14 KiB
Лабораторная работа №2: Обнаружение аномалий с помощью автокодировщиков
Ватьков А..С., Харисов С.Р. — А-01-22
Вариант 2 (номер бригады k=2) - данные WBC
Цель работы
Получить практические навыки создания, обучения и применения искусственных нейронных сетей типа автокодировщик. Исследовать влияние архитектуры автокодировщика и количества эпох обучения на области в пространстве признаков, распознаваемые автокодировщиком после обучения. Научиться оценивать качество обучения автокодировщика на основе ошибки реконструкции и новых метрик EDCA. Научиться решать актуальную задачу обнаружения аномалий в данных с помощью автокодировщика как одноклассового классификатора.
Определение варианта
- Номер бригады: k = 2
- N = k mod 3 = 2 mod 3 = 2
- Вариант 2 => данные WBC
ЗАДАНИЕ 1: Работа с двумерными синтетическими данными
Импорт библиотек и настройка окружения
import os
# скачивание библиотеки!
!wget -N http://uit.mpei.ru/git/main/is_dnn/src/branch/main/labworks/LW2/lab02_lib.py
# скачивание выборок!
!wget -N http://uit.mpei.ru/git/main/is_dnn/src/branch/main/labworks/LW2/data/WBC_train.txt
!wget -N http://uit.mpei.ru/git/main/is_dnn/src/branch/main/labworks/LW2/data/WBC_test.txt
import numpy as np
import lab02_lib as lib
# Параметры для варианта 2 (номер бригады k=2)
k = 2 # номер бригады
center_coords = (k, k) # координаты центра (2, 2)
Описание: Импортируются необходимые библиотеки и устанавливаются параметры для варианта 2.
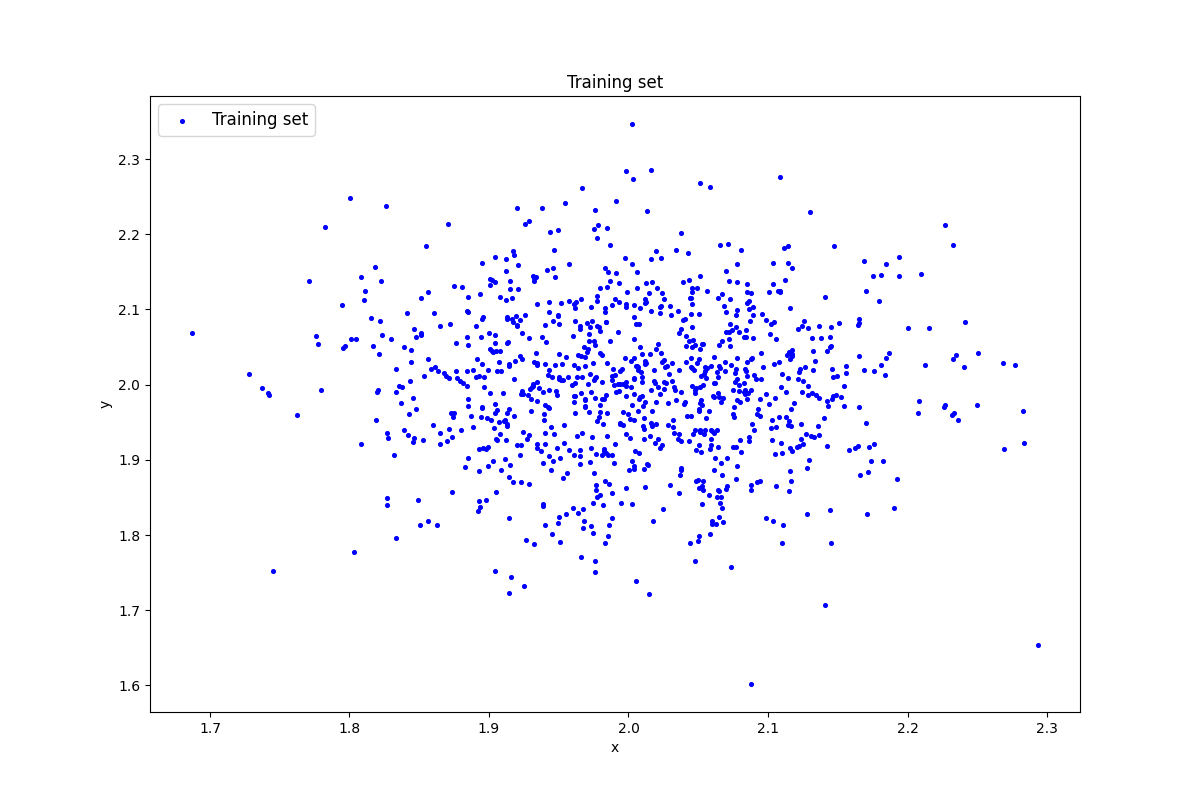
Генерация индивидуального набора двумерных данных
#генерация датасета
data=lib.datagen(2,2,1000,2)
#вывод данных и размерности
print('Исходные данные:')
print(data)
print('Размерность данных:')
print(data.shape)
Результат выполнения:
Исходные данные:
[[2.08491429 2.01121585]
[2.01546644 1.93123649]
[1.93034485 1.96549809]
...
