
lib.plot2in1(data, xx, yy, Z1, Z2)
|
||||
```
|
||||
|
||||
|
||||
|
||||
---
|
||||
### 8. Редактирование автокодировщика АЕ2
|
||||
Полученная аппроксимация автокодировщиком АЕ2 - удовлетворительна.
|
||||
|
||||
---
|
||||
### 9. Создание тестовой выборки и применение к ней автокодировщиков
|
||||
```python
|
||||
with open('data_test.txt', 'w') as file:
|
||||
file.write("1.5327 1.5591\n")
|
||||
file.write("1.4373 1.4932\n")
|
||||
file.write("1.1231 1.3212\n")
|
||||
file.write("1.3211 1.1231\n")
|
||||
data_test = np.loadtxt('data_test.txt', dtype=float)
|
||||
print(data_test)
|
||||
```
|
||||
|
||||
**АЕ1**
|
||||
```python
|
||||
predicted_labels1, ire1 = lib.predict_ae(ae1_trained, data_test, IREth1)
|
||||
```
|
||||
|
||||
```python
|
||||
lib.anomaly_detection_ae(predicted_labels1, ire1, IREth1)
|
||||
lib.ire_plot('test', ire1, IREth1, 'AE1')
|
||||
```
|
||||
|
||||
Аномалий не обнаружено
|
||||
|
||||
|
||||
|
||||
|
||||
**АЕ2**
|
||||
```python
|
||||
predicted_labels2, ire2 = lib.predict_ae(ae2_trained, data_test, IREth2)
|
||||
```
|
||||
|
||||
```python
|
||||
lib.anomaly_detection_ae(predicted_labels2, ire2, IREth2)
|
||||
lib.ire_plot('test', ire2, IREth2, 'AE2')
|
||||
```
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>i</th>
|
||||
<th>labels</th>
|
||||
<th>IRE</th>
|
||||
<th>IREth</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>0</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.57]</td>
|
||||
<td>0.38</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>1</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.68]</td>
|
||||
<td>0.38</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>2</td>
|
||||
<td>[1.]</td>
|
||||
<td>[1.03]</td>
|
||||
<td>0.38</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>3</td>
|
||||
<td>[1.]</td>
|
||||
<td>[1.04]</td>
|
||||
<td>0.38</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Обнаружено 4.0 аномалий
|
||||
|
||||
|
||||
|
||||
|
||||
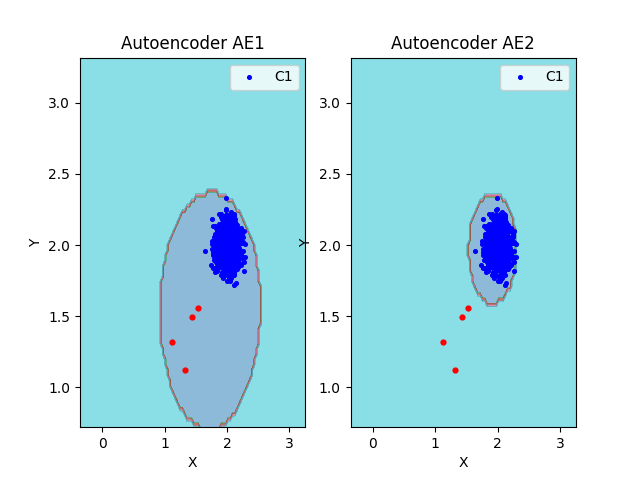
### 10. Визуализация элементов обучающей и тестовой выборки в областях пространства признаков
|
||||
```python
|
||||
lib.plot2in1_anomaly(data, xx, yy, Z1, Z2, data_test)
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 11. Результаты
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th> </th>
|
||||
<th>Количество скрытых слоёв</th>
|
||||
<th>Количество нейронов в скрытых слоях</th>
|
||||
<th>Количество эпох обучения</th>
|
||||
<th>Ошибка MSE_stop</th>
|
||||
<th>Порог ошибки реконструкции</th>
|
||||
<th>Значение показателя Excess</th>
|
||||
<th>Значение показателя Approx</th>
|
||||
<th>Количество обнаруженных аномалий</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>АЕ1</td>
|
||||
<td align="center">1</td>
|
||||
<td align="center">1</td>
|
||||
<td align="center">1000</td>
|
||||
<td align="center">0.1370</td>
|
||||
<td align="center">0.81</td>
|
||||
<td align="center">4.473</td>
|
||||
<td align="center">0.182</td>
|
||||
<td align="center">0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>АЕ2</td>
|
||||
<td align="center">5</td>
|
||||
<td align="center">3 2 1 2 3</td>
|
||||
<td align="center">3000</td>
|
||||
<td align="center">0.0094</td>
|
||||
<td align="center">0.38</td>
|
||||
<td align="center">0.631</td>
|
||||
<td align="center">0.612</td>
|
||||
<td align="center">4</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|
||||
## Задание 2
|
||||
### 1. Изучение набора реальных данных
|
||||
Исходный набор данных Breast Cancer Wisconsin представляет собой набор данных для
|
||||
классификации, в котором записываются измерения для случаев рака молочной железы.
|
||||
Есть два класса, доброкачественные и злокачественные. Злокачественный класс этого
|
||||
набора данных уменьшен до 21 точки, которые считаются аномалиями, в то время как
|
||||
точки в доброкачественном классе считаются нормой
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th> </th>
|
||||
<th>Количество признаков</th>
|
||||
<th>Количество примеров</th>
|
||||
<th>Количество нормальных примеров</th>
|
||||
<th>Количество аномальных примеров</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>АЕ1</td>
|
||||
<td align="center">30</td>
|
||||
<td align="center">378</td>
|
||||
<td align="center">357</td>
|
||||
<td align="center">21</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|
||||
### 2. Загрузка обучающей и тестовой выборок
|
||||
```python
|
||||
train = np.loadtxt('WBC_train.txt', dtype=float)
|
||||
print('train:\n', train)
|
||||
print('train.shape:', np.shape(train))
|
||||
```
|
||||
train:
|
||||
|
||||
[[3.1042643e-01 1.5725397e-01 3.0177597e-01 ... 4.4261168e-01
|
||||
2.7833629e-01 1.1511216e-01]
|
||||
|
||||
[2.8865540e-01 2.0290835e-01 2.8912998e-01 ... 2.5027491e-01
|
||||
3.1914055e-01 1.7571822e-01]
|
||||
|
||||
[1.1940934e-01 9.2323301e-02 1.1436666e-01 ... 2.1398625e-01
|
||||
1.7445299e-01 1.4882592e-01]
|
||||
|
||||
...
|
||||
[3.3456387e-01 5.8978695e-01 3.2886463e-01 ... 3.6013746e-01
|
||||
1.3502858e-01 1.8476978e-01]
|
||||
|
||||
[1.9967817e-01 6.6486304e-01 1.8575081e-01 ... 0.0000000e+00
|
||||
1.9712202e-04 2.6301981e-02]
|
||||
|
||||
[3.6868759e-02 5.0152181e-01 2.8539838e-02 ... 0.0000000e+00
|
||||
2.5744136e-01 1.0068215e-01]]
|
||||
|
||||
train.shape: (357, 30)
|
||||
|
||||
```python
|
||||
test = np.loadtxt('WBC_test.txt', dtype=float)
|
||||
print('\n test:\n', test)
|
||||
print('test.shape:', np.shape(test))
|
||||
```
|
||||
|
||||
test:
|
||||
|
||||
[[0.18784609 0.3936422 0.19425057 0.09654295 0.632572 0.31415251
|
||||
0.24461106 0.28175944 0.42171717 0.3946925 0.04530147 0.23598833
|
||||
0.05018141 0.01899148 0.21589557 0.11557064 0.0655303 0.19643872
|
||||
0.08003602 0.07411246 0.17467094 0.62153518 0.18332586 0.08081007
|
||||
0.79066235 0.23528442 0.32132588 0.48934708 0.2757737 0.26905418]
|
||||
|
||||
[0.71129727 0.41224214 0.71460162 0.56776246 0.48451747 0.53990553
|
||||
0.57357076 0.74602386 0.38585859 0.24094356 0.3246424 0.07507514
|
||||
0.32059558 0.23047901 0.0769963 0.19495599 0.09030303 0.27865126
|
||||
0.10269038 0.10023078 0.70188545 0.36727079 0.72010558 0.50181872
|
||||
0.38453411 0.35044775 0.3798722 0.83573883 0.23181549 0.20136429]
|
||||
|
||||
...
