Вы не можете выбрать более 25 тем
Темы должны начинаться с буквы или цифры, могут содержать дефисы(-) и должны содержать не более 35 символов.
397 строки
19 KiB
Markdown
397 строки
19 KiB
Markdown
# Отчет по лабораторной работе № 2
|
|
|
|
### Щипков Матвей, Железнов Артем, Михаил Ледовской
|
|
|
|
### Бригада 7
|
|
|
|
## 1) В среде Google Colab создать новый блокнот (notebook). Импортировать необходимые для работы библиотеки и модули.
|
|
|
|
```py
|
|
import os
|
|
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab2')
|
|
|
|
import numpy as np
|
|
import lab02_lib as lib
|
|
```
|
|
|
|
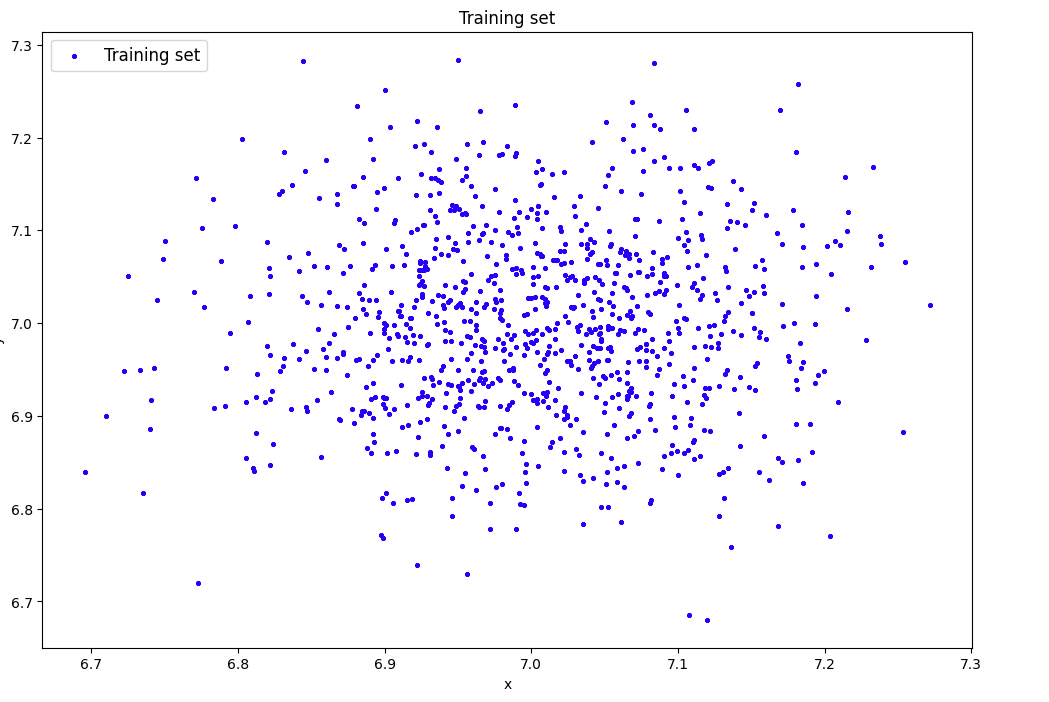
## 2) Сгенерировать индивидуальный набор двумерных данных в пространстве признаков с координатами центра (k, k), где k – номер бригады. Вывести полученные данные на рисунок и в консоль.
|
|
|
|
```py
|
|
data=lib.datagen(7,7,1000,2)
|
|
|
|
print('Исходные данные:')
|
|
print(data)
|
|
print('Размерность данных:')
|
|
print(data.shape)
|
|
```
|
|
|
|
|
|
|
|
### Исходные данные:
|
|
|
|
[[6.97836717 6.88645112]
|
|
[6.90945104 7.01250991]
|
|
[7.06556196 6.87586275]
|
|
...
|
|
[6.91462186 6.99896065]
|
|
[7.12657266 7.02442827]
|
|
[6.91895144 6.81014147]]
|
|
|
|
### Размерность данных:
|
|
|
|
(1000, 2)
|
|
|
|
## 3) Создать и обучить автокодировщик AE1 простой архитектуры, выбрав небольшое количество эпох обучения. Зафиксировать в таблице вида количество скрытых слоёв и нейронов в них.
|
|
|
|
```py
|
|
# AE1
|
|
patience= 10
|
|
ae1_trained, IRE1, IREth1= lib.create_fit_save_ae(data,'out/AE1.h5','out/AE1_ire_th.txt', 50, True, patience)
|
|
```
|
|
|
|
## 4) Зафиксировать ошибку MSE, на которой обучение завершилось. Построить график ошибки реконструкции обучающей выборки. Зафиксировать порог ошибки реконструкции – порог обнаружения аномалий.
