24 KiB
Отчет по лабораторной работе №1
Текотова Виктория, Секирин Артем, А-02-22
1. В среде GoogleColab создали блокнот(notebook.ipynb).
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks')
- импорт модулей
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
import sklearn
2. Загрузка датасета MNIST
from keras.datasets import mnist
(X_train,y_train),(X_test,y_test)=mnist.load_data()
3. Разбиение набора данных на обучающие и тестовые
from sklearn.model_selection import train_test_split
- объединяем в один набор
X=np.concatenate((X_train,X_test))
y=np.concatenate((y_train,y_test))
- разбиваем по вариантам
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=10000,train_size=60000,random_state=3)
- Вывод размерностей
print('ShapeofXtrain:',X_train.shape)
print('Shapeofytrain:',y_train.shape)
print('ShapeofXtrain:',X_test.shape)
print('Shapeofytrain:',y_test.shape)
ShapeofXtrain: (60000, 784) Shapeofytrain: (60000, 10) ShapeofXtrain: (10000, 784) Shapeofytrain: (10000, 10)
4. Вывод элементов обучающих данных
- Создаем subplot для 4 изображений
for i in range(4):
plt.subplot(1, 4, i+1) # 1 строка, n столбцов
plt.imshow(X_train[i], cmap='gray')
plt.axis('off') # убрать оси
plt.title(y_train[i]) # метка под картинкой
plt.show()
5. Предобработка данных
- развернем каждое изображение 28*28 в вектор 784
num_pixels=X_train.shape[1]*X_train.shape[2]
X_train=X_train.reshape(X_train.shape[0],num_pixels) / 255
X_test=X_test.reshape(X_test.shape[0],num_pixels) / 255
print('ShapeoftransformedXtrain:',X_train.shape)
ShapeoftransformedXtrain: (60000, 784)
- переведем метки в one-hot
from keras.utils import to_categorical
y_train=to_categorical(y_train)
y_test=to_categorical(y_test)
print('Shapeoftransformedytrain:',y_train.shape)
num_classes=y_train.shape[1]
Shapeoftransformedytrain: (60000, 10)
- Вывод размерностей
print('ShapeofXtrain:',X_train.shape)
print('Shapeofytrain:',y_train.shape)
print('ShapeofXtrain:',X_test.shape)
print('Shapeofytrain:',y_test.shape)
ShapeofXtrain: (60000, 784) Shapeofytrain: (60000, 10) ShapeofXtrain: (10000, 784) Shapeofytrain: (10000, 10)
6. Реализация и обучение однослойной нейронной сети
from keras.models import Sequential
from keras.layers import Dense
- 6.1. создаем модель - объявляем ее объектом класса Sequential
model=Sequential()
model.add(Dense(input_dim=num_pixels,units=num_classes,activation='softmax'))
- 6.2. компилируем модель
model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
- Вывод информации об архитектуре модели
print(model.summary())