[2.02320357 2.16782607]
[2.1109127 1.81313673]
[2.13031577 2.22961484]]
Размерность данных:
(1000, 2)
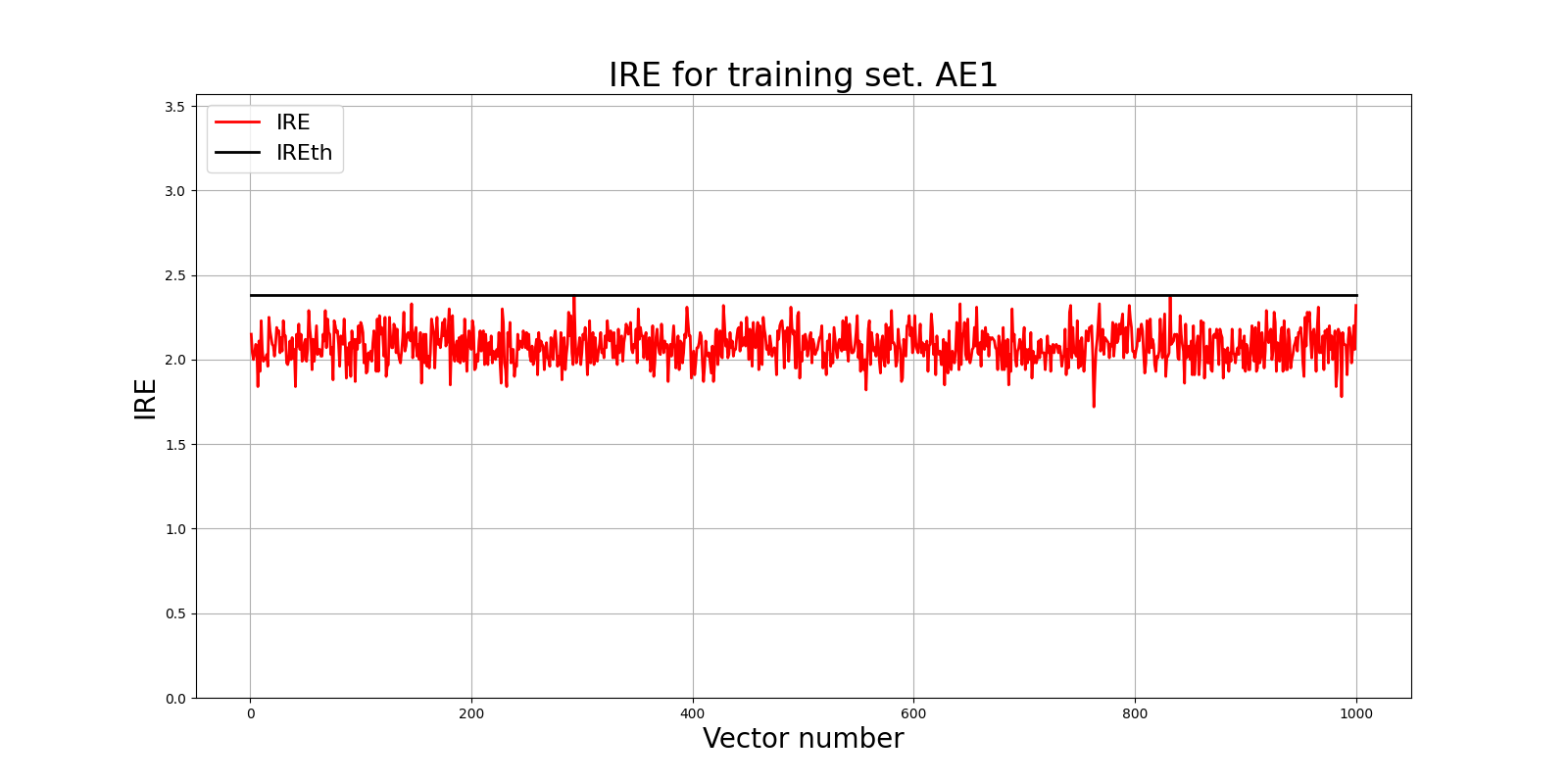
Создание и обучение автокодировщика AE1
patience= 300
ae1_trained, IRE1, IREth1= lib.create_fit_save_ae(data,'out/AE1.h5','out/AE1_ire_th.txt', 300, True, patience)
#Построение графика ошибки реконструкции
lib.ire_plot('training', IRE1, IREth1, 'AE1')
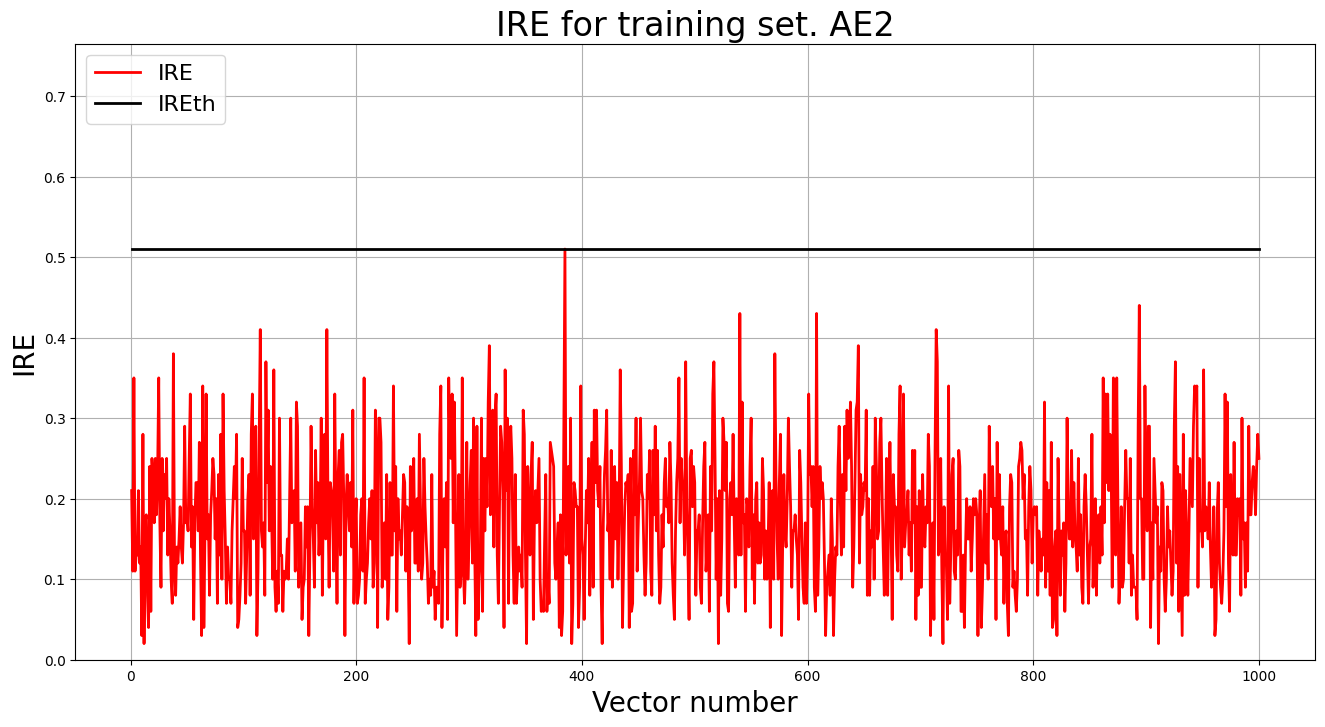
Создание и обучение автокодировщика AE2
