8.4 KiB
Тест по Теме 9 Модуль 3
Володин Денис, А-02-23
Задание (Вариант 1)
M3_1
- Создайте модуль М1, содержащий две функции:
-
функция 1: аргумент - список или кортеж с выборкой; функция должна произвести расчет по выборке оценки её дисперсии DX, а также наименьшего и наибольшего значений и вернуть эти значения в вызывающую программу в виде списка;
-
функция 2: аргументы - два списка или кортежа с выборками X и Y; функция должна произвести с помощью функции 1 расчет статистик по выборкам и рассчитать статистику Фишера: F=DX/DY
- Создайте еще один модуль М2, в котором должны выполняться следующие операции:
-
запрашивается имя бинарного файла с выборками X и Y, проверяется его наличие и при отсутствии - повторяется запрос;
-
выборки считываются из файлов;
-
с помощью функции 1 по выборкам рассчитываются их статистики,
-
с помощью функции 2 рассчитывается значение статистики Фишера,
-
если числа элементов в выборках одинаково, графически отображается поле рассеивания для Х и Y;
-
результаты расчета с соответствующими заголовками выводятся в текстовый файл.
-
Создайте модуль М0 - главную программу, которая вызывает М2 и отображает результаты расчета на экране.
-
Создайте 2 бинарных файла: с выборками одинакового размера и с выборками разного размера. Проверьте программу с использованием этих файлов.
Решение
Создание бинарных файлов
import pickle
import random
from m2 import save_samples
def create_test_files():
print("\n1. Создание файла с выборками одинакового размера:")
sample_x1 = [random.uniform(1, 10) for _ in range(10)]
sample_y1 = [random.uniform(5, 15) for _ in range(10)]
save_samples("test1.pkl", sample_x1, sample_y1)
print("\n2. Создание файла с выборками разного размера:")
sample_x2 = [random.uniform(0, 20) for _ in range(15)]
sample_y2 = [random.uniform(10, 30) for _ in range(8)]
save_samples("test2.pkl", sample_x2, sample_y2)
print("\n1. test1.pkl - одинаковый размер (10 и 10)")
print("2. test2.pkl - разный размер (15 и 8)\n")
create_test_files()
M1
def calculate_stats(sample):
n = len(sample)
mean = sum(sample) / n
var = sum((x - mean) ** 2 for x in sample) / (n - 1) if n > 1 else 0
min_val = min(sample)
max_val = max(sample)
return [var, min_val, max_val]
def calculate_f_statistic(sample_x, sample_y):
stats_x = calculate_stats(sample_x)
stats_y = calculate_stats(sample_y)
dx = stats_x[0]
dy = stats_y[0]
f_statistic = dx / dy
return f_statistic
M2
import os
import pickle
import matplotlib.pyplot as plt
from m1 import calculate_stats, calculate_f_statistic
def save_samples(filename, sample_x, sample_y):
data = {
'sample_x': sample_x,
'sample_y': sample_y,
'info': f"Выборки: X({len(sample_x)}), Y({len(sample_y)})"
}
with open(filename, 'wb') as f:
pickle.dump(data, f)
print(f"Файл сохранен: {filename}")
def read_samples(filename):
with open(filename, 'rb') as f:
data = pickle.load(f)
return data['sample_x'], data['sample_y']
def get_valid_filename():
while True:
filename = input("Введите имя файла с выборками (.pkl): ")
if not filename.endswith('.pkl'):
filename += '.pkl'
if os.path.exists(filename):
return filename
else:
print(f"Файл '{filename}' не найден.")