Model: "sequential" ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense (Dense) │ (None, 10) │ 7,850 │ └─────────────────────────────────┴────────────────────────┴───────────────┘ Total params: 7,850 (30.66 KB) Trainable params: 7,850 (30.66 KB) Non-trainable params: 0 (0.00 B) None
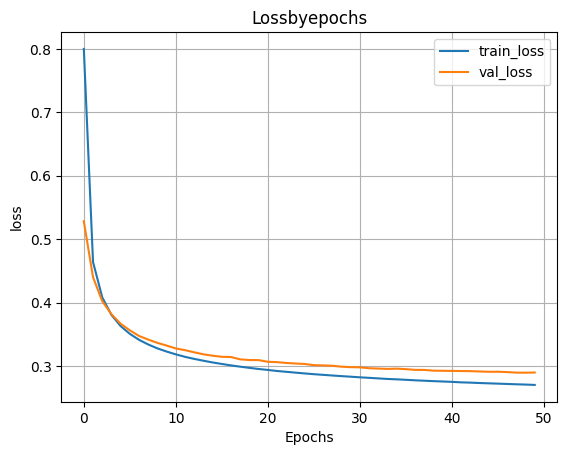
- Обучаем модель
H=model.fit(X_train,y_train,validation_split=0.1,epochs=50)
- Выводим график функции ошибки
plt.plot(H.history['loss'])
plt.plot(H.history['val_loss'])
plt.grid()
plt.xlabel('Epochs')
plt.ylabel('loss')
plt.legend(['train_loss','val_loss'])
plt.title('Lossbyepochs')
plt.show()
7. Применение модели к тестовым данным
scores=model.evaluate(X_test,y_test)
print('Loss on test data:',scores[0])
print('Accuracy on test data:',scores[1])
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.9207 - loss: 0.2944 Loss on test data: 0.2864772379398346 Accuracy on test data: 0.9229999780654907
8. Добавили один скрытый слой и повторили п. 6-7
- при 100 нейронах в скрытом слое
model_1h100=Sequential()
model_1h100.add(Dense(units=100,input_dim=num_pixels,activation='sigmoid'))
model_1h100.add(Dense(units=num_classes,activation='softmax'))
model_1h100.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
- Вывод информации об архитектуре модели
print(model_1h100.summary())
Model: "sequential_1" ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense_1 (Dense) │ (None, 100) │ 78,500 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_2 (Dense) │ (None, 10) │ 1,010 │ └─────────────────────────────────┴────────────────────────┴───────────────┘ Total params: 79,510 (310.59 KB) Trainable params: 79,510 (310.59 KB) Non-trainable params: 0 (0.00 B) None
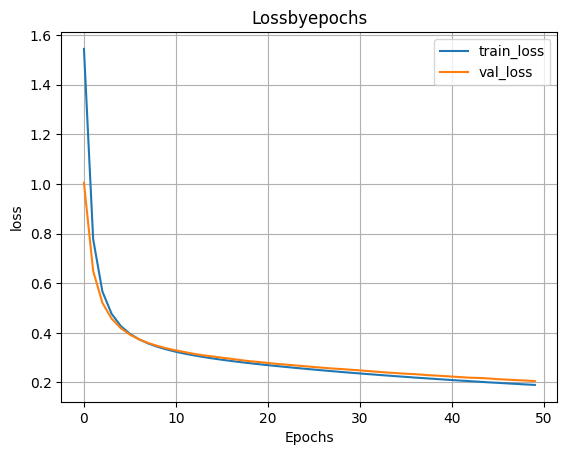
- Обучаем модель
H=model_1h100.fit(X_train,y_train,validation_split=0.1,epochs=50)
- Выводим график функции ошибки
plt.plot(H.history['loss'])
plt.plot(H.history['val_loss'])
plt.grid()
plt.xlabel('Epochs')
plt.ylabel('loss')
plt.legend(['train_loss','val_loss'])
plt.title('Lossbyepochs')
plt.show()
- Оценка качества работы модели на тестовых данных
scores=model_1h100.evaluate(X_test,y_test)
print('Loss on test data:',scores[0])
print('Accuracy on test data:',scores[1])
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - accuracy: 0.9380 - loss: 0.2142 Loss on test data: 0.2046738713979721 Accuracy on test data: 0.942799985408783
- при 300 нейронах в скрытом слое
model_1h300=Sequential()
model_1h300.add(Dense(units=300,input_dim=num_pixels,activation='sigmoid'))
model_1h300.add(Dense(units=num_classes,activation='softmax'))
model_1h300.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
- Вывод информации об архитектуре модели
print(model_1h300.summary())