# обучение AE2
ae2_trained, IRE2, IREth2= lib.create_fit_save_ae(data,'out/AE2.h5','out/AE2_ire_th.txt', 500, True, patience)
lib.ire_plot('training', IRE2, IREth2, 'AE2')
Расчет характеристик качества обучения автокодировщиков
#построение областей покрытия и границ классов
#расчет характеристик качества обучения
numb_square= 20
xx,yy,Z1=lib.square_calc(numb_square,data,ae1_trained,IREth1,'1',True)
Результат выполнения:
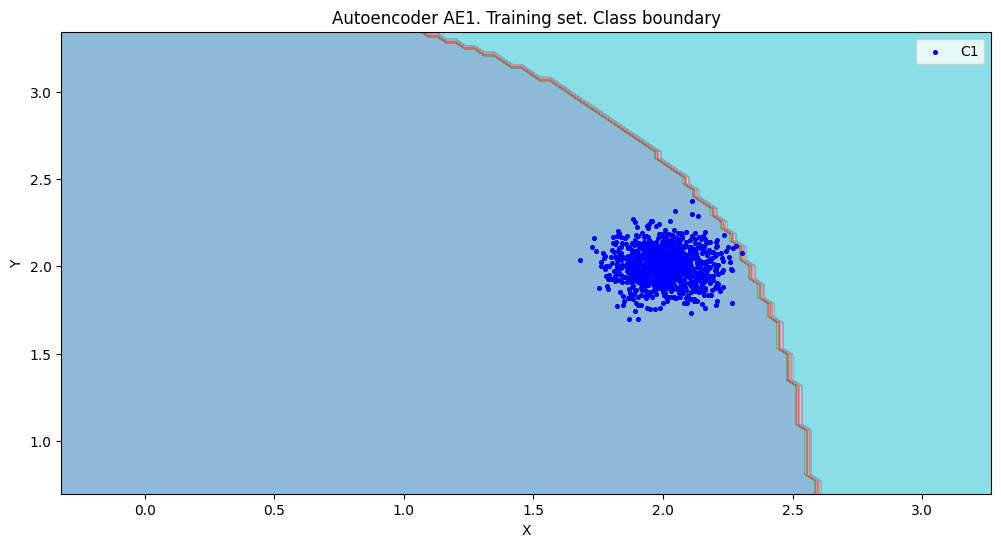
amount: 19
amount_ae: 284
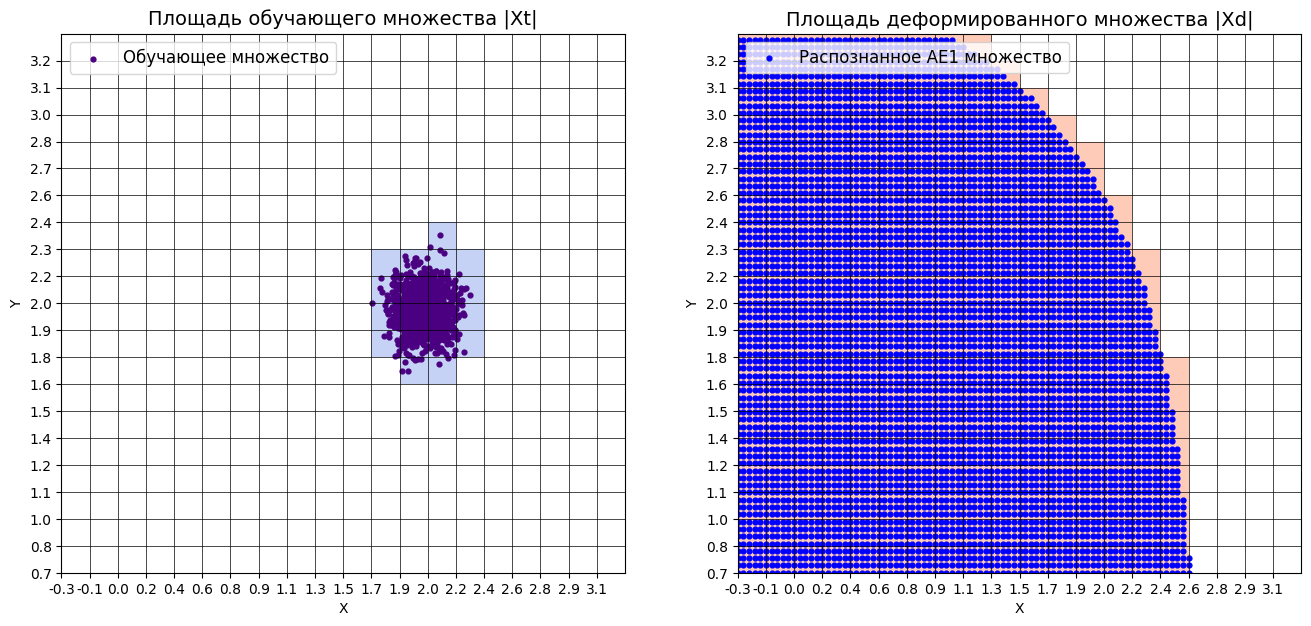