|
|
|
|
```
|
|
Epoch 50/50
|
|
loss: 47.3273
|
|
```
|
|
|
|
```py
|
|
lib.ire_plot('training', IRE1, IREth1, 'AE1')
|
|
```
|
|
|
|

|
|
|
|
```py
|
|
print("Порог ошибки = ",IREth1)
|
|
```
|
|
|
|
```
|
|
Порог ошибки реконструкции = 10.03
|
|
```
|
|
|
|
## 5) Создать и обучить второй автокодировщик AE2 с усложненной архитектурой, задав большее количество эпох обучения.
|
|
|
|
```py
|
|
# AE2
|
|
ae2_trained, IRE2, IREth2= lib.create_fit_save_ae(data,'out/AE2.h5','out/AE2_ire_th.txt', 1000, True, patience)
|
|
```
|
|
|
|
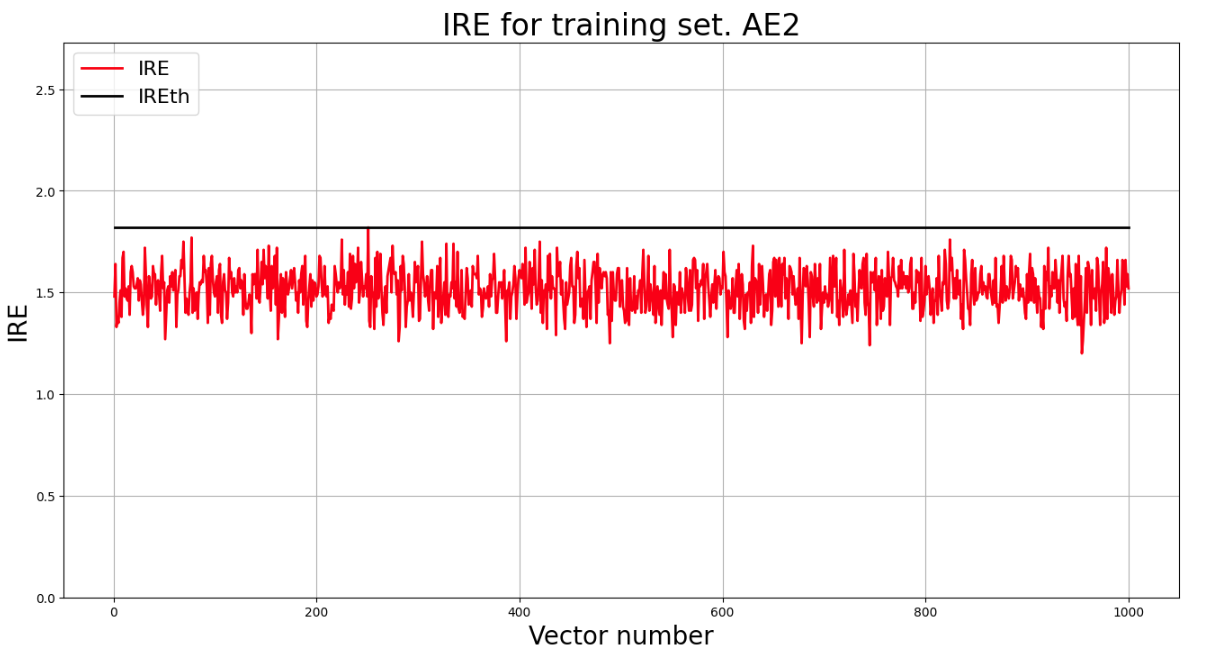
## 6) Зафиксировать ошибку MSE, на которой обучение завершилось. Построить график ошибки реконструкции обучающей выборки. Зафиксировать второй порог ошибки реконструкции – порог обнаружения аномалий.
|
|
|
|
```
|
|
Epoch 1000/1000
|
|
loss: 0.6548
|
|
```
|
|
|
|
```py
|
|
# Построение графика
|
|
lib.ire_plot('training', IRE2, IREth2, 'AE2')
|
|
```
|
|
|
|
|
|
|
|
```py
|
|
print("Порог ошибки = ",IREth2)
|
|
```
|
|
|
|
```
|
|
Порог ошибки = 1.44
|
|
```
|
|
|
|
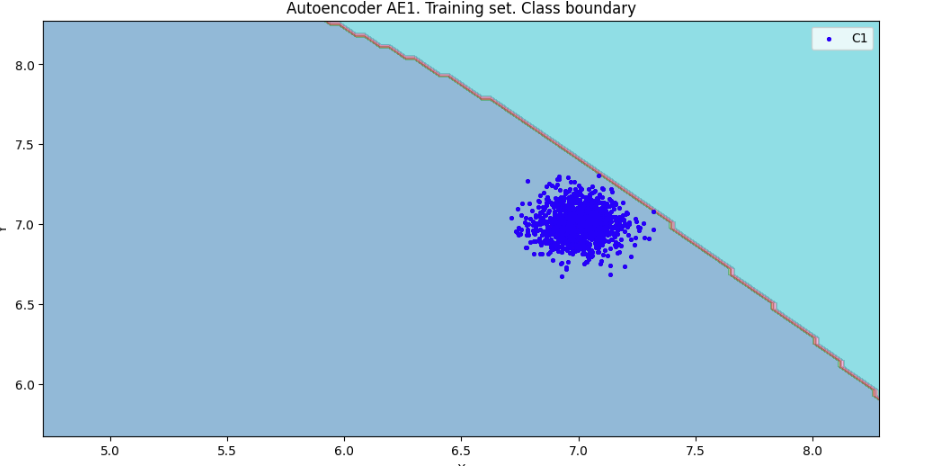
## 7) Рассчитать характеристики качества обучения EDCA для AE1 и AE2. Визуализировать и сравнить области пространства признаков, распознаваемые автокодировщиками AE1 и AE2. Сделать вывод о пригодности AE1 и AE2 для качественного обнаружения аномалий.