Model: "sequential_2" ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense_3 (Dense) │ (None, 300) │ 235,500 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_4 (Dense) │ (None, 10) │ 3,010 │ └─────────────────────────────────┴────────────────────────┴───────────────┘ Total params: 238,510 (931.68 KB) Trainable params: 238,510 (931.68 KB) Non-trainable params: 0 (0.00 B) None
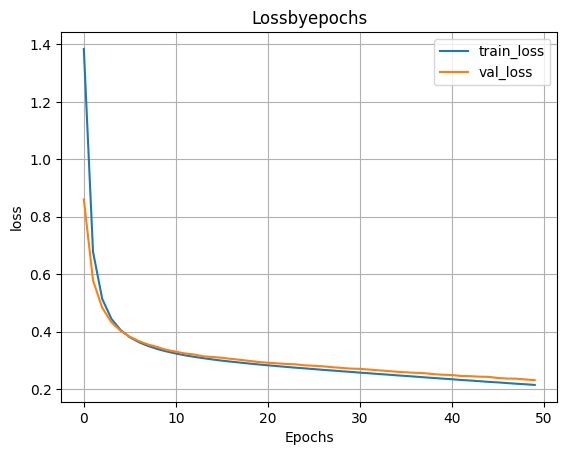
- Обучаем модель
H=model_1h300.fit(X_train,y_train,validation_split=0.1,epochs=50)
- Выводим график функции ошибки
plt.plot(H.history['loss'])
plt.plot(H.history['val_loss'])
plt.grid()
plt.xlabel('Epochs')
plt.ylabel('loss')
plt.legend(['train_loss','val_loss'])
plt.title('Lossbyepochs')
plt.show()
- Оценка качества работы модели на тестовых данных
scores=model_1h300.evaluate(X_test,y_test)
print('Loss on test data:',scores[0])
print('Accuracy on test data:',scores[1])
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.9328 - loss: 0.2403 Loss on test data: 0.23027946054935455 Accuracy on test data: 0.9363999962806702
- при 500 нейронах в скрытом слое
model_1h500=Sequential()
model_1h500.add(Dense(units=500,input_dim=num_pixels,activation='sigmoid'))
model_1h500.add(Dense(units=num_classes,activation='softmax'))
model_1h500.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
- Вывод информации об архитектуре модели
print(model_1h500.summary())
Model: "sequential_3" ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense_5 (Dense) │ (None, 500) │ 392,500 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_6 (Dense) │ (None, 10) │ 5,010 │ └─────────────────────────────────┴────────────────────────┴───────────────┘ Total params: 397,510 (1.52 MB) Trainable params: 397,510 (1.52 MB) Non-trainable params: 0 (0.00 B) None
- Обучаем модель
H=model_1h500.fit(X_train,y_train,validation_split=0.1,epochs=50)
- Выводим график функции ошибки
plt.plot(H.history['loss'])
plt.plot(H.history['val_loss'])
plt.grid()
plt.xlabel('Epochs')
plt.ylabel('loss')
plt.legend(['train_loss','val_loss'])
plt.title('Lossbyepochs')
plt.show()
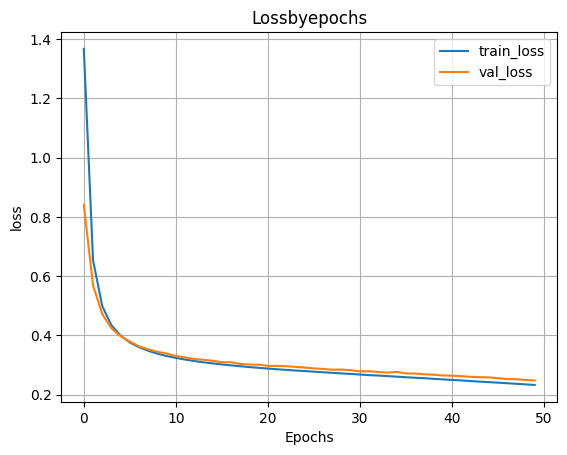
- Оценка качества работы модели на тестовых данных
scores=model_1h500.evaluate(X_test,y_test)
print('Loss on test data:',scores[0])
print('Accuracy on test data:',scores[1])
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.9265 - loss: 0.2585 Loss on test data: 0.24952808022499084 Accuracy on test data: 0.9307000041007996
Как мы видим, лучшая метрика получилась равной 0.942799985408783 при архитектуре со 100 нейронами в скрытом слое, поэтому для дальнейших пунктов используем ее.