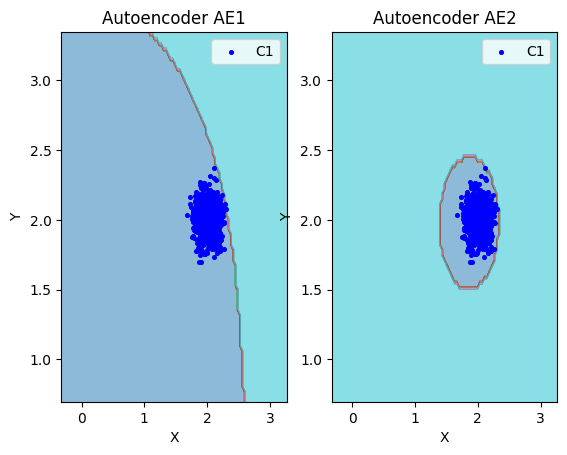
Оценка качества AE1
IDEAL = 0. Excess: 13.947368421052632
IDEAL = 0. Deficit: 0.0
IDEAL = 1. Coating: 1.0
summa: 1.0
IDEAL = 1. Extrapolation precision (Approx): 0.06690140845070422
#построение областей покрытия и границ классов
#расчет характеристик качества обучения
numb_square= 20
xx,yy,Z2=lib.square_calc(numb_square,data,ae2_trained,IREth2,'2',True)
Результат выполнения:
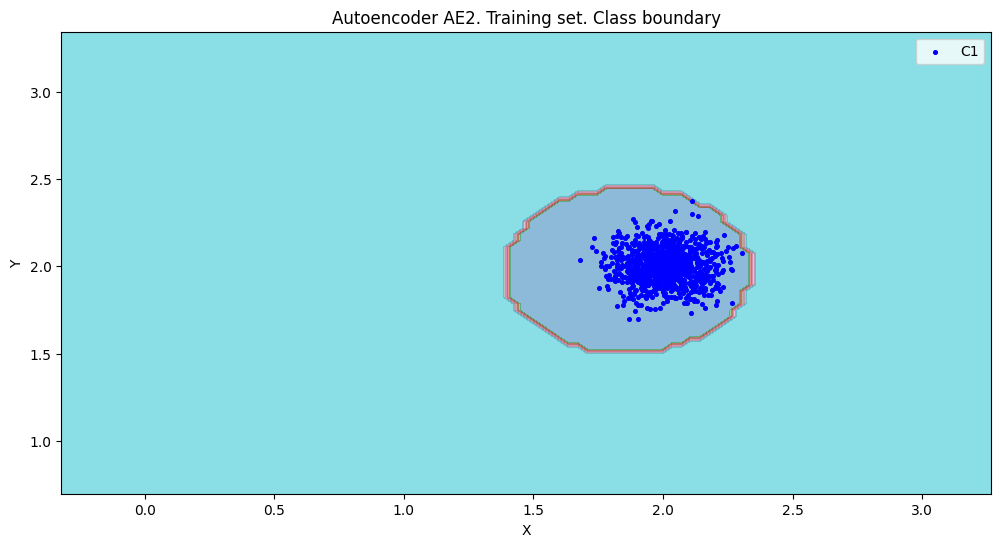
amount: 19
amount_ae: 40
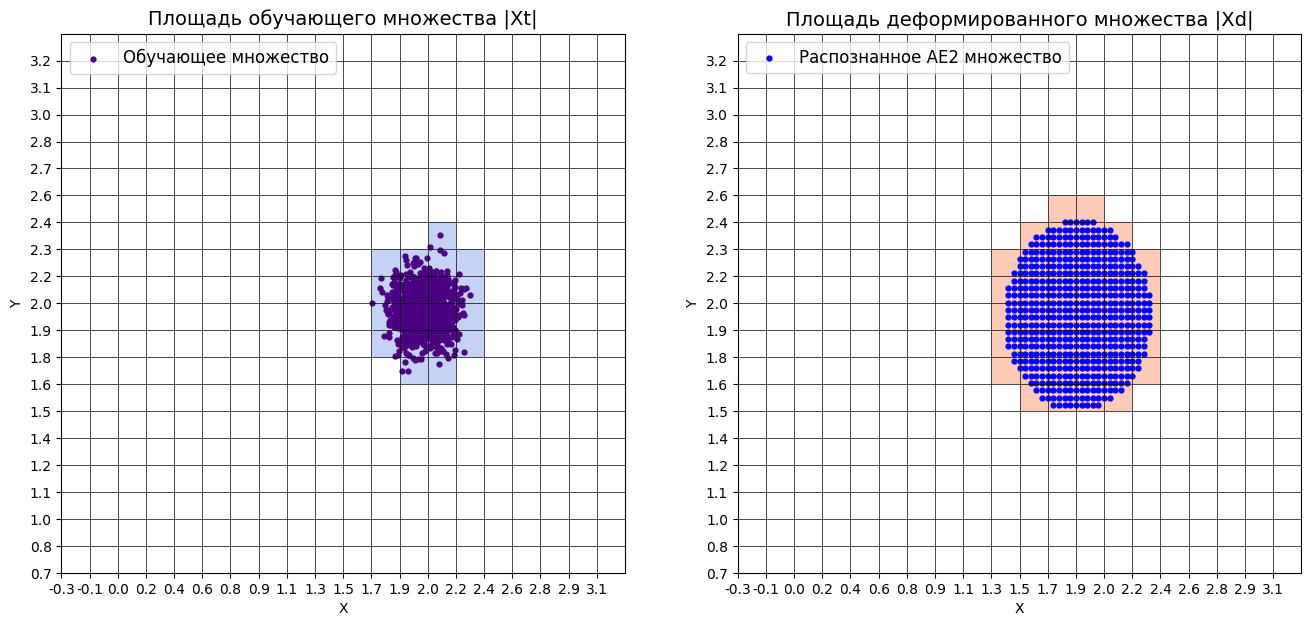