|
|
|
|
```py
|
|
numb_square= 20
|
|
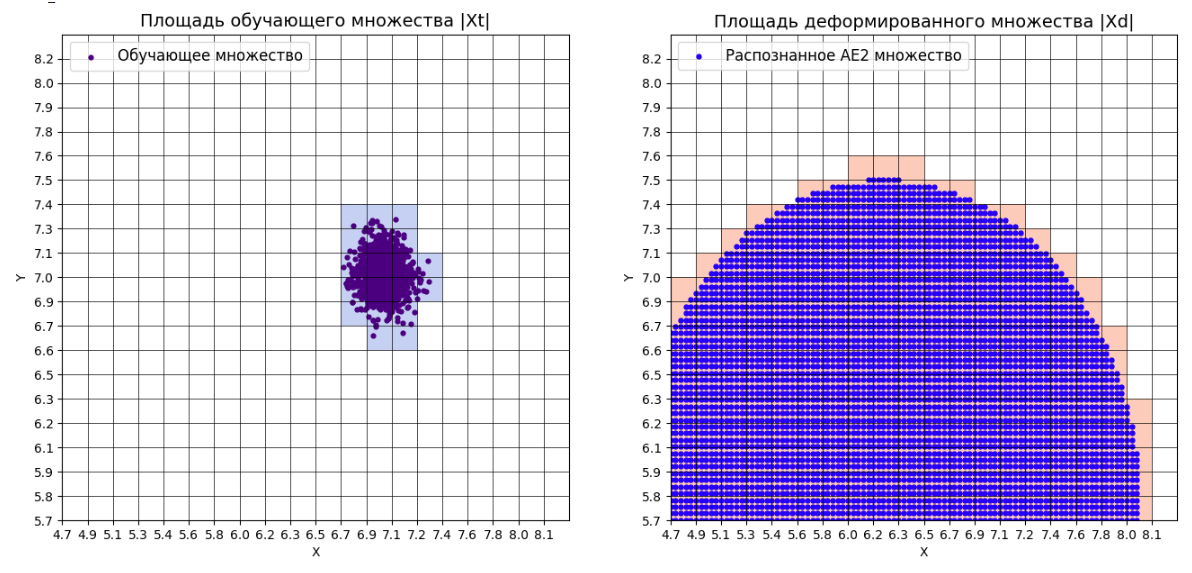
xx,yy,Z1=lib.square_calc(numb_square,data,ae1_trained,IREth1,'1',True)
|
|
```
|
|
|
|
```
|
|
amount: 20
|
|
amount_ae: 311
|
|
```
|
|
|
|
|
|

|
|

|
|
|
|
```
|
|
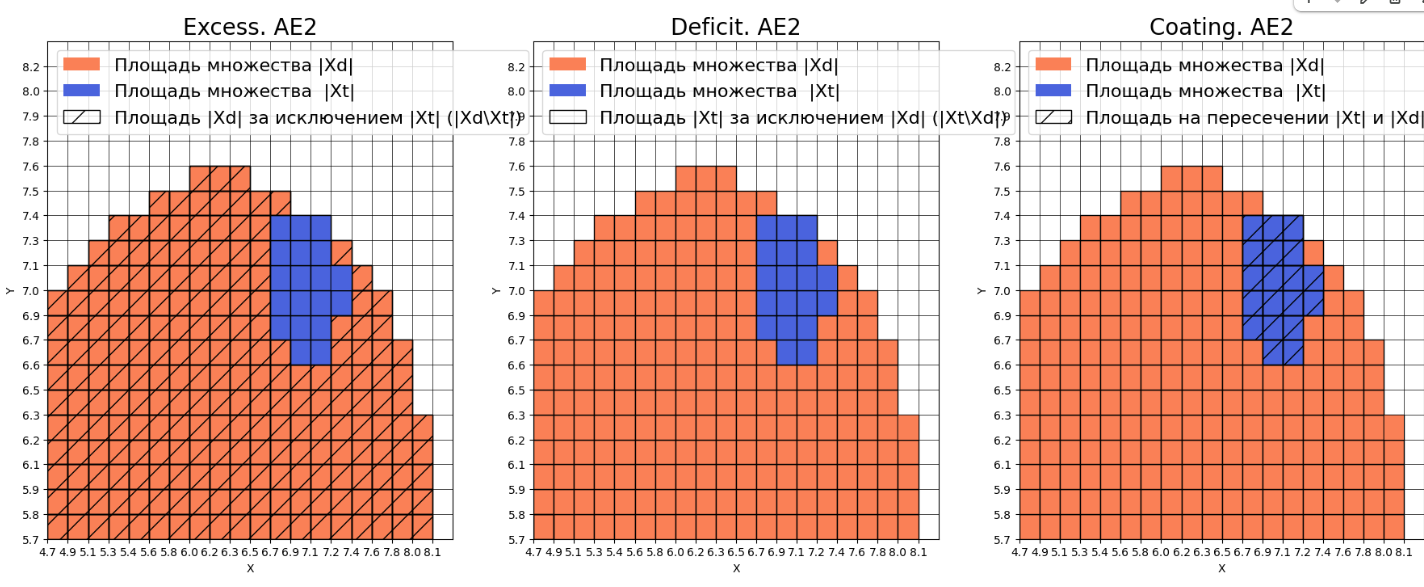
Оценка качества AE1
|
|
IDEAL = 0. Excess: 14.55
|
|
IDEAL = 0. Deficit: 0.0
|
|
IDEAL = 1. Coating: 1.0
|
|
summa: 1.0
|
|
IDEAL = 1. Extrapolation precision (Approx): 0.06430868167202572
|
|
```
|
|
|
|
```py
|
|
numb_square= 20
|
|
xx,yy,Z2=lib.square_calc(numb_square,data,ae2_trained,IREth2,'2',True)
|
|
```
|
|
|
|

|
|
|
|
```
|
|
amount: 20
|
|
amount_ae: 185
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
Оценка качества AE2
|
|
IDEAL = 0. Excess: 8.25
|
|
IDEAL = 0. Deficit: 0.0
|
|
IDEAL = 1. Coating: 1.0
|
|
summa: 1.0
|
|
IDEAL = 1. Extrapolation precision (Approx): 0.10810810810810811
|
|
```
|
|
|
|
```py
|
|
# сравнение характеристик качества обучения и областей аппроксимации
|
|