|
||||
|
||||
[0.52103744 0.0226581 0.54598853 0.36373277 0.59375282 0.7920373
|
||||
0.70313964 0.73111332 0.68636364 0.60551811 0.35614702 0.12046941
|
||||
0.3690336 0.27381126 0.15929565 0.35139844 0.13568182 0.30062512
|
||||
0.31164518 0.18304244 0.62077552 0.14152452 0.66831017 0.45069799
|
||||
0.60113584 0.61929156 0.56861022 0.91202749 0.59846245 0.41886396]
|
||||
|
||||
[0.32367836 0.49983091 0.33542948 0.1918982 0.57389185 0.45616833
|
||||
0.31794752 0.33593439 0.61363636 0.47198821 0.13166757 0.25808876
|
||||
0.10446214 0.06023183 0.27082979 0.27268904 0.08777778 0.30611858
|
||||
0.23158102 0.21074997 0.28744219 0.5575693 0.27685642 0.14815179
|
||||
0.71471967 0.35830641 0.27004792 0.52268041 0.41119653 0.41492851]]
|
||||
|
||||
test.shape: (21, 30)
|
||||
|
||||
|
||||
---
|
||||
### 3. Создание и обучение автокодировщика
|
||||
**V1**
|
||||
```python
|
||||
from time import time
|
||||
|
||||
patience = 6500
|
||||
start = time()
|
||||
ae3_v1_trained, IRE3_v1, IREth3_v1 = lib.create_fit_save_ae(train,'out/AE3_V1.h5','out/AE3_v1_ire_th.txt',
|
||||
60000, False, patience, early_stopping_delta = 0.001)
|
||||
print("Время на обучение: ", time() - start)
|
||||
```
|
||||
Параметры: 11 скрытых слоёв; 53 47 43 35 27 13 27 35 43 47 53)
|
||||
```python
|
||||
predicted_labels3_v1, ire3_v1 = lib.predict_ae(ae3_v1_trained, test, IREth3_v1)
|
||||
```
|
||||
```python
|
||||
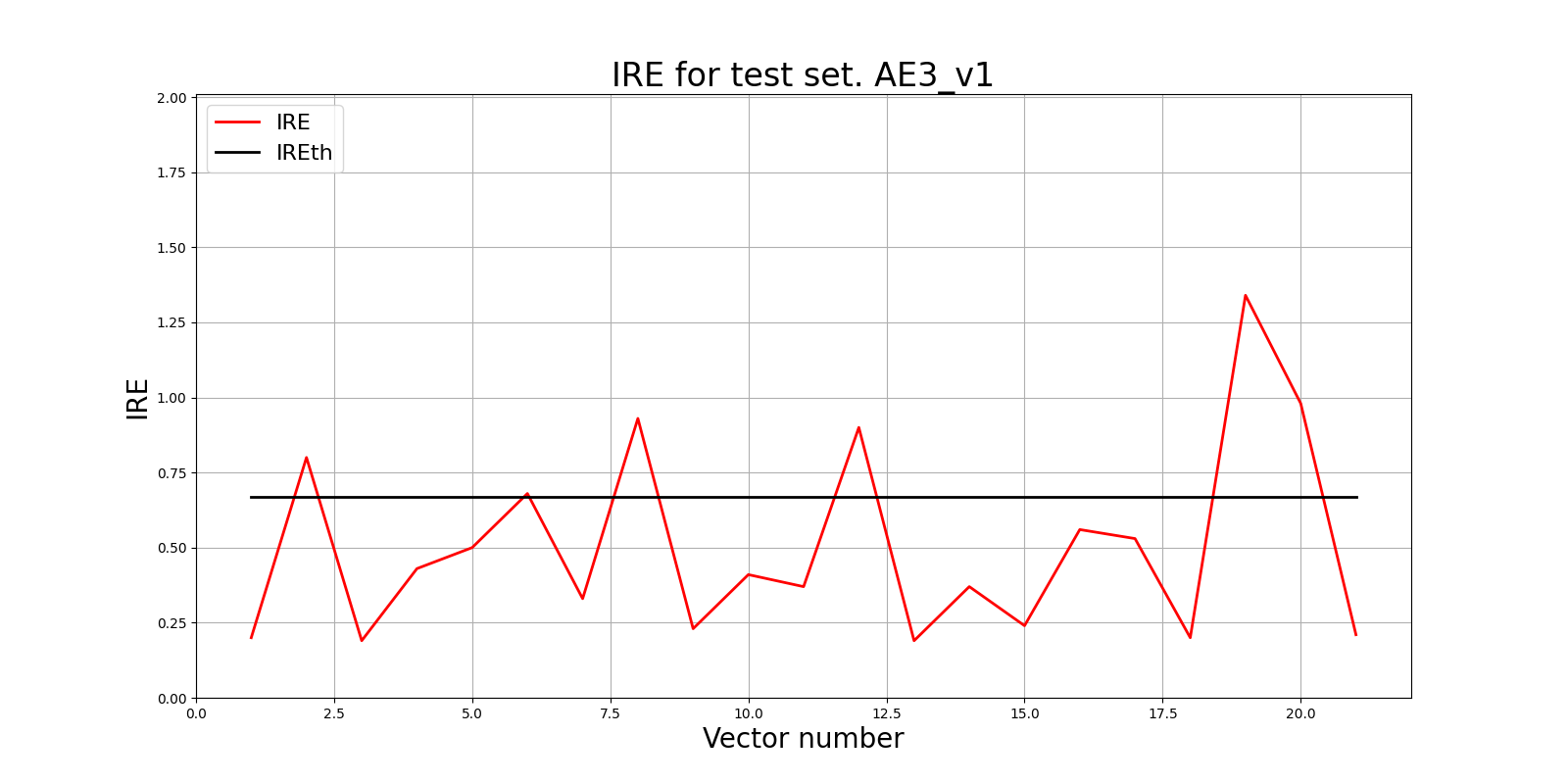
lib.ire_plot('test', ire3_v1, IREth3_v1, 'AE3_v1')
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
```python
|
||||
lib.anomaly_detection_ae(predicted_labels3_v1, IRE3_v1, IREth3_v1)
|
||||
```
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>i</th>
|
||||
<th>labels</th>
|
||||
<th>IRE</th>
|
||||
<th>IREth</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>0</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.09]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>1</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.14]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>2</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.14]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>3</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.21]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>4</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.11]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>5</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.18]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>6</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.13]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>7</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.14]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>8</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.11]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>9</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.1]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>10</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.14]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>11</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.15]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>12</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.19]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>13</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.15]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>14</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.19]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>15</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.21]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>16</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.09]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>17</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.13]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>18</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.55]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>19</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.16]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>20</td>
|
||||
<td>[1.]</td>
|
||||
<td>[1.38]</td>
|
||||
<td>0.67</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Обнаружено 6.0 аномалий
|
||||
|
||||
|
||||
**V2**
|
||||
```python
|
||||
from time import time
|
||||
patience = 5000
|
||||
start = time()
|
||||
ae3_v2_trained, IRE3_v2, IREth3_v2 = lib.create_fit_save_ae(train,'out/AE3_V2.h5','out/AE3_v2_ire_th.txt',
|
||||
50000, False, patience, early_stopping_delta = 0.001)
|
||||
print("Время на обучение: ", time() - start)
|
||||
```
|
||||
Параметры: 9 скрытых слоёв; 37 29 21 15 7 15 21 29 37)
|
||||
```python
|
||||
predicted_labels3_v2, ire3_v2 = lib.predict_ae(ae3_v2_trained, test, IREth3_v2)
|
||||
```
|
||||
```python
|
||||
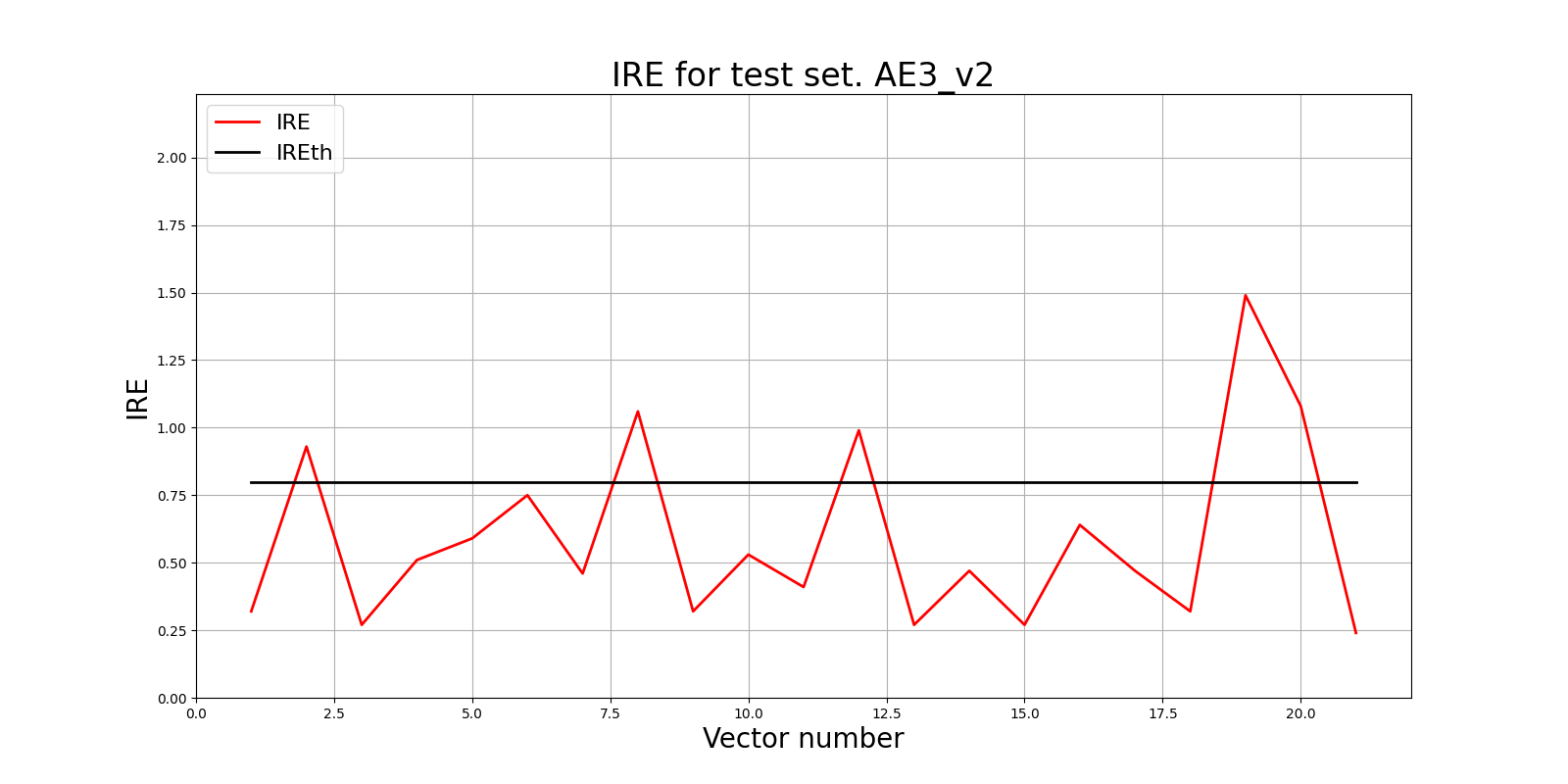
lib.ire_plot('test', ire3_v2, IREth3_v2, 'AE3_v2')
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
```python
|
||||
lib.anomaly_detection_ae(predicted_labels3_v2, IRE3_v2, IREth3_v2)
|
||||
```
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>i</th>
|
||||
<th>labels</th>
|
||||
<th>IRE</th>
|
||||
<th>IREth</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>0</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.2]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>1</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.22]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>2</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.16]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>3</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.3]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>4</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.13]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>5</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.2]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>6</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.17]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>7</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.15]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>8</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.14]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>9</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.15]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