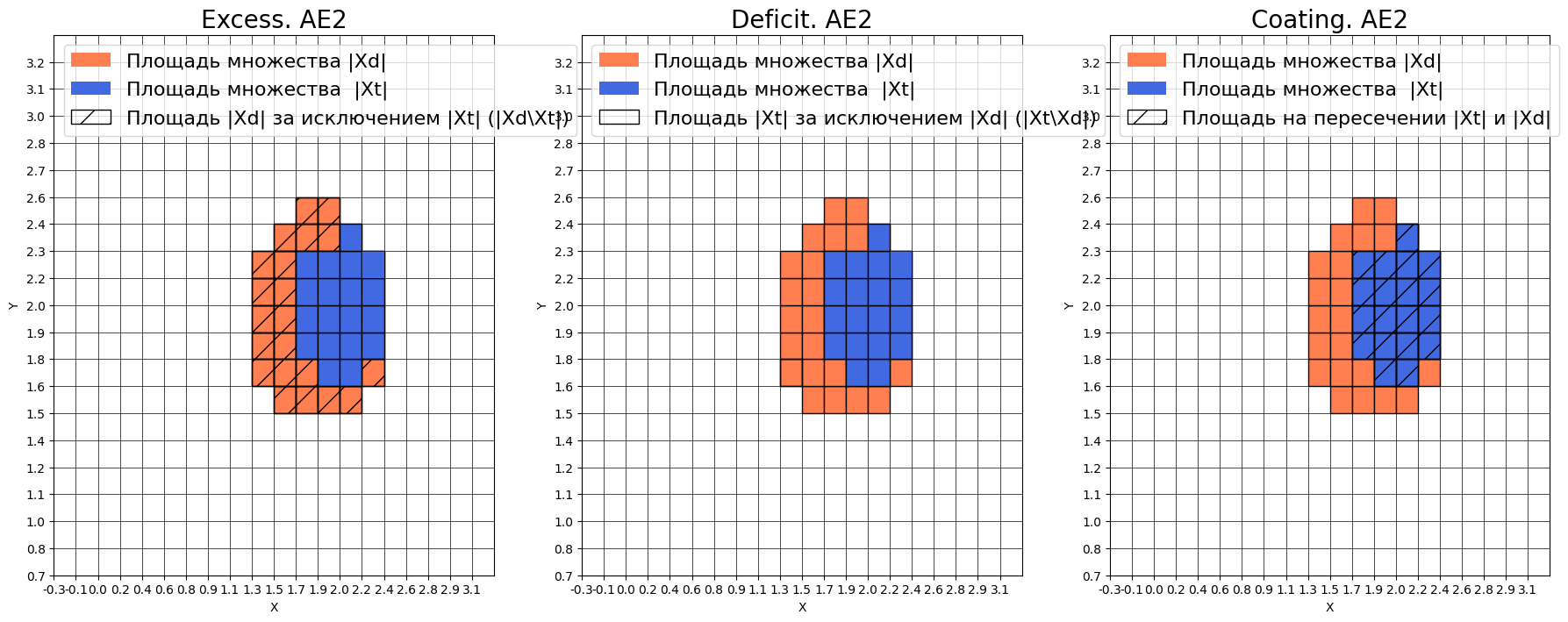
Оценка качества AE2
IDEAL = 0. Excess: 1.105263157894737
IDEAL = 0. Deficit: 0.0
IDEAL = 1. Coating: 1.0
summa: 1.0
IDEAL = 1. Extrapolation precision (Approx): 0.475
#сравнение характеристик качестваобучения и областей аппроксимации
lib.plot2in1(data,xx,yy,Z1,Z2)
Тестирование автокодировщиков
#загрузка тестового набора
data_test= np.loadtxt('data_test.txt', dtype=float)
#тестирование АE1
predicted_labels1, ire1 = lib.predict_ae(ae1_trained, data_test, IREth1)
#тестирование АE2
predicted_labels2, ire2 = lib.predict_ae(ae2_trained, data_test, IREth2)
#построение областей аппроксимации и точек тестового набора
lib.plot2in1_anomaly(data, xx, yy, Z1, Z2, data_test)

ЗАДАНИЕ 2: Работа с реальными данными WBC
Загрузка и изучение данных WBC
# Загрузка выборок
train = np.loadtxt('WBC_train.txt', dtype=float)
test = np.loadtxt('WBC_test.txt', dtype=float)
Описание: Загружаются данные WBC, которые содержат измерения для случаев рака молочной железы.