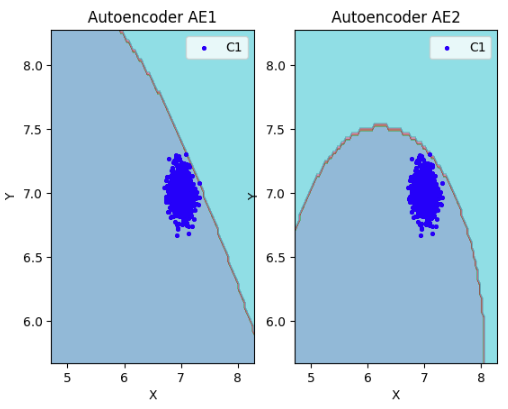
lib.plot2in1(data, xx, yy, Z1, Z2)
|
|
```
|
|
|
|
|
|
|
|
## 8) Если автокодировщик AE2 недостаточно точно аппроксимирует область обучающих данных, то подобрать подходящие параметры автокодировщика и повторить шаги (6) – (8).
|
|
|
|
### Вывод: автокодировщик AE2 достаточно точно аппроксимирует область обучающих данных
|
|
|
|
## 9) Изучить сохраненный набор данных и пространство признаков. Создать тестовую выборку, состоящую, как минимум, из 4ёх элементов, не входящих в обучающую выборку. Элементы должны быть такими, чтобы AE1 распознавал их как норму, а AE2 детектировал как аномалии.
|
|
|
|
```py
|
|
data_test = np.array([[7.03, 7.12], [6.95, 7.03], [6.92, 6.92], [7.11, 7.09], [7.21, 7.08], [7.08, 6.92]])
|
|
```
|
|
|
|
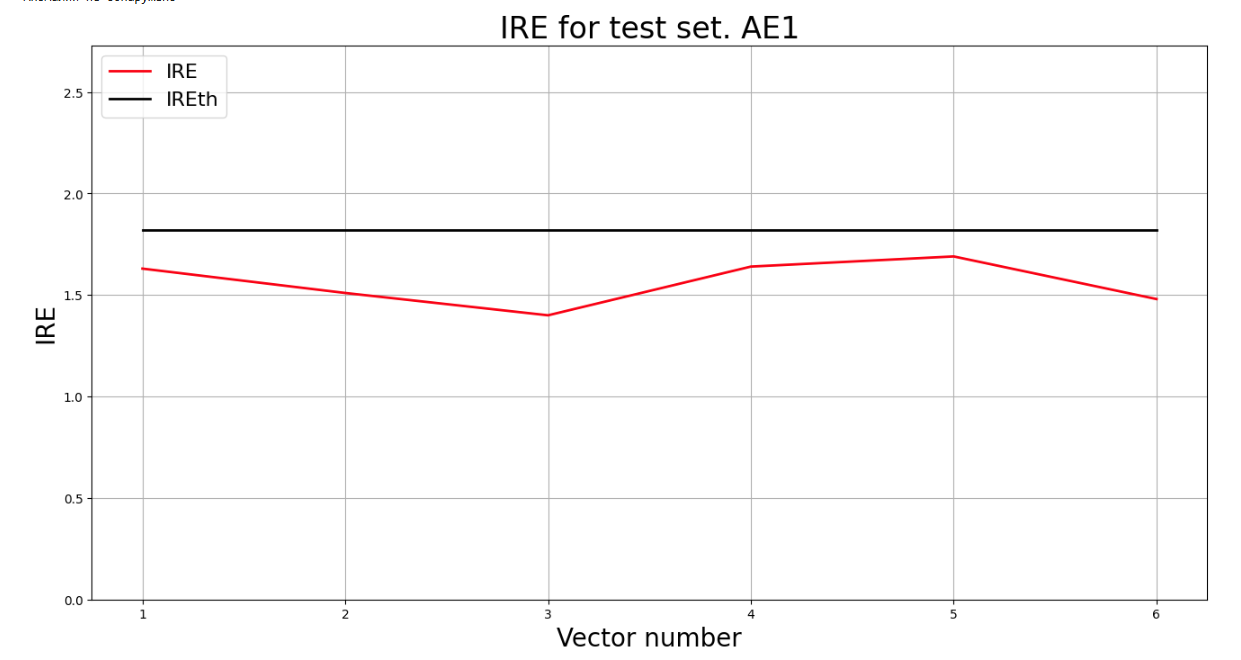
## 10) Применить обученные автокодировщики AE1 и AE2 к тестовым данным и вывести значения ошибки реконструкции для каждого элемента тестовой выборки относительно порога на график и в консоль.