9. Добавили второй скрытый слой
- при 50 нейронах во втором скрытом слое
model_1h100_2h50=Sequential()
model_1h100_2h50.add(Dense(units=100,input_dim=num_pixels,activation='sigmoid'))
model_1h100_2h50.add(Dense(units=50,activation='sigmoid'))
model_1h100_2h50.add(Dense(units=num_classes,activation='softmax'))
model_1h100_2h50.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
- Вывод информации об архитектуре модели
print(model_1h100_2h50.summary())
Model: "sequential_4" ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense_7 (Dense) │ (None, 100) │ 78,500 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_8 (Dense) │ (None, 50) │ 5,050 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_9 (Dense) │ (None, 10) │ 510 │ └─────────────────────────────────┴────────────────────────┴───────────────┘ Total params: 84,060 (328.36 KB) Trainable params: 84,060 (328.36 KB) Non-trainable params: 0 (0.00 B) None
- Обучаем модель
H=model_1h100_2h50.fit(X_train,y_train,validation_split=0.1,epochs=50)
- Выводим график функции ошибки
plt.plot(H.history['loss'])
plt.plot(H.history['val_loss'])
plt.grid()
plt.xlabel('Epochs')
plt.ylabel('loss')
plt.legend(['train_loss','val_loss'])
plt.title('Lossbyepochs')
plt.show()
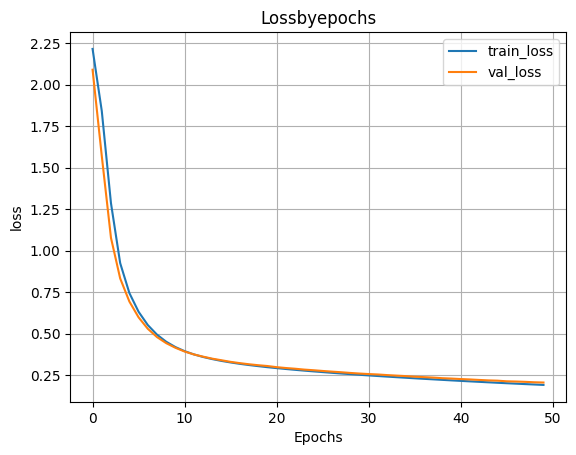
- Оценка качества работы модели на тестовых данных
scores=model_1h100_2h50.evaluate(X_test,y_test)
print('Loss on test data:',scores[0])
print('Accuracy on test data:',scores[1])
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.9388 - loss: 0.2173 Loss on test data: 0.20536193251609802 Accuracy on test data: 0.9416000247001648
- при 100 нейронах во втором скрытом слое
model_1h100_2h100=Sequential()
model_1h100_2h100.add(Dense(units=100,input_dim=num_pixels,activation='sigmoid'))
model_1h100_2h100.add(Dense(units=50,activation='sigmoid'))
model_1h100_2h100.add(Dense(units=num_classes,activation='softmax'))
model_1h100_2h100.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
- Вывод информации об архитектуре модели
print(model_1h100_2h100.summary())
Model: "sequential_5" ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense_10 (Dense) │ (None, 100) │ 78,500 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_11 (Dense) │ (None, 50) │ 5,050 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_12 (Dense) │ (None, 10) │ 510 │ └─────────────────────────────────┴────────────────────────┴───────────────┘ Total params: 84,060 (328.36 KB) Trainable params: 84,060 (328.36 KB) Non-trainable params: 0 (0.00 B) None