>10</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.17]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>11</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.14]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>12</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.22]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>13</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.25]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>14</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.24]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>15</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.29]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>16</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.09]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>17</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.21]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>18</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.69]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>19</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.16]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>20</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.56]</td>
|
||||
<td>0.8</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Обнаружено 5.0 аномалий
|
||||
|
||||
|
||||
**V3**
|
||||
```python
|
||||
from time import time
|
||||
patience = 5500
|
||||
start = time()
|
||||
ae3_v3_trained, IRE3_v3, IREth3_v3 = lib.create_fit_save_ae(train,'out/AE3_V3.h5','out/AE3_v3_ire_th.txt',
|
||||
50000, False, patience, early_stopping_delta = 0.0001)
|
||||
print("Время на обучение: ", time() - start)
|
||||
```
|
||||
Параметры: 9 скрытых слоёв; 30 25 20 15 7 15 20 25 30)
|
||||
|
||||
```python
|
||||
predicted_labels3_v3, ire3_v3 = lib.predict_ae(ae3_v3_trained, test, IREth3_v3)
|
||||
```
|
||||
|
||||
```python
|
||||
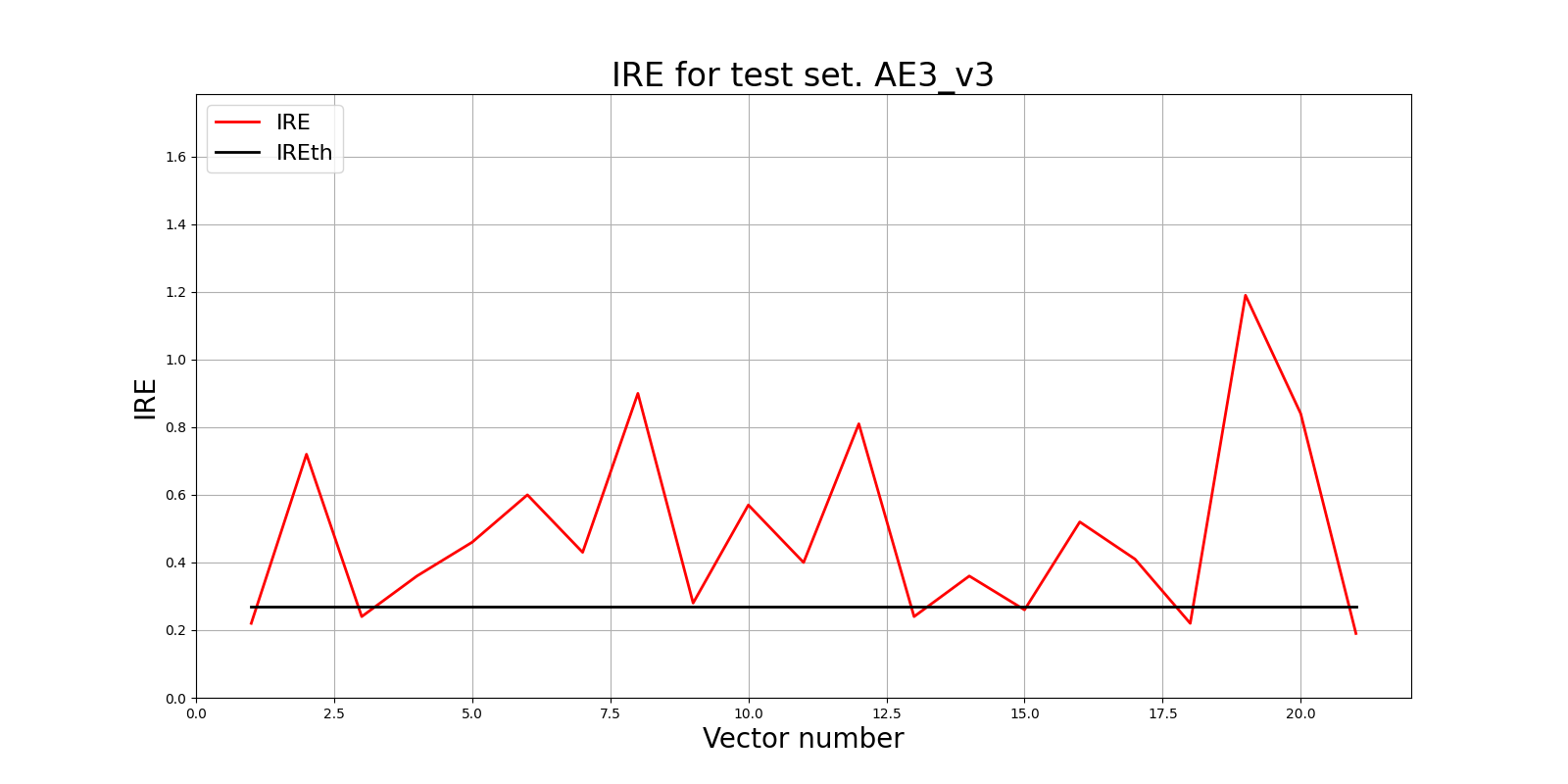
lib.ire_plot('test', ire3_v3, IREth3_v3, 'AE3_v3')
|
||||
```
|
||||
|
||||
|
||||
|
||||
```python
|
||||
lib.anomaly_detection_ae(predicted_labels3_v3, IRE3_v3, IREth3_v3)
|
||||
```
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>i</th>
|
||||
<th>labels</th>
|
||||
<th>IRE</th>
|
||||
<th>IREth</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>0</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.08]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>1</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.11]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>2</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.13]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>3</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.17]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>4</td>
|
||||
<td>[.]</td>
|
||||
<td>[0.13]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>5</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.18]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>6</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.11]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>7</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.12]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>8</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.11]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>9</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.14]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>10</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.17]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>11</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.12]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>12</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.11]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>13</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.09]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>14</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.23]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>15</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.12]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>16</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.1]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>17</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.14]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>18</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.05]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>19</td>
|
||||
<td>[1.]</td>
|
||||
<td>[0.12]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>20</td>
|
||||
<td>[0.]</td>
|
||||
<td>[0.1]</td>
|
||||
<td>0.27</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Обнаружено 15.0 аномалий
|
||||
|
||||
### 4. Результаты
|
||||
Лучшим автокодировщиком среди представленных, является AE3_V3, т.к. у него точность обнаружения аномалий наиболее высокая - 71.43%
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Dataset Name</th>
|
||||
<th>Количество скрытых слоёв</th>
|
||||
<th>Количество нейронов в скрытых слоях</th>
|
||||
<th>Количество эпох обучения</th>
|
||||
<th>Ошибка MSE_stop</th>
|
||||
<th>Порог ошибки реконструкции</th>
|
||||
<th>Процент обнаруженных аномалий</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center">WBC</td>
|
||||
<td align="center">11</td>
|
||||
<td align="center">53 47 43 35 27 13 27 35 43 47 53</td>
|
||||
<td align="center">60 000</td>
|
||||
<td align="center">0.001</td>
|
||||
<td align="center">0.67</td>
|
||||
<td align="center">28.57</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">WBC</td>
|
||||
<td align="center">9</td>
|
||||
<td align="center">37 29 21 15 7 15 21 29 37</td>
|
||||
<td align="center">50 000</td>
|
||||
<td align="center">0.0007</td>
|
||||
<td align="center">0.8</td>
|
||||
<td align="center">23.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">WBC</td>
|
||||
<td align="center">9</td>
|
||||
<td align="center">30 25 20 15 7 15 20 25 30</td>
|
||||
<td align="center">50 000</td>
|
||||
<td align="center">0.0005</td>
|
||||
<td align="center">0.27</td>
|
||||
<td align="center">71.43</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|
||||
### ВЫВОДЫ
|
||||
1) Так как мы работаем с автокодировщиком, данные для его обучения должны быть без аномалий: автокодировщик должен суметь рассчитать верное пороговое значение.