Создание и обучение автокодировщика
from time import time
start = time()
ae3_trained, IRE3, IREth3= lib.create_fit_save_ae(train,'out/AE3.h5','out/AE3_ire_th.txt', 50000, False, 5000, early_stopping_delta = 0.01)
IREth3 = np.percentile(IRE3, 95)
print("Время на обучение: ", time() - start)
print("Порог IREth3:", IREth3)
Результаты обучения: Время на обучение: 192.4243025779724 Порог IREth3: 0.4819999999999999
predicted_labels3, ire3 = lib.predict_ae(ae3_trained, test, IREth3)
Тестирование автокодировщика
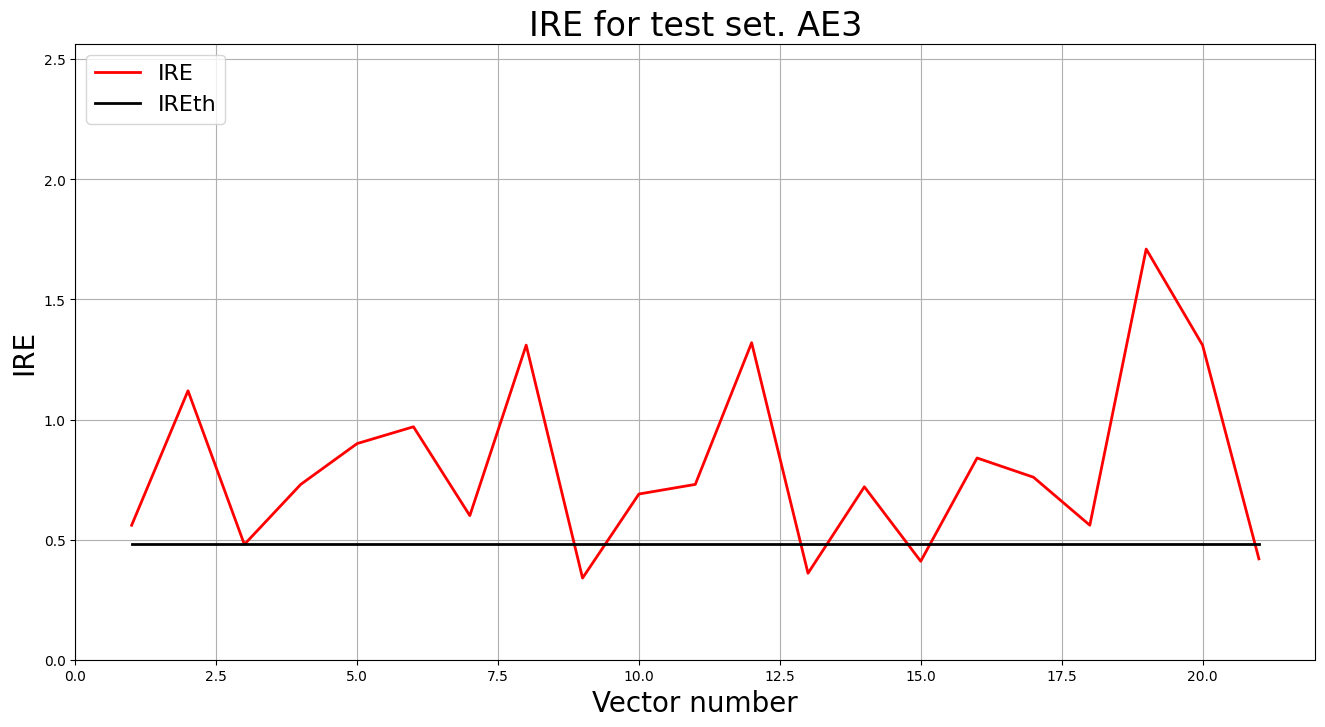
lib.anomaly_detection_ae(predicted_labels3, ire3, IREth3)
lib.ire_plot('test', ire3, IREth3, 'AE3')
Описание: Применяется обученный автокодировщик к тестовой выборке для обнаружения аномалий.