- Обучаем модель
H=model_1h100_2h100.fit(X_train,y_train,validation_split=0.1,epochs=50)
- Выводим график функции ошибки
plt.plot(H.history['loss'])
plt.plot(H.history['val_loss'])
plt.grid()
plt.xlabel('Epochs')
plt.ylabel('loss')
plt.legend(['train_loss','val_loss'])
plt.title('Lossbyepochs')
plt.show()
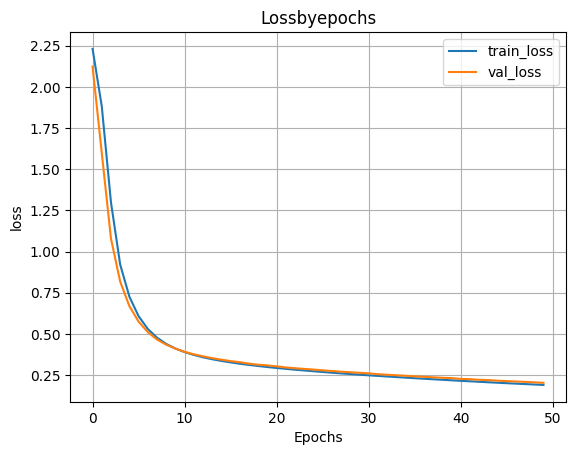
- Оценка качества работы модели на тестовых данных
scores=model_1h100_2h100.evaluate(X_test,y_test)
print('Loss on test data:',scores[0])
print('Accuracy on test data:',scores[1])
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - accuracy: 0.9414 - loss: 0.2154 Loss on test data: 0.2049565464258194 Accuracy on test data: 0.9427000284194946
Количество Количество нейронов в Количество нейронов во Значение метрики скрытых слоев первом скрытом слое втором скрытом слое качества классификации 0 - - 0.9229999780654907 1 100 - 0.942799985408783 1 300 - 0.9363999962806702 1 500 - 0.9307000041007996 2 100 50 0.9416000247001648 2 100 100 0.9427000284194946
Из таблицы видно, что лучше всего справились с задачей НС с одним скрытым слоем и 100 нейронами и НС с двумя скрытыми слоями по 100 нейронов. Метрика точности достигла почти 95% при достаточно простой архитектуре сетей, это может быть связано с тем, что датасет MNIST имеет только 60,000 обучающих примеров - недостаточно для более сложных архитектур. Также при усложнении архитектуры сети появляется риск переобучения. В нашей задаче мы видим, что при увеличении числа нейронов в скрытых слоях метрика падает.Простая модель лучше обобщает на подобных учебных датасетах, более сложные же архитектуры стоит использовать на более сложных датасетах, например ImageNet.
11. Сохранение наилучшей модели на диск
model_1h100.save('/content/drive/MyDrive/Colab Notebooks/best_model.keras')
12. Вывод тестовых изображений и результатов распознаваний
for i in range(1,3,1):
result=model_1h100.predict(X_test[i:i+1])
print('NNoutput:',result)
plt.imshow(X_test[i].reshape(28,28),cmap=plt.get_cmap('gray'))
plt.show()
print('Realmark:',str(np.argmax(y_test[i])))
print('NNanswer:',str(np.argmax(result)))
