23 KiB
Лабораторная работа №2. Проведение экспериментов по настройке модели.
Цель работы
Провести ряд экспериментов по настройке модели, логируя все результаты в MLFlow. Научиться пользоваться инструментами autofeat, mlxtend, MLFlow
Подготовка
Работа содержит задания "со звездочкой", выполнять котороые не обязательно, но их выполнение откроет новые знания :)
Можете их выполнить дома в качестве самостоятельного задания.
Их выполнение или не выполнение не будет влиять на итоговую оценку.
Задание
- В VS Code открыть папку с вашим проектом и активировать виртуальное окружение.
- Создать директорию и ноутбук, в котором вы будете проводить исследования.
- Загрузить очищенную выборку. Разбить ее на тестовую и обучающую в пропорции 25%-75%
- Создать переменные, содержащие названия столбцов с числовыми и категориальными признаками
- Создать pipeline обработки признаков и обучения модели. Для числовых признаков использовать
StandardScaler, для категориальных -TargetEncoder(для задачи классификации) илиOrdinalEncoderдля задачи регрессии. В качестве модели -RandomForest - Обучить baseline-модель и получить метрики качества на тестовой выборке. Для задачи классификации это
precision,recall,f1,roc_auc. Для регрессии -mae,mape,mse
- Создать в корне вашего проекта директорию
./mlflowв которой будет запускаться фреймворк. - Написать sh-скрипт по запуску mlflow локально с хранилищем экспериментов (backend store) в СУБД sqlite. Запустить mlflow, убедиться в его работе.
- Залогировать baseline-модель в новый эксперимент. Зарегистрировать модель.
- С использованием библиотеки
sklearnсоздать дополнительные признаки, обучить модель, залогировать ее. - (*) Сгенерировать новые признаки с использованием библиотект
autofeat, обучить модель, залогировать ее. - С использованием библиотеки
mlxtendотобрать N наиболее важных признаков. N выбирается с учетом количества признаков на предыдущем шаге, ориентировочный диапазон - от 20% до 70%. Обучить модель, залогировать ее. - (*) Повторите предыдущий пункт, изменив направление отбора признаков и\или с помощью подхода
RFE. Проанализируйте, схожие ли признаки выбраны другим алгоритмом? - С помощью
optunaнастроить оптимальные параметры для модели, показывающей лучший результат. Обучить модель, залогировать ее, зарегистрировать очередную версию. - (*) Обучить модель с помощью алгоритма CatBoost с выбранным вами набором признаков, залогировать ее, зарегистрировать очередную версию. Не забудьте воспользоваться оберткой (flavour) catboost.
- Проанализировать все прогоны и выбрать модель, показывающую наилучшее качество.
Обучить эту модель на всей выборке (а не только на train-части), залогировать ее. В реестре моделей установить ей тэг
Production. Эту модель мы будем деплоить в следующей лабораторной работе. - Сохранить и закоммитить два скриншота из интерфейса mlflow с метриками качества и версиями зарегистрированной модели и файл MLModel для
Production-модели. - Актуализировать файлы
requirements.txtиREADME.md,.gitignore - Отправить изменения на github. Сохранить на флешку или иным способом директорию
./mlflow
Методические указания
1
Работа является продолжением ЛР1. Выполнять ее нужно в той же директории проекта и с тем же виртуальным окуржением, что и ЛР1.
Если вы выполняете работу не на том же компьютере, что и ЛР1, то проект придется восстановить с гитхаба. Очень кстати в файле README указаны все команды по запуску проекта :)
2
В директории вашего проекта создать новую директорию ./research, в которой будут храниться артефакты по настройке модели. Создать в ней ноутбук, в котором вы будете проводить исследования.
my_proj
|_____ .venv_my_proj
|_____ .git
|_____ data
| |___ ...
|
|_____ eda
| |___ ...
|
|_____ research
| |___ research.ipynb
|
|_____ .gitignore
|_____ README.md
|_____ requirements.txt
3
В данной работе вы будете использовать обработанную и очищенную выборку, которая была получена в результате выполнения ЛР1. Ее следовало сохранить, однако если это не было сделано, то необходимо прогнать код ЛР1, чтобы заново ее получить.