|
||||
2) Архитектура автокодировщика представляет из себя многослойную архитектуру с сужением в середине, а также совпадающее количество входов и выходов
|
||||
|
||||
В первой части работы:
|
||||
|
||||
Оптимальным количеством скрытых слоев для нашего автокодировщика будет 5. Лучшие результаты показываются при количестве эпох - 3000 с patience в 100 эпох
|
||||
1) Оптимальная ошибка MSE-stop должна быть в районе 0.01, в идеале не меньше - для предотвращения переобучения. В этой работе она равна 0.0094
|
||||
2) Значение порога ошибки реконструкции приблизительно равно 0.38
|
||||
3) Значение Excess равно 0.631 (стремится к 0), значение Approx равно 0.612 (стремится к 1), количество определенных аномалий - 4, - эти результаты лучше, чем при более простой архитектуре
|
||||
|
||||
Во второй части работы:
|
||||
Сравнив разные архитектуры при работе с выборкой WBC, делаем выводы,что при неизменном количестве эпох наилучший результат показывает автокодировщик с наименьшими ошибкой MSE, порогом ошибки реконструкции и колчиеством нейронов в скрытом слое. Причинами таких результатов являются:
|
||||
1) При слишком высоком пороге ошибки реконструкции часть ошибок "ускользает" от автокодировщика, он не распознаёт аномалии с малой ошибкой - модель стала "консервативной"
|
||||
2) При большой ошибке MSE - модель недостаточно хорошо выучила нормальные данные
|
||||
3) При слишком большом количестве нейронов модель становится слишком сложной, она "зазубривает" данные, а не учится распознавать закономерности
|
||||
{kind=link}
|
После Ширина: | Высота: | Размер: 71 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 84 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 61 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 75 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 44 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 7.2 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 7.0 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 6.3 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 6.3 KiB |
@ -0,0 +1,880 @@
|
||||
# Отчёт по лабораторной работе №3
|
||||
## по теме: "Распознавание изображений"
|
||||
|
||||
---
|
||||
Выполнили: Бригада 2, Мачулина Д.В., Бирюкова А.С., А-02-22
|
||||
---
|
||||
|
||||
## Задание 1
|
||||
### 1. Создание блокнота и настройка среды
|
||||
|
||||
```python
|
||||
from google.colab import drive
|
||||
drive.mount('/content/drive')
|
||||
import os
|
||||
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab3')
|
||||
|
||||
from tensorflow import keras
|
||||
from tensorflow.keras import layers
|
||||
from tensorflow.keras.models import Sequential
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
from sklearn.metrics import classification_report, confusion_matrix
|
||||
from sklearn.metrics import ConfusionMatrixDisplay
|
||||
```
|
||||
|
||||
---
|
||||
### 2. Загрузка набора данных MNIST
|
||||
|
||||
```python
|
||||
from keras.datasets import mnist
|
||||
(X_train, y_train), (X_test, y_test) = mnist.load_data()
|
||||
```
|
||||
|
||||
---
|
||||
### 3. Разбиение набора данных на общучающие и тестовые (номер бригады - 2)
|
||||
```python
|
||||
from sklearn.model_selection import train_test_split
|
||||
|
||||
# объединяем в один набор
|
||||
X = np.concatenate((X_train, X_test))
|
||||
y = np.concatenate((y_train, y_test))
|
||||
|
||||
# разбиваем по вариантам
|
||||
X_train, X_test, y_train, y_test = train_test_split(X, y,
|
||||
test_size = 10000,
|
||||
train_size = 60000,
|
||||
random_state = 7)
|
||||
# вывод размерностей
|
||||
print('Shape of X train:', X_train.shape)
|
||||
print('Shape of y train:', y_train.shape)
|
||||
print('Shape of X test:', X_test.shape)
|
||||
print('Shape of y test:', y_test.shape)
|
||||
```
|
||||
Shape of X train: (60000, 28, 28)
|
||||
|
||||
Shape of y train: (60000,)
|
||||
|
||||
Shape of X test: (10000, 28, 28)
|
||||
|
||||
Shape of y test: (10000,)
|
||||
|
||||
---
|
||||
### 4. Предобработка данных
|
||||
|
||||
```python
|
||||
# Зададим параметры данных и модели
|
||||
num_classes = 10
|
||||
input_shape = (28, 28, 1)
|
||||
|
||||
# Приведение входных данных к диапазону [0, 1]
|
||||
X_train = X_train / 255
|
||||
X_test = X_test / 255
|
||||
|
||||
# Расширяем размерность входных данных, чтобы каждое изображение имело размерность (высота, ширина, количество каналов)
|
||||
X_train = np.expand_dims(X_train, -1)
|
||||
X_test = np.expand_dims(X_test, -1)
|
||||
print('Shape of transformed X train:', X_train.shape)
|
||||
print('Shape of transformed X test:', X_test.shape)
|
||||
|
||||
# переведем метки в one-hot
|
||||
y_train = keras.utils.to_categorical(y_train, num_classes)
|
||||
y_test = keras.utils.to_categorical(y_test, num_classes)
|
||||
print('Shape of transformed y train:', y_train.shape)
|
||||
print('Shape of transformed y test:', y_test.shape)
|
||||
```
|
||||
Shape of transformed X train: (60000, 28, 28, 1)
|
||||
|
||||
hape of transformed X test: (10000, 28, 28, 1)
|
||||
|
||||
Shape of transformed y train: (60000, 10)
|
||||
|
||||
|
||||
Shape of transformed y test: (10000, 10)
|
||||
|
||||
---
|
||||
### 5. Реализация и обучение модели свёрточной нейронной сети
|
||||
```python
|
||||
# создаем модель
|
||||
model = Sequential()
|
||||
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape))
|
||||
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
||||
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
|
||||
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
||||
model.add(layers.Dropout(0.5))
|
||||
model.add(layers.Flatten())
|
||||
model.add(layers.Dense(num_classes, activation="softmax"))
|
||||
|
||||
model.summary()
|
||||
```
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Layer (type)</th>
|
||||
<th>Output Shape</th>
|
||||
<th>Param #</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>conv2d (Conv2D)</td>
|
||||
<td>(None, 26, 26, 32)</td>
|
||||
<td> 320 </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>max_pooling2d (MaxPooling2D)</td>
|
||||
<td>(None, 13, 13, 32) </td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>conv2d_1 (Conv2D) </td>
|
||||
<td>(None, 11, 11, 64) </td>
|
||||
<td>18,496</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>max_pooling2d_1 (MaxPooling2D)</td>
|
||||
<td>(None, 5, 5, 64)</td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>dropout (Dropout)</td>
|
||||
<td>(None, 5, 5, 64)</td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>flatten (Flatten) </td>
|
||||
<td>(None, 1600)</td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>dense (Dense)</td>
|
||||
<td>(None, 10)</td>
|
||||
<td>16,010</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Total params: 34,826 (136.04 KB)
|
||||
|
||||
Trainable params: 34,826 (136.04 KB)
|
||||
|
||||
Non-trainable params: 0 (0.00 B)
|
||||
|
||||
```python
|
||||
# компилируем и обучаем модель
|
||||
batch_size = 512
|
||||
epochs = 15
|
||||
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
|
||||
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
|
||||
```
|
||||
|
||||
---
|
||||
### 6. Оценка качества обучения на тестовых данных
|
||||
```python
|
||||
scores = model.evaluate(X_test, y_test)
|
||||
print('Loss on test data:', scores[0])
|
||||
print('Accuracy on test data:', scores[1])
|
||||
```
|
||||
Loss on test data: 0.04353996366262436
|
||||
|
||||
Accuracy on test data: 0.9876000285148621
|
||||
|
||||
---
|
||||
### 7. Подача на вход обученной модели тестовых изображений
|
||||
```python
|
||||
# вывод тестового изображения и результата распознавания
|
||||
n = 333
|
||||
result = model.predict(X_test[n:n+1])
|
||||
print('NN output:', result)
|
||||
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
print('Real mark: ', np.argmax(y_test[n]))
|
||||
print('NN answer: ', np.argmax(result))
|
||||
```
|
||||
|
||||

|
||||
|
||||
Real mark: 3
|
||||
|
||||
NN answer: 3
|
||||
|
||||
```python
|
||||
# вывод тестового изображения и результата распознавания
|
||||
n = 222
|
||||
result = model.predict(X_test[n:n+1])
|
||||
print('NN output:', result)
|
||||
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
print('Real mark: ', np.argmax(y_test[n]))
|
||||
print('NN answer: ', np.argmax(result))
|
||||
```
|
||||
|
||||
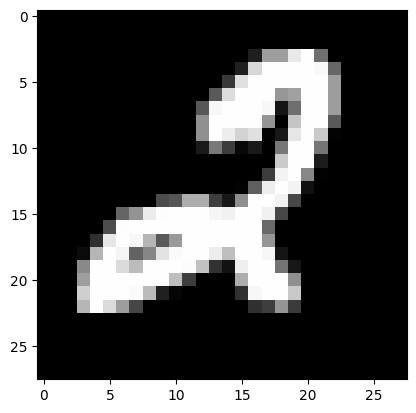
|
||||
|
||||
Real mark: 2
|
||||
|
||||
NN answer: 2
|
||||
|
||||
---
|
||||
### 8. Вывод отчёта о качестве классификации тестовой выборки и матрицы ошибок для тестовой выборки
|
||||
```python
|
||||
# истинные метки классов
|
||||
true_labels = np.argmax(y_test, axis=1)
|
||||
|
||||
# предсказанные метки классов
|
||||
predicted_labels = np.argmax(model.predict(X_test), axis=1)
|
||||
|
||||
# отчет о качестве классификации
|
||||
print(classification_report(true_labels, predicted_labels))
|
||||
|
||||
# вычисление матрицы ошибок
|
||||
conf_matrix = confusion_matrix(true_labels, predicted_labels)
|
||||
|
||||
# отрисовка матрицы ошибок в виде "тепловой карты"
|
||||
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix)
|
||||
display.plot()
|
||||
plt.show()
|
||||
```