|
|
|
|
```py
|
|
# тестирование АE1
|
|
predicted_labels1, ire1 = lib.predict_ae(ae1_trained, data_test, IREth1)
|
|
lib.anomaly_detection_ae(predicted_labels1, ire1, IREth1)
|
|
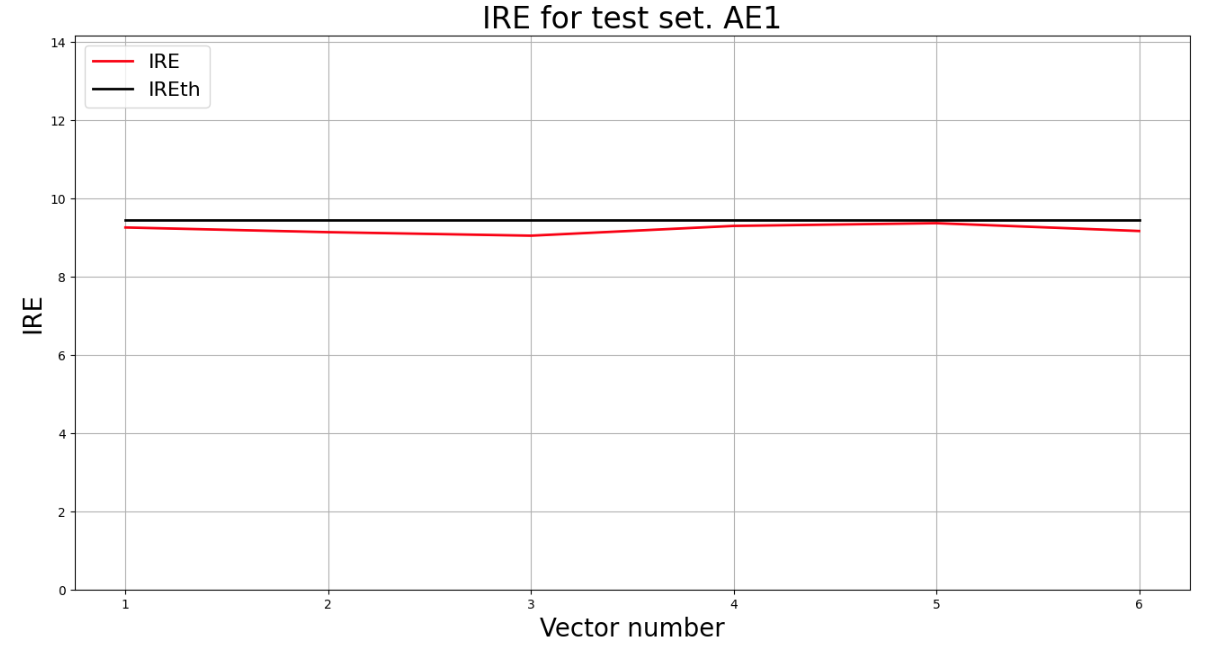
lib.ire_plot('test', ire1, IREth1, 'AE1')
|
|
```
|
|
|
|
```
|
|
Аномалий не обнаружено
|
|
```
|
|
|
|
|
|
|
|
```py
|
|
# тестирование АE2
|
|
predicted_labels2, ire2 = lib.predict_ae(ae2_trained, data_test, IREth2)
|
|
lib.anomaly_detection_ae(predicted_labels2, ire2, IREth2)
|
|
lib.ire_plot('test', ire2, IREth2, 'AE1')
|
|
```
|
|
|
|
|
|
|
|
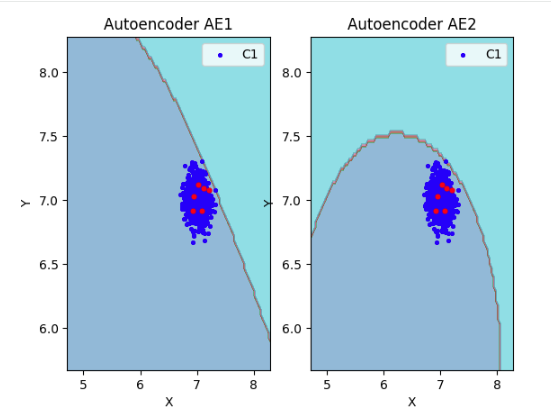
## 11) Визуализировать элементы обучающей и тестовой выборки в областях пространства признаков, распознаваемых автокодировщиками AE1 и AE2.