Деление на обучающую и тестовую - стандартным train_test_split из sklearn 75%-25%
4
Переменные, содержащие названия столбцов с числовыми и категориальными признаками вы уже создавали в ЛР1, код можно подглядеть там.
5
Pipeline на данном этапе будет состоять из двух шагов - transform, на котором вы проводите преобразования признаков, и classification (regression), на котором обучаете модель.
На шаге transform для числовых признаков использовать StandardScaler, для категориальных - TargetEncoder(для задачи классификации) или OrdinalEncoder для задачи регрессии.
В качестве модели в работе будем использовать RandomForest.
Известно, что
RandomForestи другие алгоритмы на основе деревьев не нуждаются в шкалировании числовых признаков. Кроме того, существуют алгоритмы на основе деревьев, которые нативно обрабатывают категориальные признаки, например CatBoost. Однако это частный случай. Для возможности применения других алгоритмов, помимо деревьев, мы проведем стандартные шаги шкалирования и кодирования.
Если ваша модель обучается уже дольше 5 минут, то имеет смысл остановить обучение и либо уменьшить объем выборки (например, воспользовавшись методом sample:
DataFrame.sample(frac=0.25)тутfrac=0.25означает, что мы хотим оставить 25% выборки), либо изменить гиперпараметры модели, уменьшив количество деревьев и их глубину.
6
Baseline-модель - это простая модель, от которой отталкиваются, чтобы сделать что-то более эффективное, отправная точка для сравнения и улучшения. Обычно обученная без каких-то особенных настроек и подбора гиперпараметров. Ее цель - понять, решаема ли вообще поставленная задача.
7, 8
Директория ./mlflow будет содержать все что связано с данным фреймворком, а также скрипт для ее запуска.
Первоначально нужно установить фреймворк, будем использовать версию 2.16. Кроме того, следует обновить версию numpy до 1.26.4. Не забудьте обновить файл requirements.txt
pip install numpy==1.26.4 mlflow==2.16
Запускать mlflow мы будем локально, с указанием хранилища экспериментов в СУБД sqlite. Команду для запуска мы сохраним в виде bash-скрипта, что поможет вспомнить спустя время, как запустить фреймворк.
Саму команду можно подсмотреть в лекции №4.
Перед запуском mlflow убедитесь что вы находитесь в директории ./mlflow.
Запустить bash-скрипт можно командой:
sh script_name.sh
После запуска убедитесь, что БД создана там же:
my_proj
|_____ .venv_my_proj
|_____ .git
|_____ data
| |___ ...
|
|_____ eda
| |___ ...
|
|_____ research
| |___ research.ipynb
|
|_____ mlflow
| |___ start_mlflow.sh
| |___ mlruns.db
|
|_____ .gitignore
|_____ README.md
|_____ requirements.txt
Проверьте, что фреймворк успешно запустился, пройдя в браузере на http://localhost:5000/
9
Прежде чем приступить непосредственно к логированию, подготовим дополнительные артефакты, которыми обогатим информацию о модели.
- сигнатуру модели
- пример входных данных
- файл
requirements.txt
Пример входных данных можно получить, взяв первые несколько строк исходного датасета, а для сигнатуры - воспользоваться модулем infer_signature:
from mlflow.models import infer_signature
input_example = X_train.head(5)
signature = infer_signature(model_input = X_train.head(5))
Модель нужно логировать со вкусом (flavour) sklearn.
mlflow.sklearn.log_model(...)
Убедитесь, что логирование прошло успешно, открыв интерфейс и проверив, что в эксперименте появился первый Run.
Так же, зарегистрируйте эту модель в качестве первой версии модели по решению текущей задачи. Это можно сделать как через интерфейс, так и с помощью python API.