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>№(type)</th>
|
||||
<th>precision</th>
|
||||
<th>recall</th>
|
||||
<th>f1-score</th>
|
||||
<th>support</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>0</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>968</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>1</td>
|
||||
<td>1.00</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>1087</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>2</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>1000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>3</td>
|
||||
<td>0.99</td>
|
||||
<td>0.98</td>
|
||||
<td>0.99</td>
|
||||
<td>1039</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>4</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>966</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>5</td>
|
||||
<td>0.98</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>908</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>6</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>972</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>7</td>
|
||||
<td>0.98</td>
|
||||
<td>0.99</td>
|
||||
<td>0.98</td>
|
||||
<td>1060</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>8</td>
|
||||
<td>0.98</td>
|
||||
<td>0.98</td>
|
||||
<td>0.98</td>
|
||||
<td>1015</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>9</td>
|
||||
<td>0.98</td>
|
||||
<td>0.98</td>
|
||||
<td>0.98</td>
|
||||
<td>985</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td colspan = 5></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>accuracy</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td>0.99</td>
|
||||
<td>10000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>macro avg</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>10000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>weighted avg</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>0.99</td>
|
||||
<td>10000</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|
||||
|
||||
---
|
||||
### 9. Загрузка, предобработка и подача собственных изображения
|
||||
```python
|
||||
# загрузка собственного изображения
|
||||
from PIL import Image
|
||||
file_data = Image.open('7.png')
|
||||
file_data = file_data.convert('L') # перевод в градации серого
|
||||
test_img = np.array(file_data)
|
||||
|
||||
# вывод собственного изображения
|
||||
plt.imshow(test_img, cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
|
||||
# предобработка
|
||||
test_img = test_img / 255
|
||||
test_img = np.reshape(test_img, (1,28,28,1))
|
||||
|
||||
# распознавание
|
||||
result = model.predict(test_img)
|
||||
print('I think it\'s ', np.argmax(result))
|
||||
```
|
||||
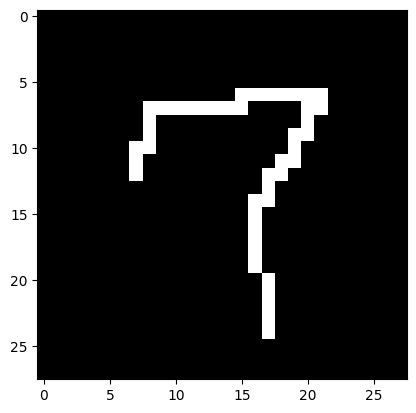
|
||||
|
||||
I think it's 7
|
||||
|
||||
```python
|
||||
# загрузка собственного изображения
|
||||
from PIL import Image
|
||||
file_data = Image.open('5.png')
|
||||
file_data = file_data.convert('L') # перевод в градации серого
|
||||
test_img = np.array(file_data)
|
||||
# вывод собственного изображения
|
||||
plt.imshow(test_img, cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
# предобработка
|
||||
test_img = test_img / 255
|
||||
test_img = np.reshape(test_img, (1,28,28,1))
|
||||
# распознавание
|
||||
result = model.predict(test_img)
|
||||
print('I think it\'s ', np.argmax(result))
|
||||
```
|
||||

|
||||
|
||||
I think it's 5
|
||||
|
||||
---
|
||||
### 10. Загрузка модели из ЛР1. Оценка качества
|
||||
```python
|
||||
model = keras.models.load_model("best_model.keras")
|
||||
model.summary()
|
||||
```
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Layer (type)</th>
|
||||
<th>Output Shape</th>
|
||||
<th>Param #</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>dense_4 (Dense)</td>
|
||||
<td>(None, 300)</td>
|
||||
<td>235,500</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>dense_5 (Dense)</td>
|
||||
<td>(None, 10)</td>
|
||||
<td>3,010</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Total params: 238,512 (931.69 KB)
|
||||
Trainable params: 238,510 (931.68 KB)
|
||||
Non-trainable params: 0 (0.00 B)
|
||||
Optimizer params: 2 (12.00 B)
|
||||
|
||||
|
||||
```python
|
||||
# развернем каждое изображение 28*28 в вектор 784
|
||||
X_train, X_test, y_train, y_test = train_test_split(X, y,
|
||||
test_size = 10000,
|
||||
train_size = 60000,
|
||||
random_state = 7)
|
||||
num_pixels = X_train.shape[1] * X_train.shape[2]
|
||||
X_train = X_train.reshape(X_train.shape[0], num_pixels) / 255
|
||||
X_test = X_test.reshape(X_test.shape[0], num_pixels) / 255
|
||||
print('Shape of transformed X train:', X_train.shape)
|
||||
print('Shape of transformed X train:', X_test.shape)
|
||||
|
||||
# переведем метки в one-hot
|
||||
y_train = keras.utils.to_categorical(y_train, num_classes)
|
||||
y_test = keras.utils.to_categorical(y_test, num_classes)
|
||||
print('Shape of transformed y train:', y_train.shape)
|
||||
print('Shape of transformed y test:', y_test.shape)
|
||||
```
|
||||
Shape of transformed X train: (60000, 784)
|
||||
Shape of transformed X train: (10000, 784)
|
||||
Shape of transformed y train: (60000, 10)
|
||||
Shape of transformed y test: (10000, 10)
|
||||
|
||||
```python
|
||||
# Оценка качества работы модели на тестовых данных
|
||||
scores = model.evaluate(X_test, y_test)
|
||||
print('Loss on test data:', scores[0])
|
||||
print('Accuracy on test data:', scores[1])
|
||||
```
|
||||
Loss on test data: 0.37091827392578125
|
||||
|
||||
Accuracy on test data: 0.9013000130653381
|
||||
|
||||
---
|
||||
### 11. Сравнение обученной модели сверточной сети и наилучшей модели полносвязной сети
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Модель</th>
|
||||
<th>Количество настраиваемых параметров сети</th>
|
||||
<th>Количество эпох обучения</th>
|
||||
<th>Качество классификации тестовой выборки</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th>Сверточная</th>
|
||||
<td align="center">34,826</td>
|
||||
<td align="center">15</td>
|
||||
<td align="center">0.9876</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>Полносвязная</th>
|
||||
<td align="center">238,512</td>
|
||||
<td align="center">100</td>
|
||||
<td align="center">0.9013</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Вывод: В ходе лабораторной работы были получены результаты, представленные в таблице. Исходя из них можно сделать вывод, что свёрточная нейронная сеть подходит для задачи распознавания изображений гораздо лучше, чем полносвязная. Для качества классификации 0,9876 понадобилось всего 15 эпох обучения и 35 настраиваемых параметров сети против качества в 0,9013, 100 эпох и 239 параметров для полносвязной сети.
|
||||
|
||||
|
||||
## Задание 2
|
||||
### В новом блокноте выполнили п.1-8 задания 1, изменив набор данных MNIST на CIFAR-10
|
||||
### 1. Создание блокнота и настройка среды
|
||||
```python
|
||||
from google.colab import drive
|
||||
drive.mount('/content/drive')
|
||||
import os
|
||||
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab3')
|
||||
|
||||
from tensorflow import keras
|
||||
from tensorflow.keras.models import Sequential
|
||||
from tensorflow.keras import layers
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
from sklearn.metrics import classification_report, confusion_matrix
|
||||
from sklearn.metrics import ConfusionMatrixDisplay
|
||||
```
|
||||
|
||||
### 2.Загрузка набора данных и его разбиение на ообучащие и тестовые
|
||||
```python
|
||||
# загрузка датасета
|
||||
from keras.datasets import cifar10
|
||||
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
|
||||
```
|
||||
|
||||
```python
|
||||
# создание своего разбиения датасета
|
||||
from sklearn.model_selection import train_test_split
|
||||
|
||||
# объединяем в один набор
|
||||
X = np.concatenate((X_train, X_test))
|
||||
y = np.concatenate((y_train, y_test))
|
||||
|
||||
# разбиваем по вариантам
|
||||
X_train, X_test, y_train, y_test = train_test_split(X, y,
|
||||
test_size = 10000,
|
||||
train_size = 50000,
|
||||
random_state = 7)
|
||||
# вывод размерностей
|
||||
print('Shape of X train:', X_train.shape)
|
||||
print('Shape of y train:', y_train.shape)
|
||||
print('Shape of X test:', X_test.shape)
|
||||
print('Shape of y test:', y_test.shape)
|
||||
```
|
||||
Shape of X train: (50000, 32, 32, 3)
|
||||
|
||||
Shape of y train: (50000, 1)
|
||||
|
||||
Shape of X test: (10000, 32, 32, 3)
|
||||
|
||||
Shape of y test: (10000, 1)
|
||||
|
||||
### 3. Вывод изображений с подписями классов
|
||||
```python
|
||||
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
|
||||
'dog', 'frog', 'horse', 'ship', 'truck']
|
||||
plt.figure(figsize=(10,10))
|
||||
for i in range(25):
|
||||
plt.subplot(5,5,i+1)
|
||||
plt.xticks([])
|
||||
plt.yticks([])
|
||||
plt.grid(False)
|
||||
plt.imshow(X_train[i])
|
||||
plt.xlabel(class_names[y_train[i][0]])
|
||||
plt.show()
|
||||
```
|
||||
|
||||
|
||||
### 4. Предобработка данных
|
||||
```python
|
||||
# Зададим параметры данных и модели
|
||||
num_classes = 10
|
||||
input_shape = (32, 32, 3)
|
||||
|
||||