NNoutput: [[1.4195202e-03 1.1157753e-03 1.3601109e-02 1.2154530e-01 4.0756597e-04 8.3563459e-01 2.9775328e-03 7.1576833e-05 1.9775130e-02 3.4518384e-03]]
Realmark: 3 NNanswer: 5 NNoutput: [[1.1838503e-04 1.7378072e-04 4.7975280e-03 9.3888867e-01 3.9176564e-05 3.4841071e-03 1.5808465e-06 1.6603278e-02 1.6292465e-03 3.4264266e-02]]
Realmark: 3 NNanswer: 3
13. Тестирование на собственных изображениях
- загрузка 1 собственного изображения
from PIL import Image
file_data=Image.open('/content/drive/MyDrive/Colab Notebooks/2.png')
file_data=file_data.convert('L')
test_img=np.array(file_data)
- вывод собственного изображения, предобработка, распознавание
plt.imshow(test_img,cmap=plt.get_cmap('gray'))
plt.show()
#предобработка
test_img=test_img/255
test_img=test_img.reshape(1,num_pixels)
#распознавание
result=model_1h100.predict(test_img)
print('Ithinkit\'s',np.argmax(result))

Ithinkit's 2
- тест 2 изображения
from PIL import Image
file_data=Image.open('/content/drive/MyDrive/Colab Notebooks/5.png')
file_data=file_data.convert('L')
test_img=np.array(file_data)
plt.imshow(test_img,cmap=plt.get_cmap('gray'))
plt.show()
test_img=test_img/255
test_img=test_img.reshape(1,num_pixels)
result=model_1h100.predict(test_img)
print('Ithinkit\'s',np.argmax(result))
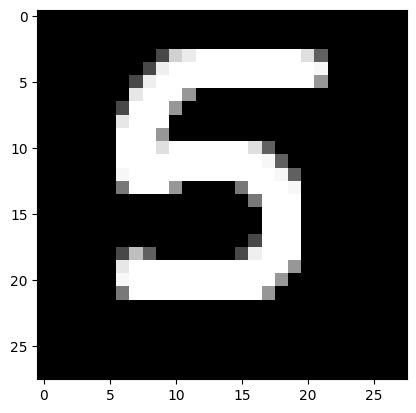
Ithinkit's 5
Сеть не ошиблась и корректно распознала обе цифры на изображениях
14. Тестирование на собственных повернутых изображениях
from PIL import Image
file_data=Image.open('/content/drive/MyDrive/Colab Notebooks/2_1.png')
file_data=file_data.convert('L')
test_img=np.array(file_data)
plt.imshow(test_img,cmap=plt.get_cmap('gray'))
plt.show()
test_img=test_img/255
test_img=test_img.reshape(1,num_pixels)
result=model_1h100.predict(test_img)
print('Ithinkit\'s',np.argmax(result))
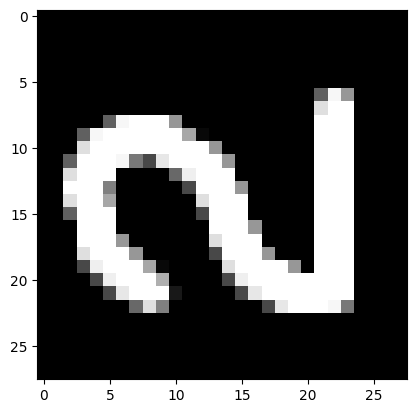
Ithinkit's 5
from PIL import Image
file_data=Image.open('/content/drive/MyDrive/Colab Notebooks/5_1.png')
file_data=file_data.convert('L')
test_img=np.array(file_data)
plt.imshow(test_img,cmap=plt.get_cmap('gray'))
plt.show()
test_img=test_img/255
test_img=test_img.reshape(1,num_pixels)
result=model_1h100.predict(test_img)
print('Ithinkit\'s',np.argmax(result))
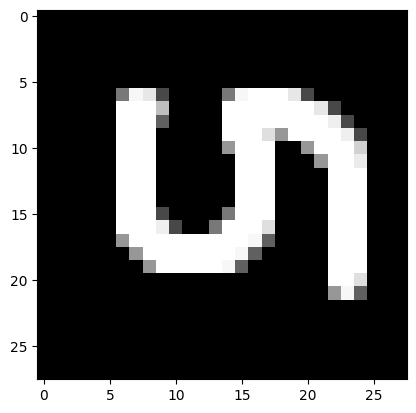
Ithinkit's 7
При повороте изображений сеть не распознала цифры правильно. Так как она не обучалась на повернутых изображениях.