10
Сгенерируйте новые признаки с помощью различных трансформаций из библиотеки sklearn:
- Для 2-3 числовых признаков PolynomialFeatures. Установить параметр degree=2. Не забудьте, что полученные таким образом признаки сами требуют шкалирования. Обратитесь к примеру из лекций, как поступить в этом случае.
- Если у вас есть признаки, представляющие временные ряды, то SplineTransformer
- Если временных признаков нет, то KBinsDiscretizer для разбивки 2-3 числовых признаков на корзины("бины")
- Возможно, другие на ваше усмотрение.
Для этого:
- Создайте новую переменную
X_train_fe_sklearn- копию исходной обучающей выборки, используя метод.copy()датафрейма. - Создайте
ColumnTransformer, содержащий как трансформации baseline-модели (сделанные в п.5 ЛР), так и новые. - Обучите и сохраните в переменную
X_train_fe_sklearn(используя методfit_transform) получившиеся преобразования. - Сохраните в файл названия столбцов получившегося датафрейма. Этот файл нужно будет залогировать в MLFlow
- Создайте
pipeline, в котором на первом шаге будет работатьColumnTransformer, созданный в этом пункте, а на втором - модель.
Далее нужно обучить модель, сделать предикт и залогировать модель и файл со столбцами, сделанный на шаге 4. Не забудьте поменять RUN_NAME на понятный, соответствующий действиям в этом пункте ЛР.
11 (*)
Сгенерировать новые признаки с помощью библиотеки autofeat используя подходящие трансформации и задав feateng_steps=2
Данная трансформация заменит шаг transform вашего исходного pipeline.
Действия аналогичный предыдущему пункту.
Далее нужно обучить модель, сделать предикт и залогировать модель результаты. Не забудьте поменять RUN_NAME на понятный, соответствующий действиям в этом пункте ЛР.
12
С использованием библиотеки mlxtend отобрать N наиболее важных признаков. N выбирается с учетом количества признаков на предыдущем шаге, ориентировочный диапазон - от 20% до 70%.
В ЛР отбор будем проводить для признаков, полученных трансформациями sklearn в пункте 10.
Алгоритм выполнения пункта следующий:
- Создайте
SequentialFeatureSelectorc направлением последовательным добавлением признаков (forward). - В пункте 10 был получен датафрейм
X_train_fe_sklearn, состоящий из расширенного набора признаков по сравнению с исходными данными. На этом датафрейме обучитеSequentialFeatureSelector. - Выведите на экран и сохраните в файлы названия отобранных столбцов и их индексы (их нужно будет залогировать вместе с моделью)
- Добавьте в папйлайн из пункта 10 вторым шагом отбор столбцов в соответствии с заданными индексами
Далее нужно обучить модель, сделать предикт и залогировать модель и файлы с названиями и индексами отбранных столбцов. Не забудьте поменять RUN_NAME на понятный, соответствующий действиям в этом пункте ЛР.
13 (*)
Повторите предыдущий пункт с SequentialFeatureSelector последовательно удаляя признаки (forward=False), и\или с помощью RFE из sklearn.
Проанализируйте, схожие ли признаки выбраны другим алгоритмом?
Можно провести исследование и попробовать объединить признаки, выбранные разными алгоритмами. Или наоборот - выбрать только те, котрые были выбраны всеми.
14
ИДалее используем модель, которая показала лучший результат.
У Random Forest будем настраивать параметры:
- количество деревьев
- глубина дерева
- max_features в интервале от 0.1 до 1.0
Проведите не менее 10 trails по подбору опитмальных гиперпараметров. Настраивать качество будем по метрике mae для регрессии и f1 для классификации. Обратите внимание и явно укажите в коде на то, что нужно делать с метрикой - максимизировать или минимизировать.
Обученную модель залогируйте в MLFlow. Не забудьте поменять RUN_NAME на понятный, соответствующий действиям в этом пункте ЛР.
Зарегистрируйте модель в качестве второй версии исходной модели. Можно через интерфейс, можно с использованием API.