# Приведение входных данных к диапазону [0, 1]
|
||||
X_train = X_train / 255
|
||||
X_test = X_test / 255
|
||||
|
||||
print('Shape of transformed X train:', X_train.shape)
|
||||
print('Shape of transformed X test:', X_test.shape)
|
||||
|
||||
# переведем метки в one-hot
|
||||
y_train = keras.utils.to_categorical(y_train, num_classes)
|
||||
y_test = keras.utils.to_categorical(y_test, num_classes)
|
||||
print('Shape of transformed y train:', y_train.shape)
|
||||
print('Shape of transformed y test:', y_test.shape)
|
||||
```
|
||||
Shape of transformed X train: (50000, 32, 32, 3)
|
||||
Shape of transformed X test: (10000, 32, 32, 3)
|
||||
Shape of transformed y train: (50000, 10)
|
||||
Shape of transformed y test: (10000, 10)
|
||||
|
||||
---
|
||||
### 5. Реализация и обучение модели свёрточной нейронной сети
|
||||
```python
|
||||
# создаем модель
|
||||
model = Sequential()
|
||||
|
||||
# Блок 1
|
||||
model.add(layers.Conv2D(32, (3, 3), padding="same",
|
||||
activation="relu", input_shape=input_shape))
|
||||
model.add(layers.BatchNormalization())
|
||||
model.add(layers.Conv2D(32, (3, 3), padding="same", activation="relu"))
|
||||
model.add(layers.BatchNormalization())
|
||||
model.add(layers.MaxPooling2D((2, 2)))
|
||||
model.add(layers.Dropout(0.25))
|
||||
|
||||
# Блок 2
|
||||
model.add(layers.Conv2D(64, (3, 3), padding="same", activation="relu"))
|
||||
model.add(layers.BatchNormalization())
|
||||
model.add(layers.Conv2D(64, (3, 3), padding="same", activation="relu"))
|
||||
model.add(layers.BatchNormalization())
|
||||
model.add(layers.MaxPooling2D((2, 2)))
|
||||
model.add(layers.Dropout(0.25))
|
||||
|
||||
model.add(layers.Flatten())
|
||||
model.add(layers.Dense(128, activation='relu'))
|
||||
model.add(layers.Dropout(0.5))
|
||||
model.add(layers.Dense(num_classes, activation="softmax"))
|
||||
|
||||
|
||||
model.summary()
|
||||
```
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Layer (type)</th>
|
||||
<th>Output Shape</th>
|
||||
<th>Param #</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>conv2d (Conv2D)</td>
|
||||
<td>(None, 32, 32, 32)</td>
|
||||
<td>896</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>batch_normalization_6 (BatchNormalization)</td>
|
||||
<td>(None, 32, 32, 32) </td>
|
||||
<td>128</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>conv2d_13 (Conv2D)</td>
|
||||
<td>(None, 32, 32, 32)</td>
|
||||
<td>9,248</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>batch_normalization_7 (BatchNormalization)</td>
|
||||
<td>(None, 32, 32, 32)</td>
|
||||
<td>128</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>max_pooling2d_9 (MaxPooling2D)</td>
|
||||
<td>(None, 16, 16, 32)</td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>dropout_6 (Dropout)</td>
|
||||
<td>(None, 16, 16, 32)</td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>conv2d_14 (Conv2D)</td>
|
||||
<td>(None, 16, 16, 64)</td>
|
||||
<td>18,496</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>batch_normalization_8 (BatchNormalization)</td>
|
||||
<td>(None, 16, 16, 64)</td>
|
||||
<td>256</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>conv2d_15 (Conv2D)</td>
|
||||
<td>(None, 16, 16, 64)</td>
|
||||
<td>32,928</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>batch_normalization_9 (BatchNormalization)</td>
|
||||
<td>(None, 16, 16, 64)</td>
|
||||
<td>256</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>max_pooling2d_10 (MaxPooling2D)</td>
|
||||
<td>(None, 8, 8, 64)</td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>dropout_7 (Dropout)</td>
|
||||
<td>(None, 8, 8, 64)</td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>flatten_3 (Flatten) </td>
|
||||
<td>(None, 4096)</td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>dense_6 (Dense)</td>
|
||||
<td>(None, 128)</td>
|
||||
<td>524,416</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>dropout_8 (Dropout)</td>
|
||||
<td>(None, 128)</td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>dense_7 (Dense)</td>
|
||||
<td>(None, 10)</td>
|
||||
<td>1,290</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
Total params: 592,042 (2.26 MB)
|
||||
Trainable params: 591,658 (2.26 MB)
|
||||
Non-trainable params: 384 (1.50 KB)
|
||||
|
||||
```python
|
||||
batch_size = 64
|
||||
epochs = 50
|
||||
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
|
||||
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
|
||||
```
|
||||
|
||||
### 6. Оценка качества обучения на тестовых данных
|
||||
```python
|
||||
scores = model.evaluate(X_test, y_test)
|
||||
print('Loss on test data:', scores[0])
|
||||
print('Accuracy on test data:', scores[1])
|
||||
```
|
||||
|
||||
---
|
||||
### 7. Подача на вход обученной модели тестовых изображений
|
||||
```python
|
||||
for n in [5,17]:
|
||||
result = model.predict(X_test[n:n+1])
|
||||
print('NN output:', result)
|
||||
|
||||
plt.imshow(X_test[n].reshape(32,32,3), cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
print('Real mark: ', np.argmax(y_test[n]))
|
||||
print('NN answer: ', np.argmax(result))
|
||||
```
|
||||
|
||||
|
||||
Real mark: 0
|
||||
|
||||
NN answer: 2
|
||||
|
||||

|
||||
|
||||
Real mark: 5
|
||||
|
||||
NN answer: 5
|
||||
|
||||
---
|
||||
### 8. Вывод отчёта о качестве классификации тестовой выборки и матрицы ошибок для тестовой выборки
|
||||
```python
|
||||
# истинные метки классов
|
||||
true_labels = np.argmax(y_test, axis=1)
|
||||
|
||||
# предсказанные метки классов
|
||||
predicted_labels = np.argmax(model.predict(X_test), axis=1)
|
||||
|
||||
# отчет о качестве классификации
|
||||
print(classification_report(true_labels, predicted_labels, target_names=class_names))
|
||||
|
||||
# вычисление матрицы ошибок
|
||||
conf_matrix = confusion_matrix(true_labels, predicted_labels)
|
||||
|
||||
# отрисовка матрицы ошибок в виде "тепловой карты"
|
||||
fig, ax = plt.subplots(figsize=(6, 6))
|
||||
disp = ConfusionMatrixDisplay(confusion_matrix=conf_matrix,display_labels=class_names)
|
||||
disp.plot(ax=ax, xticks_rotation=45) # поворот подписей по X и приятная палитра
|
||||
plt.tight_layout() # чтобы всё влезло
|
||||
plt.show()
|
||||
```
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>class</th>
|
||||
<th>precision</th>
|
||||
<th>recall</th>
|
||||
<th>f1-score</th>
|
||||
<th>support</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>airplane</td>
|
||||
<td>0.85</td>
|
||||
<td>0.86</td>
|
||||
<td>0.86</td>
|
||||
<td>1013</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>automobile</td>
|
||||
<td>0.93</td>
|
||||
<td>0.91</td>
|
||||
<td>0.92</td>
|
||||
<td>989</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>bird</td>
|
||||
<td>0.75</td>
|
||||
<td>0.75</td>
|
||||
<td>0.75</td>
|
||||
<td>1018</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>cat</td>
|
||||
<td>0.69</td>
|
||||
<td>0.66</td>
|
||||
<td>0.67</td>
|
||||
<td>1049</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>deer</td>
|
||||
<td>0.79</td>
|
||||
<td>0.78</td>
|
||||
<td>0.78</td>
|
||||
<td>1009</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>dog</td>
|
||||
<td>0.73</td>
|
||||
<td>0.68</td>
|
||||
<td>0.71</td>
|
||||
<td>978</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>frog</td>
|
||||
<td>0.79</td>
|
||||
<td>0.90</td>
|
||||
<td>0.84</td>
|
||||
<td>981</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>horse</td>
|
||||
<td>0.88</td>
|
||||
<td>0.84</td>
|
||||
<td>0.86</td>
|
||||
<td>986</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>ship</td>
|
||||
<td>0.89</td>
|
||||
<td>0.92</td>
|
||||
<td>0.91</td>
|
||||
<td>1029</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>truck</td>
|
||||
<td>0.88</td>
|
||||
<td>0.91</td>
|
||||
<td>0.89</td>
|
||||
<td>948</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td colspan = 5></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>accuracy</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td>0.82</td>
|
||||
<td>10000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>macro avg</td>
|
||||
<td>0.82</td>
|
||||
<td>0.82</td>
|
||||
<td>0.82</td>
|
||||
<td>10000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>weighted avg</td>
|
||||
<td>0.82</td>
|
||||
<td>0.82</td>
|
||||
<td>0.82</td>
|
||||
<td>10000</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|
||||
|
||||
**Вывод**: Заметим, что модель НС, предназначенная для датасета CIFAR-10 неплохо справилась со своей задачей - точность распознавания составила 81%. Однако, несмотря на более сложную структуру модели, точность распознавания оказалась ниже, чем у модели, предназначенной для набора данных MNIST. Это может быть связано с типом классифицируемых данных - распознавать цветные изображения гораздо сложнее, чем чёрно-белые цифры. Для того, чтобы повысить точность распознавания картинок можно и нужно усложнить структуру НС, а именно увеличить количество слоёв и эпох, а также количество примеров (в нашем случае их было 50000)
|
||||
@ -0,0 +1,166 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""IS_LR3
|
||||
|
||||
Automatically generated by Colab.