|
|
|
|
```py
|
|
lib.plot2in1_anomaly(data, xx, yy, Z1, Z2, data_test)
|
|
```
|
|
|
|
|
|
|
|
## 12) Результаты исследования занести в таблицу:
|
|
|
|
| | Количество скрытых слоев | Количество нейронов в скрытых слоях | Количество эпох обучения | Ошибка MSE_stop | Порог ошибки реконструкции | Значение показателя Excess | Значение показателя Approx | Количество обнаруженных аномалий |
|
|
| --- | ------------------------ | ----------------------------------- | ------------------------ | --------------- | -------------------------- | -------------------------- | -------------------------- | -------------------------------- |
|
|
| АЕ1 | 3 | 3 1 3 | 50 | 47.3273 | 10.03 | 14.55 | 0.0643 | 0 |
|
|
| АЕ2 | 7 | 5 3 2 1 2 3 5 | 1000 | 0.6548 | 1.44 | 8.25 | 0.1081 | 0 |
|
|
|
|
## 13) Для качественного обнаружения аномалий в данны сделать выводы о требованиях к:
|
|
|
|
Вывод:
|
|
|
|
1. Данные для обучения
|
|
Должны быть однородными, без выбросов и достаточно плотными вокруг области нормы, чтобы модель могла точно восстановить структуру распределения.
|
|
2. Архитектура автокодировщика
|
|
Нужна умеренно глубокая модель с узким bottleneck: простая архитектура даёт высокую ошибку, более сложная (как AE2) обеспечивает точную реконструкцию.
|
|
3. Количество эпох обучения
|
|
Эпох должно быть достаточно много, чтобы ошибка стабилизировалась на плато; 50 мало, 1000 — достаточно для качественной аппроксимации.
|
|
4. Ошибка MSE_stop
|
|
Должна быть низкой и соответствовать естественному разбросу данных: большие значения (как у AE1) делают модель непригодной для детекции.
|
|
5. Порог ошибки реконструкции
|
|
Должен быть малым и согласованным с качеством обучения: слишком большой порог (как у AE1) не позволяет выявлять аномалии.
|
|
6. Ошибка реконструкции обучающей выборки
|
|
Должна быть равномерной и низкой: это формирует узкую и точную область нормы.
|
|
7. Характеристики качества EDCA
|
|
Показатели Excess и Approx должны стремиться к минимальным значениям: AE2 даёт лучшее покрытие и точность, а значит лучше подходит для обнаружения аномалий.
|
|
|
|
# Задание 2.
|
|
|
|
## 1. Описание набора реальных данных
|
|
|
|
Исходный набор данных Letter Recognition Data Set из репозитория машинного обучения UCI представляет собой набор данных для многоклассовой классификации. Набор предназначен для распознавания черно-белых пиксельных прямоугольников как одну из 26 заглавных букв английского алфавита, где буквы алфавита представлены в 16 измерениях. Чтобы получить данные, подходящие для обнаружения аномалий, была произведена подвыборка данных из 3 букв, чтобы сформировать нормальный класс, и случайным образом их пары были объединены так, чтобы их размерность удваивалась. Чтобы сформировать класс аномалий, случайным образом были выбраны несколько экземпляров букв, которые не входят нормальный класс, и они были объединены с экземплярами из нормального класса. Процесс объединения выполняется для того, чтобы сделать обнаружение более сложным, поскольку каждый аномальный пример также будет иметь некоторые нормальные значения признаков.
|
|
|
|
- Количество признаков - 32
|
|
|
|
- Количество примеров - 1600
|
|
|
|
- Количество нормальных примеров - 1500
|
|
|
|
- Количество аномальных примеров - 100
|
|
|
|
## 2. Загрузка многомерной обучающей выборки
|
|
|
|
```python
|
|
train= np.loadtxt('letter_train.txt', dtype=float)
|
|
test = np.loadtxt('letter_test.txt', dtype=float)
|
|
```
|
|
|
|
## 3. Вывод данных и размера выборки
|
|
|
|
```python
|
|
print('Исходные данные:')
|
|
print(train)
|
|
print('Размерность данных:')
|
|
print(train.shape)
|
|
```
|
|
|
|
> Исходные данные:
|
|
>
|
|
> [[ 6. 10. 5. ... 10. 2. 7.]
|
|
>
|
|
> [ 0. 6. 0. ... 8. 1. 7.]