def show_plot(sample_x, sample_y, filename):
if len(sample_x) != len(sample_y):
print(f"Размеры выборок не совпадают: X={len(sample_x)}, Y={len(sample_y)}")
return
plt.figure(figsize=(8, 6))
plt.scatter(sample_x, sample_y, color='blue', alpha=0.6)
plt.xlabel('Выборка X')
plt.ylabel('Выборка Y')
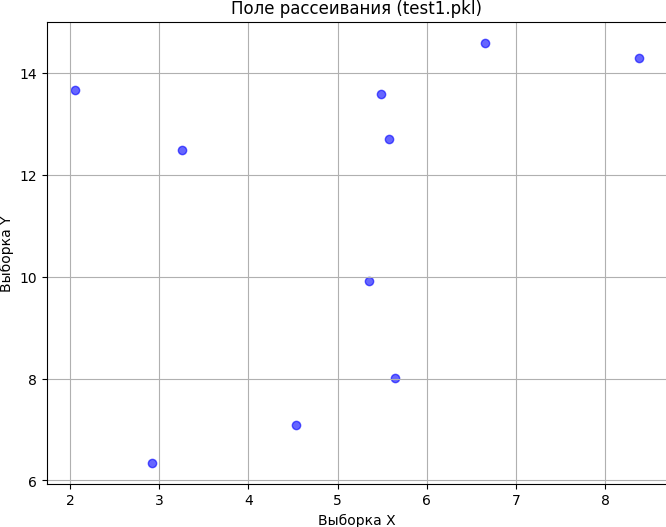
plt.title(f'Поле рассеивания ({filename})')
plt.grid(True)
plt.show()
def process_samples():
filename = get_valid_filename()
print(f"\nЧтение файла: {filename}")
sample_x, sample_y = read_samples(filename)
print(f"Выборка X: {len(sample_x)} элементов")
print(f"Выборка Y: {len(sample_y)} элементов")
stats_x = calculate_stats(sample_x)
stats_y = calculate_stats(sample_y)
f_value = calculate_f_statistic(sample_x, sample_y)
result_file = filename.replace('.pkl', '_results.txt')
with open(result_file, 'w', encoding='utf-8') as f:
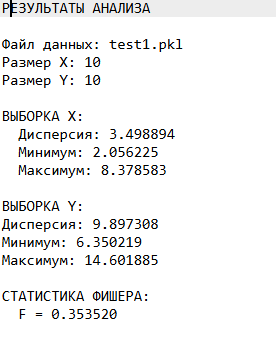
f.write("РЕЗУЛЬТАТЫ АНАЛИЗА\n\n")
f.write(f"Файл данных: {filename}\n")
f.write(f"Размер X: {len(sample_x)}\n")
f.write(f"Размер Y: {len(sample_y)}\n\n")
f.write("ВЫБОРКА X:\n")
f.write(f" Дисперсия: {stats_x[0]:.6f}\n")
f.write(f" Минимум: {stats_x[1]:.6f}\n")
f.write(f" Максимум: {stats_x[2]:.6f}\n\n")
f.write("ВЫБОРКА Y:\n")
f.write(f"Дисперсия: {stats_y[0]:.6f}\n")
f.write(f"Минимум: {stats_y[1]:.6f}\n")
f.write(f"Максимум: {stats_y[2]:.6f}\n\n")
f.write("СТАТИСТИКА ФИШЕРА:\n")
f.write(f" F = {f_value:.6f}\n\n")
if len(sample_x) == len(sample_y):
show_plot(sample_x, sample_y, filename)
return {
'filename': filename,
'x_size': len(sample_x),
'y_size': len(sample_y),
'x_variance': stats_x[0],
'y_variance': stats_y[0],
'f_value': f_value,
'result_file': result_file
}
M0
from m2 import process_samples
results = process_samples()
if results:
print("\n=== РЕЗУЛЬТАТЫ НА ЭКРАНЕ ===")
print(f"Файл: {results['filename']}")
print(f"Размеры: X={results['x_size']}, Y={results['y_size']}")
print(f"\nДисперсия X: {results['x_variance']:.4f}")
print(f"Дисперсия Y: {results['y_variance']:.4f}")
print(f"Статистика Фишера F: {results['f_value']:.4f}")
print("\nПрограмма завершена.")
Результаты
1. Создание файла с выборками одинакового размера:
Файл сохранен: test1.pkl
2. Создание файла с выборками разного размера:
Файл сохранен: test2.pkl
1. test1.pkl - одинаковый размер (10 и 10)
2. test2.pkl - разный размер (15 и 8)
Введите имя файла с выборками (.pkl): test1.pkl
Чтение файла: test1.pkl
Выборка X: 10 элементов
Выборка Y: 10 элементов
=== РЕЗУЛЬТАТЫ НА ЭКРАНЕ ===
Файл: test1.pkl
Размеры: X=10, Y=10
Дисперсия X: 3.4989
Дисперсия Y: 9.8973
Статистика Фишера F: 0.3535
Программа завершена.
Введите имя файла с выборками (.pkl): test2.pkl
Чтение файла: test2.pkl
Выборка X: 15 элементов
Выборка Y: 8 элементов
=== РЕЗУЛЬТАТЫ НА ЭКРАНЕ ===
Файл: test2.pkl
Размеры: X=15, Y=8
Дисперсия X: 55.5074
Дисперсия Y: 28.3171
Статистика Фишера F: 1.9602
Программа завершена.