|
||||
|
||||
Original file is located at
|
||||
https://colab.research.google.com/drive/1nifOoLtBDSMVc5wJUm1l8id2O81rvFXX
|
||||
"""
|
||||
|
||||
from google.colab import drive
|
||||
drive.mount('/content/drive')
|
||||
import os
|
||||
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab3')
|
||||
|
||||
from tensorflow import keras
|
||||
from tensorflow.keras import layers
|
||||
from tensorflow.keras.models import Sequential
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
from sklearn.metrics import classification_report, confusion_matrix
|
||||
from sklearn.metrics import ConfusionMatrixDisplay
|
||||
|
||||
from keras.datasets import mnist
|
||||
(X_train, y_train), (X_test, y_test) = mnist.load_data()
|
||||
|
||||
from sklearn.model_selection import train_test_split
|
||||
|
||||
# объединяем в один набор
|
||||
X = np.concatenate((X_train, X_test))
|
||||
y = np.concatenate((y_train, y_test))
|
||||
|
||||
# разбиваем по вариантам
|
||||
X_train, X_test, y_train, y_test = train_test_split(X, y,
|
||||
test_size = 10000,
|
||||
train_size = 60000,
|
||||
random_state = 7)
|
||||
# вывод размерностей
|
||||
print('Shape of X train:', X_train.shape)
|
||||
print('Shape of y train:', y_train.shape)
|
||||
print('Shape of X test:', X_test.shape)
|
||||
print('Shape of y test:', y_test.shape)
|
||||
|
||||
# Зададим параметры данных и модели
|
||||
num_classes = 10
|
||||
input_shape = (28, 28, 1)
|
||||
|
||||
# Приведение входных данных к диапазону [0, 1]
|
||||
X_train = X_train / 255
|
||||
X_test = X_test / 255
|
||||
|
||||
# Расширяем размерность входных данных, чтобы каждое изображение имело
|
||||
# размерность (высота, ширина, количество каналов)
|
||||
|
||||
X_train = np.expand_dims(X_train, -1)
|
||||
X_test = np.expand_dims(X_test, -1)
|
||||
print('Shape of transformed X train:', X_train.shape)
|
||||
print('Shape of transformed X test:', X_test.shape)
|
||||
|
||||
# переведем метки в one-hot
|
||||
y_train = keras.utils.to_categorical(y_train, num_classes)
|
||||
y_test = keras.utils.to_categorical(y_test, num_classes)
|
||||
print('Shape of transformed y train:', y_train.shape)
|
||||
print('Shape of transformed y test:', y_test.shape)
|
||||
|
||||
# создаем модель
|
||||
model = Sequential()
|
||||
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape))
|
||||
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
||||
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
|
||||
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
||||
model.add(layers.Dropout(0.5))
|
||||
model.add(layers.Flatten())
|
||||
model.add(layers.Dense(num_classes, activation="softmax"))
|
||||
|
||||
model.summary()
|
||||
|
||||
# компилируем и обучаем модель
|
||||
batch_size = 512
|
||||
epochs = 15
|
||||
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
|
||||
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
|
||||
|
||||
# Оценка качества работы модели на тестовых данных
|
||||
scores = model.evaluate(X_test, y_test)
|
||||
print('Loss on test data:', scores[0])
|
||||
print('Accuracy on test data:', scores[1])
|
||||
|
||||
# вывод тестового изображения и результата распознавания
|
||||
for n in [222,333]:
|
||||
result = model.predict(X_test[n:n+1])
|
||||
print('NN output:', result)
|
||||
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
print('Real mark: ', np.argmax(y_test[n]))
|
||||
print('NN answer: ', np.argmax(result))
|
||||
|
||||
# истинные метки классов
|
||||
true_labels = np.argmax(y_test, axis=1)
|
||||
# предсказанные метки классов
|
||||
predicted_labels = np.argmax(model.predict(X_test), axis=1)
|
||||
# отчет о качестве классификации
|
||||
print(classification_report(true_labels, predicted_labels))
|
||||
# вычисление матрицы ошибок
|
||||
conf_matrix = confusion_matrix(true_labels, predicted_labels)
|
||||
# отрисовка матрицы ошибок в виде "тепловой карты"
|
||||
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix)
|
||||
display.plot()
|
||||
plt.show()
|
||||
|
||||
# загрузка собственного изображения
|
||||
from PIL import Image
|
||||
file_data = Image.open('7.png')
|
||||
file_data = file_data.convert('L') # перевод в градации серого
|
||||
test_img = np.array(file_data)
|
||||
# вывод собственного изображения
|
||||
plt.imshow(test_img, cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
# предобработка
|
||||
test_img = test_img / 255
|
||||
test_img = np.reshape(test_img, (1,28,28,1))
|
||||
# распознавание
|
||||
result = model.predict(test_img)
|
||||
print('I think it\'s ', np.argmax(result))
|
||||
|
||||
# загрузка собственного изображения
|
||||
from PIL import Image
|
||||
file_data = Image.open('5.png')
|
||||
file_data = file_data.convert('L') # перевод в градации серого
|
||||
test_img = np.array(file_data)
|
||||
# вывод собственного изображения
|
||||
plt.imshow(test_img, cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
# предобработка
|
||||
test_img = test_img / 255
|
||||
test_img = np.reshape(test_img, (1,28,28,1))
|
||||
# распознавание
|
||||
result = model.predict(test_img)
|
||||
print('I think it\'s ', np.argmax(result))
|
||||
|
||||
model = keras.models.load_model("best_model.keras")
|
||||
model.summary()
|
||||
|
||||
# развернем каждое изображение 28*28 в вектор 784
|
||||
X_train, X_test, y_train, y_test = train_test_split(X, y,
|
||||
test_size = 10000,
|
||||
train_size = 60000,
|
||||
random_state = 7)
|
||||
num_pixels = X_train.shape[1] * X_train.shape[2]
|
||||
X_train = X_train.reshape(X_train.shape[0], num_pixels) / 255
|
||||
X_test = X_test.reshape(X_test.shape[0], num_pixels) / 255
|
||||
print('Shape of transformed X train:', X_train.shape)
|
||||
print('Shape of transformed X train:', X_test.shape)
|
||||
|
||||
# переведем метки в one-hot
|
||||
y_train = keras.utils.to_categorical(y_train, num_classes)
|
||||
y_test = keras.utils.to_categorical(y_test, num_classes)
|
||||
print('Shape of transformed y train:', y_train.shape)
|
||||
print('Shape of transformed y test:', y_test.shape)
|
||||
|
||||
# Оценка качества работы модели на тестовых данных
|
||||
scores = model.evaluate(X_test, y_test)
|
||||
print('Loss on test data:', scores[0])
|
||||
print('Accuracy on test data:', scores[1])
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,135 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""IS_LR3_2
|
||||
|
||||
Automatically generated by Colab.
|
||||
|
||||
Original file is located at
|
||||
https://colab.research.google.com/drive/1ATu8wYdHLgC6dGpFJboJXvIoTohx65eT
|
||||
"""
|
||||
|
||||
from google.colab import drive
|
||||
drive.mount('/content/drive')
|
||||
import os
|
||||
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab3')
|
||||
|
||||
from tensorflow import keras
|
||||
from tensorflow.keras.models import Sequential
|
||||
from tensorflow.keras import layers
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
from sklearn.metrics import classification_report, confusion_matrix
|
||||
from sklearn.metrics import ConfusionMatrixDisplay
|
||||
|
||||
# загрузка датасета
|
||||
from keras.datasets import cifar10
|
||||
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
|
||||
|
||||
# создание своего разбиения датасета
|
||||
from sklearn.model_selection import train_test_split
|
||||
|
||||
|
||||
# объединяем в один набор
|
||||
X = np.concatenate((X_train, X_test))
|
||||
y = np.concatenate((y_train, y_test))
|
||||
|
||||
# разбиваем по вариантам
|
||||
X_train, X_test, y_train, y_test = train_test_split(X, y,
|
||||
test_size = 10000,
|
||||
train_size = 50000,
|
||||
random_state = 7)
|
||||
# вывод размерностей
|
||||
print('Shape of X train:', X_train.shape)
|
||||
print('Shape of y train:', y_train.shape)
|
||||
print('Shape of X test:', X_test.shape)
|
||||
print('Shape of y test:', y_test.shape)
|
||||
|
||||
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
|
||||
'dog', 'frog', 'horse', 'ship', 'truck']
|
||||
plt.figure(figsize=(10,10))
|
||||
for i in range(25):
|
||||
plt.subplot(5,5,i+1)
|
||||
plt.xticks([])
|
||||
plt.yticks([])
|
||||
plt.grid(False)
|
||||
plt.imshow(X_train[i])
|
||||
plt.xlabel(class_names[y_train[i][0]])
|
||||
plt.show()
|
||||
|
||||
# Зададим параметры данных и модели
|
||||
num_classes = 10
|
||||
input_shape = (32, 32, 3)
|
||||
|
||||
# Приведение входных данных к диапазону [0, 1]
|
||||
X_train = X_train / 255
|
||||
X_test = X_test / 255
|
||||
|
||||
print('Shape of transformed X train:', X_train.shape)
|
||||
print('Shape of transformed X test:', X_test.shape)
|
||||
|
||||
# переведем метки в one-hot
|
||||
y_train = keras.utils.to_categorical(y_train, num_classes)
|
||||
y_test = keras.utils.to_categorical(y_test, num_classes)
|
||||
print('Shape of transformed y train:', y_train.shape)
|
||||
print('Shape of transformed y test:', y_test.shape)
|
||||
|
||||
# создаем модель
|
||||
model = Sequential()
|
||||
|
||||
# Блок 1
|
||||
model.add(layers.Conv2D(32, (3, 3), padding="same",
|
||||
activation="relu", input_shape=input_shape))
|
||||
model.add(layers.BatchNormalization())
|
||||
model.add(layers.Conv2D(32, (3, 3), padding="same", activation="relu"))
|
||||
model.add(layers.BatchNormalization())
|
||||
model.add(layers.MaxPooling2D((2, 2)))
|
||||
model.add(layers.Dropout(0.25))
|
||||
|
||||
# Блок 2
|
||||
model.add(layers.Conv2D(64, (3, 3), padding="same", activation="relu"))
|
||||
model.add(layers.BatchNormalization())
|
||||
model.add(layers.Conv2D(64, (3, 3), padding="same", activation="relu"))
|
||||
model.add(layers.BatchNormalization())
|
||||
model.add(layers.MaxPooling2D((2, 2)))
|
||||
model.add(layers.Dropout(0.25))
|
||||
|
||||
model.add(layers.Flatten())
|
||||
model.add(layers.Dense(128, activation='relu'))
|
||||
model.add(layers.Dropout(0.5))
|
||||
model.add(layers.Dense(num_classes, activation="softmax"))
|
||||
|
||||
|
||||
model.summary()
|
||||
|
||||
batch_size = 64
|
||||
epochs = 50
|
||||
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
|
||||
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
|
||||
|
||||
scores = model.evaluate(X_test, y_test)
|
||||
print('Loss on test data:', scores[0])
|
||||
print('Accuracy on test data:', scores[1])
|
||||
|
||||
for n in [5,17]:
|
||||
result = model.predict(X_test[n:n+1])
|
||||
print('NN output:', result)
|
||||
|
||||
plt.imshow(X_test[n].reshape(32,32,3), cmap=plt.get_cmap('gray'))
|
||||
plt.show()
|
||||
print('Real mark: ', np.argmax(y_test[n]))
|
||||
print('NN answer: ', np.argmax(result))
|
||||
|
||||
# истинные метки классов
|
||||
true_labels = np.argmax(y_test, axis=1)
|
||||
# предсказанные метки классов
|
||||
predicted_labels = np.argmax(model.predict(X_test), axis=1)
|
||||
|
||||
# отчет о качестве классификации
|
||||
print(classification_report(true_labels, predicted_labels, target_names=class_names))
|
||||
# вычисление матрицы ошибок
|
||||
conf_matrix = confusion_matrix(true_labels, predicted_labels)
|
||||
# отрисовка матрицы ошибок в виде "тепловой карты"
|
||||
fig, ax = plt.subplots(figsize=(6, 6))
|
||||
disp = ConfusionMatrixDisplay(confusion_matrix=conf_matrix,display_labels=class_names)
|
||||
disp.plot(ax=ax, xticks_rotation=45) # поворот подписей по X и приятная палитра
|
||||
plt.tight_layout() # чтобы всё влезло
|
||||
plt.show()
|
||||
{kind=link}
|
После Ширина: | Высота: | Размер: 12 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 12 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 115 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 32 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 62 KiB |
{kind=link}
|
После Ширина: | Высота: | Размер: 21 KiB |
@ -0,0 +1,150 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""LR4
|
||||
|
||||
Automatically generated by Colab.