|
|
>
|
|
> [ 4. 7. 5. ... 8. 2. 8.]
|
|
>
|
|
> ...
|
|
>
|
|
> [ 7. 10. 10. ... 8. 5. 6.]
|
|
>
|
|
> [ 7. 7. 10. ... 6. 0. 8.]
|
|
>
|
|
> [ 3. 4. 5. ... 9. 5. 5.]]
|
|
>
|
|
> Размерность данных:
|
|
>
|
|
> (1500, 32)
|
|
|
|
## 4. Создание и обучение автокодировщика с подходящей для данных архитектурой.
|
|
|
|
```python
|
|
ae3_trained, IRE3, IREth3 = lib.create_fit_save_ae(train,'out/AE3.h5','out/AE3_ire_th.txt',
|
|
100000, False, 20000, early_stopping_delta = 0.001)
|
|
```
|
|
|
|
> Задать архитектуру автокодировщиков или использовать архитектуру по умолчанию? (1/2): 1
|
|
>
|
|
> Задайте количество скрытых слоёв (нечетное число) : 9
|
|
>
|
|
> Задайте архитектуру скрытых слоёв автокодировщика, например, в виде 3 1 3 : 64 48 32 24 16 24 32 48 64
|
|
>
|
|
> Epoch 1000/100000
|
|
>
|
|
> - loss: 6.0089
|
|
>
|
|
> Epoch 2000/100000
|
|
>
|
|
> - loss: 6.0089
|
|
>
|
|
> ...
|
|
>
|
|
> Epoch 99000/100000
|
|
>
|
|
> - loss: 0.0862
|
|
>
|
|
> Epoch 100000/100000
|
|
>
|
|
> - loss: 0.0864
|
|
|
|
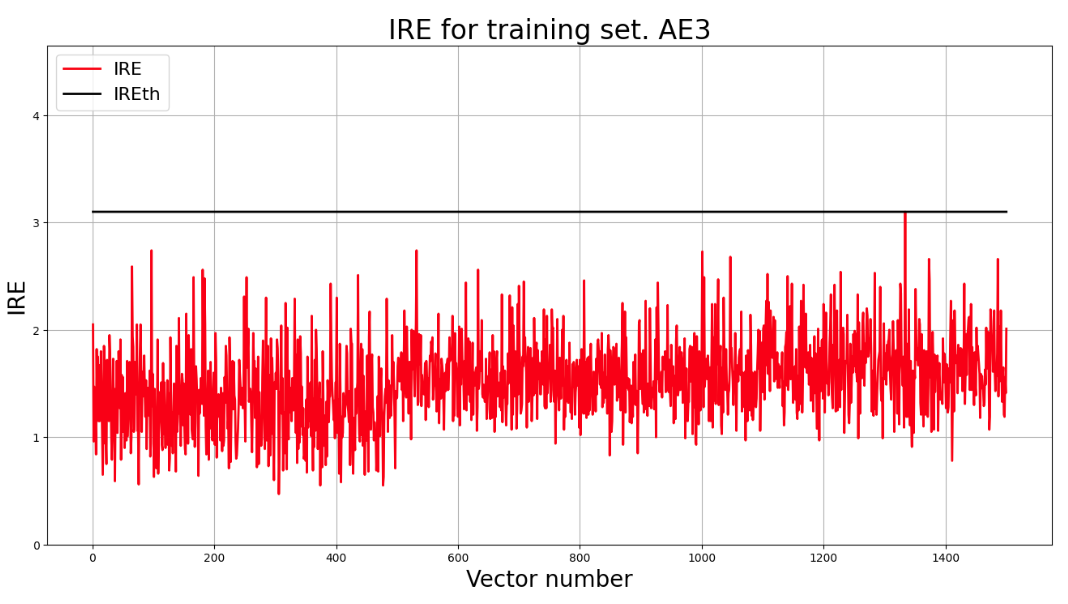
## 5. Построение графика ошибки реконструкции обучающей выборки. Вывод порога ошибки реконструкции – порога обнаружения аномалий.
|
|
|
|
```python
|
|
lib.ire_plot('training', IRE3, IREth3, 'AE3')
|
|
```
|
|
|
|
|
|
|
|
```python
|
|
print("Порог ошибки реконструкции = ",IREth3)
|
|
```
|
|
|
|
> Порог ошибки реконструкции = 3.1
|
|
|
|
## 6. Загрузка многомерной тестовой выборки
|
|
|
|
```python
|
|
print('Исходные данные:')
|
|
print(test)
|
|
print('Размерность данных:')
|
|
print(test.shape)
|
|
```
|
|
|
|
> Исходные данные:
|
|
>
|
|
> [[ 8. 11. 8. ... 7. 4. 9.]
|
|
>
|
|
> [ 4. 5. 4. ... 13. 8. 8.]
|
|
>
|
|
> [ 3. 3. 5. ... 8. 3. 8.]
|
|
>
|
|
> ...
|
|
>
|
|
> [ 4. 9. 4. ... 8. 3. 8.]
|
|
>
|
|
> [ 6. 10. 6. ... 9. 8. 8.]