15 (*)
Обучить модель с помощью алгоритма CatBoost с выбранным вами набором признаков. Пункт аналогичен предыдущему.
Залогируйте модель. Не забудьте воспользоваться оберткой (flavour) catboost.
Зарегистрируйте данную модель как третью версию. Можно через интерфейс, можно с использованием API.
16
Актуализировать файл requirements.txt.
Проанализировать все прогоны и выбрать модель, показывающую наилучшее качество. Обучить эту модель на всей выборке (а не только на train-части), залогировать ее. Метрики качества мерить уже не надо, однако кроме самой модели обязательно должны быть залогированы:
- сигнатура модели
- пример входных данных
- файл
requirements.txt - список используемых столбцов
Зарегистрируйте эту версию в реестре моделей и установите ей тэг Production.
Эту модель мы будем деплоить в следующей лабораторной работе
17
Сохранить в папке research и закоммитить два скриншота из интерфейса mlflow и файл MLModel для Production-модели:
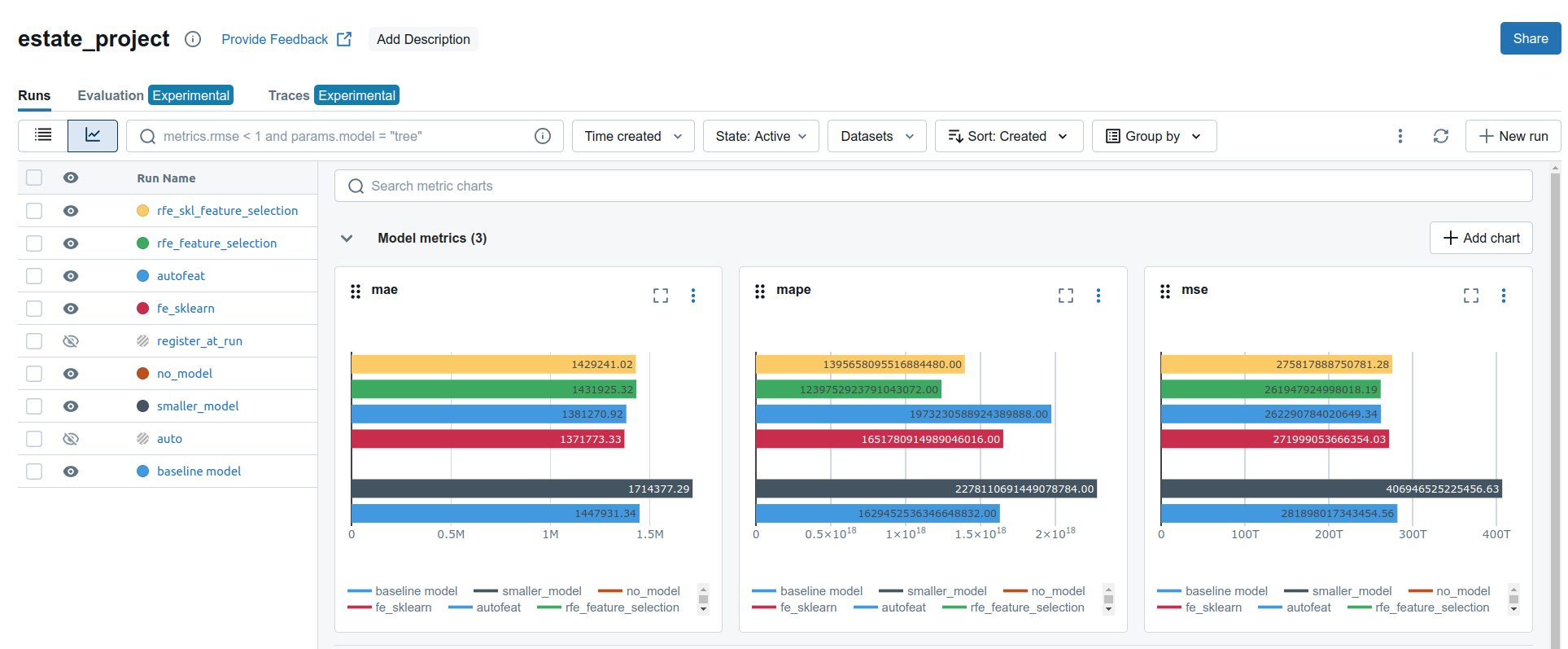
- Скриншот всех прогонов и их графиков с метриками качества.