Результаты обнаружения аномалий:
i Labels IRE IREth
0 [1.] [0.56] 0.48
1 [1.] [1.12] 0.48
2 [0.] [0.48] 0.48
3 [1.] [0.73] 0.48
4 [1.] [0.9] 0.48
5 [1.] [0.97] 0.48
6 [1.] [0.6] 0.48
7 [1.] [1.31] 0.48
8 [0.] [0.34] 0.48
9 [1.] [0.69] 0.48
10 [1.] [0.73] 0.48
11 [1.] [1.32] 0.48
12 [0.] [0.36] 0.48
13 [1.] [0.72] 0.48
14 [0.] [0.41] 0.48
15 [1.] [0.84] 0.48
16 [1.] [0.76] 0.48
17 [1.] [0.56] 0.48
18 [1.] [1.71] 0.48
19 [1.] [1.31] 0.48
20 [0.] [0.42] 0.48
Обнаружено 16.0 аномалий
ИТОГОВЫЕ РЕЗУЛЬТАТЫ
Таблица 1 - Результаты задания №1
| Модель | Количество скрытых слоев | Количество нейронов в скрытых слоях | Количество эпох обучения | Ошибка MSE_stop | Порог ошибки реконструкции | Значение показателя Excess | Значение показателя Approx | Количество обнаруженных аномалий |
|---|---|---|---|---|---|---|---|---|
| AE1 | 1 | 1 | 300 | 2.0432 | 2.3 | 13.947368421052632 | 0.06690140845070422 | - |
| AE2 | 5 | 3-2-1-2-3 | 500 | 0.0196 | 0.515 | 1.105263157894737 | 0.475 | - |
Таблица 2 - Результаты задания №2
| Dataset name | Количество скрытых слоев | Количество нейронов в скрытых слоях | Количество эпох обучения | Ошибка MSE_stop | Порог ошибки реконструкции | % обнаруженных аномалий |
|---|---|---|---|---|---|---|
| WBC | 9 | 28-24-20-16-12-16-20-24-28 | 50000 | 0.0003 | 0.482 | 76.2% |
ВЫВОДЫ
Требования к данным для обучения:
- Данные должны быть нормализованными для сохранения стабильности обучения
- В обучающей выборке не должно быть аномальных образцов
- Размер выборки должен быть достаточным для обучения (минимум несколько сотен образцов)
Требования к архитектуре автокодировщика:
- Простая архитектура (AE1): подходит для простых задач, быстро обучается, но может не улавливать сложные зависимости
- Сложная архитектура (AE2): лучше аппроксимирует данные, но требует больше времени на обучение
- Еще более сложная архитектура (AE3): позволяет наиболее точно обнаруживать аномалии и свести ошибку к минимуму, но тратит на обучение много времени из-за большого кол-ва эпох
Требования к количеству эпох обучения:
- AE1 (300 эпох): недостаточно для качественного обучения
- AE2 (500 эпох): обеспечивает хорошую сходимость
- Для реальных данных (WBC) необходимо не менее 50000 эпох
Требования к ошибке MSE_stop:
- AE1: 2.0432 - слишком высокая, указывает на недообучение
- AE2: 0.0196 - приемлемая для синтетических данных
- WBC: 0.0003 - низкая ошибка обучения говорит о возможном переобучении
Требования к порогу обнаружения аномалий:
- Порог 95-го перцентиля обеспечивает разумный баланс
- AE1: 2.3 - слишком высокий, может пропускать аномалии
- AE2: 0.515 - более чувствительный к аномалиям
- WBC: 0.482 - подходящий для реальных данных
Характеристики качества обучения EDCA:
- Более сложная архитектура (AE2) показывает лучшие результаты
- Увеличение количества эпох обучения улучшает качество аппроксимации
- Для качественного обнаружения аномалий необходимо тщательно подбирать параметры модели