|
|
>
|
|
> [ 3. 1. 3. ... 9. 1. 7.]]
|
|
>
|
|
> Размерность данных:
|
|
>
|
|
> (100, 32)
|
|
|
|
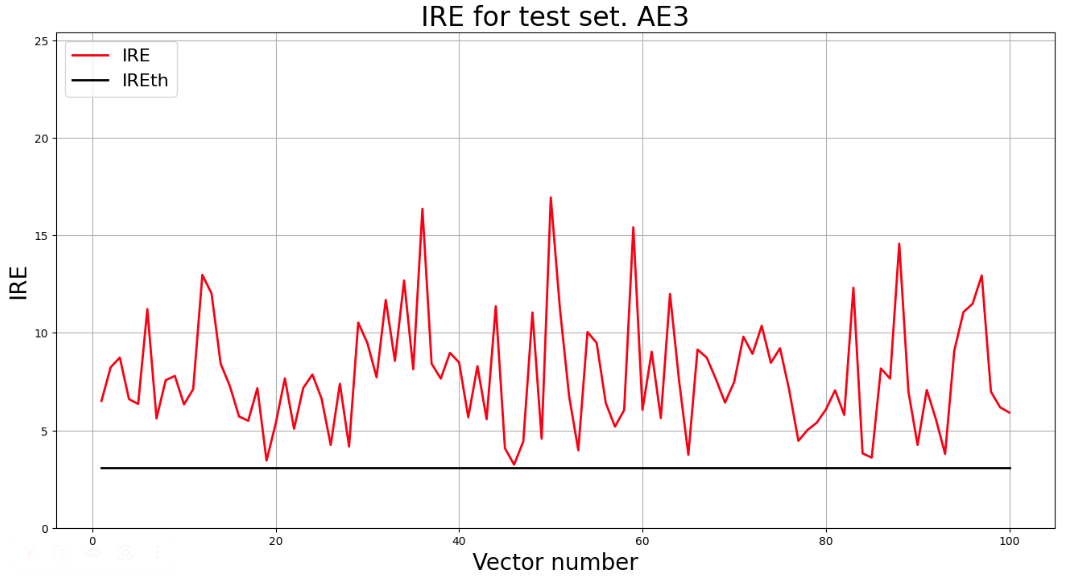
## 7. Выввод графика ошибки реконструкции элементов тестовой выборки относительно порога
|
|
|
|
```python
|
|
predicted_labels3, ire3 = lib.predict_ae(ae3_trained, test, IREth3)
|
|
lib.anomaly_detection_ae(predicted_labels3, ire3, IREth3)
|
|
lib.ire_plot('test', ire3, IREth3, 'AE3')
|
|
```
|
|
|
|
> i Labels IRE IREth
|
|
>
|
|
> 0 [1.] [6.51] 3.1
|
|
>
|
|
> 1 [1.] [8.23] 3.1
|
|
>
|
|
> 2 [1.] [8.73] 3.1
|
|
>
|
|
> ...
|
|
>
|
|
> 98 [1.] [6.18] 3.1
|
|
>
|
|
> 99 [1.] [5.91] 3.1
|
|
>
|
|
> Обнаружено 100.0 аномалий
|
|
|
|
|
|
|
|
## 8. Параметры наилучшего автокодировщика и результаты обнаружения аномалий
|
|
|
|
| Dataset name | Количество скрытых слоев | Количество нейронов в скрытых слоях | Количество эпох обучения | Ошибка MSE_stop | Порог ошибки реконструкции | % обнаруженных аномалий |
|
|
| ------------ | :----------------------: | :---------------------------------: | :----------------------: | :-------------: | :------------------------: | :---------------------: |
|
|
| Letter | 9 | 64 48 32 24 16 24 32 48 64 | 100000 | 0.0864 | 3.1 | 100.0 |
|
|
|
|
## 9. Вывод о требованиях
|
|
|
|
Вывод:
|
|
При работе с данными высокой размерности для корректного выявления аномалий важно учитывать несколько моментов.
|
|
|
|
Во-первых, обучающая выборка должна состоять только из нормальных примеров, иначе модель не сможет сформировать корректную область нормы и определить адекватный порог реконструкции.
|
|
|
|
Во-вторых, автокодировщик должен иметь глубокую и симметричную структуру: постепенное уменьшение числа нейронов к центру и последующее расширение назад к исходной размерности. На практике это требует архитектуры примерно из 7–11 скрытых слоёв.
|
|
|
|
В-третьих, для высокоразмерных данных необходимо длительное обучение: модель выходит на стабильную ошибку только после большого числа эпох. В данном случае приемлемый результат достигался при обучении порядка 100000 итераций с большим значением patience.
|
|
|
|
В-четвёртых, значение ошибки на момент остановки должно быть достаточно малым — около 0.1, иначе восстановление данных будет недостаточно точным.
|
|
|
|
И наконец, порог реконструкции должен оставаться в низком диапазоне (в районе 3.1), чтобы успешно отделять нормальные примеры от аномальных даже при высокой размерности признаков.
|