|
||||
|
||||
Original file is located at
|
||||
https://colab.research.google.com/drive/1yCiW4PaAoMLkJgUu05TvwmSYoqVG1iyL
|
||||
"""
|
||||
|
||||
import tensorflow as tf
|
||||
device_name = tf.test.gpu_device_name()
|
||||
if device_name != '/device:GPU:0':
|
||||
raise SystemError('GPU device not found')
|
||||
print('Found GPU at: {}'.format(device_name))
|
||||
|
||||
from google.colab import drive
|
||||
drive.mount('/content/drive')
|
||||
import os
|
||||
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab4')
|
||||
|
||||
from tensorflow import keras
|
||||
from tensorflow.keras import layers
|
||||
from tensorflow.keras.models import Sequential
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
from sklearn.metrics import classification_report, confusion_matrix
|
||||
from sklearn.metrics import ConfusionMatrixDisplay
|
||||
|
||||
# загрузка датасета
|
||||
from keras.datasets import imdb
|
||||
vocabulary_size = 5000
|
||||
index_from = 3
|
||||
(X_train, y_train), (X_test, y_test) = imdb.load_data(path="imdb.npz",
|
||||
num_words=vocabulary_size,
|
||||
skip_top=0,
|
||||
maxlen=None,
|
||||
seed=7,
|
||||
start_char=1,
|
||||
oov_char=2,
|
||||
index_from=index_from
|
||||
)
|
||||
print('Shape of X train:', X_train.shape)
|
||||
print('Shape of y train:', y_train.shape)
|
||||
print('Shape of X test:', X_test.shape)
|
||||
print('Shape of y test:', y_test.shape)
|
||||
|
||||
# создание словаря для перевода индексов в слова
|
||||
# заргузка словаря "слово:индекс"
|
||||
word_to_id = imdb.get_word_index()
|
||||
# уточнение словаря
|
||||
word_to_id = {key:(value + index_from) for key,value in word_to_id.items()}
|
||||
word_to_id["<PAD>"] = 0
|
||||
word_to_id["<START>"] = 1
|
||||
word_to_id["<UNK>"] = 2
|
||||
word_to_id["<UNUSED>"] = 3
|
||||
# создание обратного словаря "индекс:слово"
|
||||
id_to_word = {value:key for key,value in word_to_id.items()}
|
||||
|
||||
#Вывод отзыва из обучающего множества в виде списка индексов слов
|
||||
some_number = 192
|
||||
review_indices = X_train[some_number]
|
||||
print("Список индексов слов:")
|
||||
print(review_indices)
|
||||
|
||||
#Преобразование списка индексов в текст
|
||||
review_as_text = ' '.join(id_to_word[id] for id in X_train[some_number])
|
||||
print("\nОтзыв в виде текста:")
|
||||
print(review_as_text)
|
||||
|
||||
#Вывод длины отзыва
|
||||
max_review_length = len(max(X_train, key=len))
|
||||
print(f"\nМаксимальная длина отзыва: {max_review_length}")
|
||||
min_review_length = len(min(X_train, key=len))
|
||||
print(f"\nМинимальная длина отзыва: {min_review_length}")
|
||||
review_length = len(review_indices)
|
||||
print(f"\nДлина отзыва: {review_length}")
|
||||
|
||||
#Вывод метки и названия класса
|
||||
class_label = y_train[some_number]
|
||||
class_name = "Positive" if class_label == 1 else "Negative"
|
||||
print(f"\nМетка класса: {class_label} - {class_name}")
|
||||
|
||||
# предобработка данных
|
||||
from tensorflow.keras.utils import pad_sequences
|
||||
max_words = 500
|
||||
X_train = pad_sequences(X_train, maxlen=max_words, value=0, padding='pre', truncating='post')
|
||||
X_test = pad_sequences(X_test, maxlen=max_words, value=0, padding='pre', truncating='post')
|
||||
|
||||
#Вывод отзыва из обучающего множества в виде списка индексов слов
|
||||
some_number = 192
|
||||
review_indices = X_train[some_number]
|
||||
print("Список индексов слов:")
|
||||
print(review_indices)
|
||||
|
||||
#Преобразование списка индексов в текст
|
||||
review_as_text = ' '.join(id_to_word[id] for id in X_train[some_number])
|
||||
print("\nОтзыв в виде текста:")
|
||||
print(review_as_text)
|
||||
|
||||
#Вывод длины отзыва
|
||||
max_review_length = len(max(X_train, key=len))
|
||||
print(f"\nМаксимальная длина отзыва: {max_review_length}")
|
||||
min_review_length = len(min(X_train, key=len))
|
||||
print(f"\nМинимальная длина отзыва: {min_review_length}")
|
||||
review_length = len(review_indices)
|
||||
print(f"\nДлина отзыва: {review_length}")
|
||||
|
||||
# вывод данных
|
||||
print('X train: \n',X_train)
|
||||
print('X train: \n',X_test)
|
||||
|
||||
# вывод размерностей
|
||||
print('Shape of X train:', X_train.shape)
|
||||
print('Shape of X test:', X_test.shape)
|
||||
|
||||
model = Sequential()
|
||||
model.add(layers.Embedding(input_dim=vocabulary_size, output_dim=32, input_length=max_words, input_shape=(max_words,)))
|
||||
model.add(layers.LSTM(76))
|
||||
model.add(layers.Dropout(0.3))
|
||||
model.add(layers.Dense(1, activation='sigmoid'))
|
||||
|
||||
model.summary()
|
||||
|
||||
batch_size = 64
|
||||
epochs = 5
|
||||
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
|
||||
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.2)
|
||||
|
||||
test_loss, test_acc = model.evaluate(X_test, y_test)
|
||||
print(f"\nTest accuracy: {test_acc}")
|
||||
print(f"\nTest loss: {test_loss}")
|
||||
|
||||
y_score = model.predict(X_test)
|
||||
y_pred = [1 if y_score[i,0]>=0.5 else 0 for i in range(len(y_score))]
|
||||
from sklearn.metrics import classification_report
|
||||
print(classification_report(y_test, y_pred, labels = [0, 1], target_names=['Negative', 'Positive']))
|
||||
|
||||
from sklearn.metrics import roc_curve, auc
|
||||
import matplotlib.pyplot as plt
|
||||
fpr, tpr, thresholds = roc_curve(y_test, y_score)
|
||||
plt.plot(fpr, tpr)
|
||||
plt.grid()
|
||||
plt.xlabel('False Positive Rate')
|
||||
plt.ylabel('True Positive Rate')
|
||||
plt.title('ROC')
|
||||
plt.show()
|
||||
print('Area under ROC is', auc(fpr, tpr))
|
||||
|
||||
from sklearn.metrics import roc_auc_score
|
||||
print('AUC ROC:', roc_auc_score(y_test, y_score))
|
||||