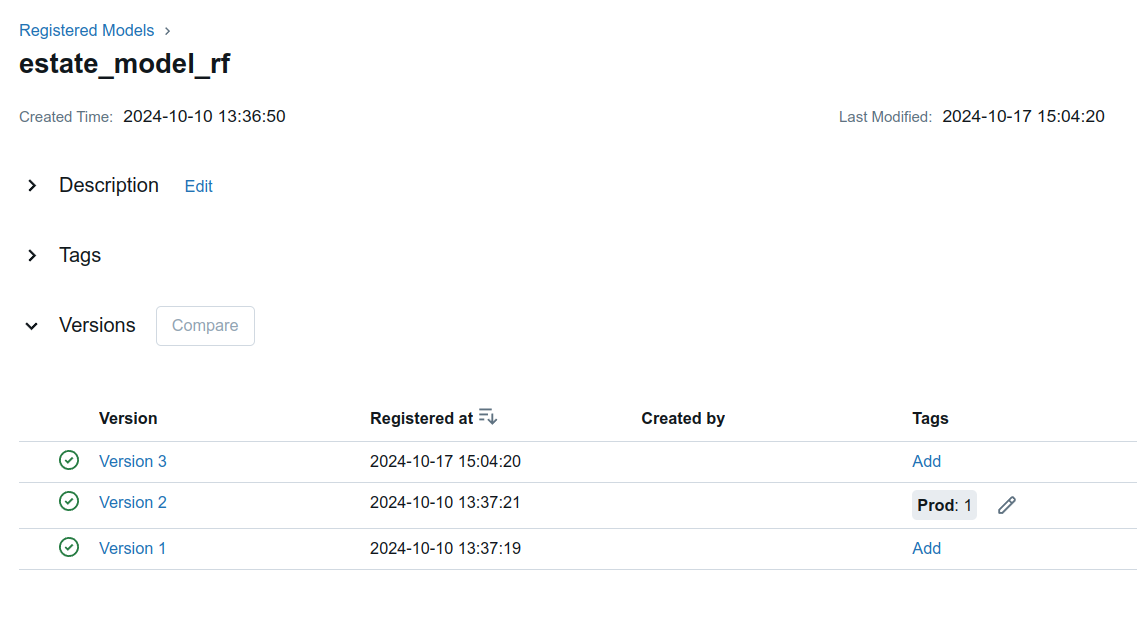
- Скриншот зарегистрированных версий моделей
- Текстовый файл MLModel можно найти и скачать во вкадке
artifactsсоответствующегоrun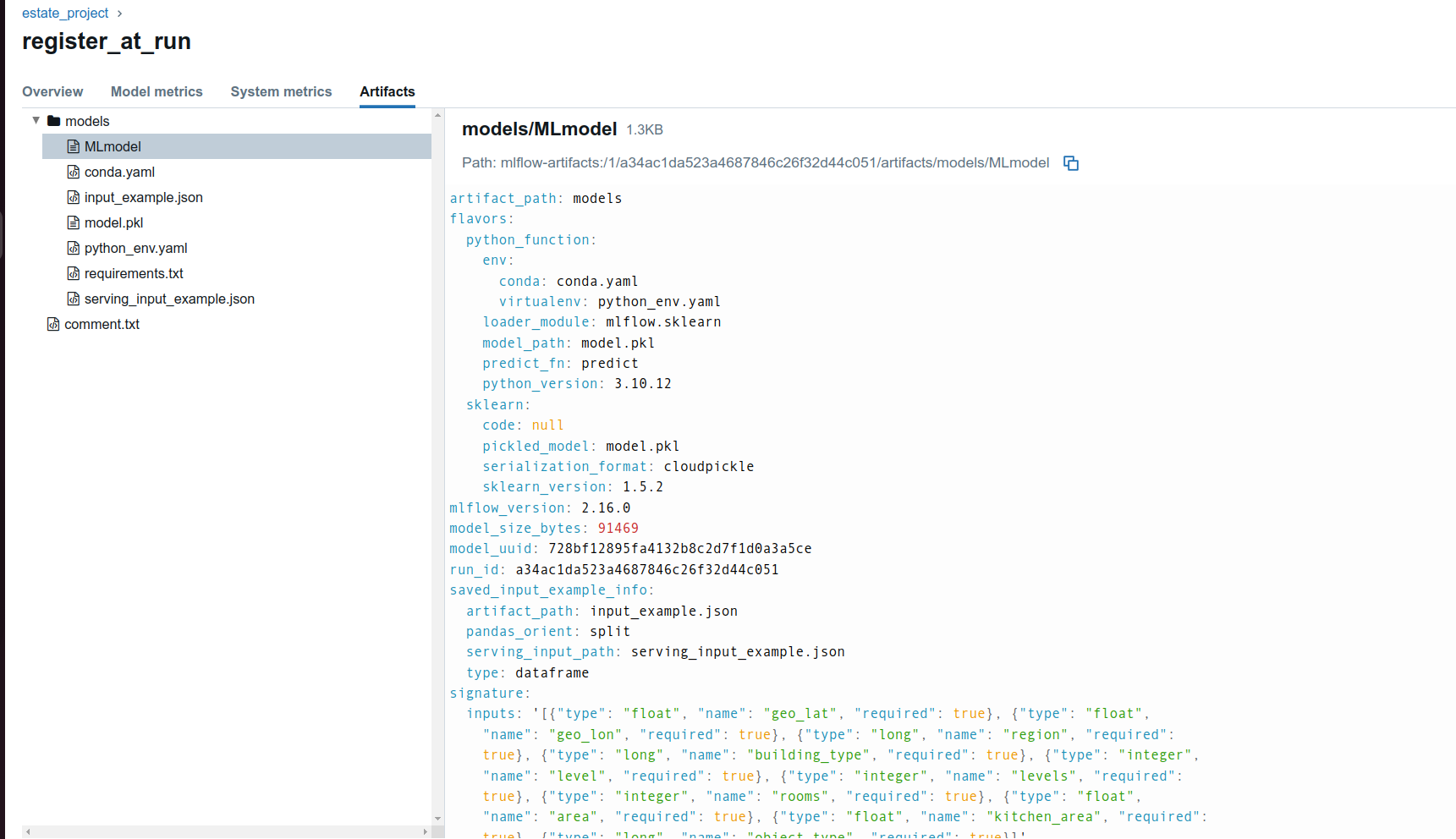
18
Актуализировать файлы README.md, .gitignore.
В Readme нужно
- добавить пункт по запуску MLFlow - где находится скрипт, какой командой его запустить.
- добавить пункт "Результаты исследования" где описать, какая модель показала лучший результат и какой. Ее параметры и выбранные столбцы. Указать
run_idпрогона сProductionмоделью.
В .gitignore добавить в исключения папку с артефактами mlflow, и базу mlruns.db.
Убедитесь, что скрипт по запуску mlflow должен быть обязательно закоммичен!
19
Отправить изменения на github.
Сохранить на флешку или иным способом директорию ./mlflow. Убедитесь, что в ней содержится папка mlartifacts и база mlruns.db
Контрольные вопросы
- Для чего нужен этап feature extraction?
- Для чего нужен этап feature selection?
- Для чего используется фреймворк mlflow?
- Что такое "гиперпараметры модели" для чего и как их настраивать?
- Как выглядит пайплайн работы модели, какие шаги в нем могут быть?