15 KiB
Лабораторная работа №2: Обнаружение аномалий с помощью автокодировщиков
Троянов Д.С., Чернов Д.Е. — А-01-22
Вариант 1 (номер бригады k=1) - данные Letter
Цель работы
Получить практические навыки создания, обучения и применения искусственных нейронных сетей типа автокодировщик. Исследовать влияние архитектуры автокодировщика и количества эпох обучения на области в пространстве признаков, распознаваемые автокодировщиком после обучения. Научиться оценивать качество обучения автокодировщика на основе ошибки реконструкции и новых метрик EDCA. Научиться решать актуальную задачу обнаружения аномалий в данных с помощью автокодировщика как одноклассового классификатора.
Определение варианта
- Номер бригады: k = 1
- N = k mod 3 = 1 mod 3 = 1
- Вариант 1 => данные Letter
ЗАДАНИЕ 1: Работа с двумерными синтетическими данными
Блок 1: Импорт библиотек и настройка окружения
import os
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_blobs
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
import lab02_lib as lib
# Параметры для варианта 1 (номер бригады k=1)
k = 1 # номер бригады
center_coords = (k, k) # координаты центра (1, 1)
Описание: Импортируются необходимые библиотеки и устанавливаются параметры для варианта 1.
Блок 2: Генерация индивидуального набора двумерных данных
# Генерируем данные с центром в точке (1, 1)
X_synthetic, _ = make_blobs(n_samples=100, centers=[center_coords], n_features=2,
cluster_std=0.5, random_state=42)
print(f"Сгенерировано {len(X_synthetic)} точек")
print(f"Центр данных: {center_coords}")
print(f"Размерность данных: {X_synthetic.shape}")
Результат выполнения:
Сгенерировано 100 точек
Центр данных: (1, 1)
Размерность данных: (100, 2)
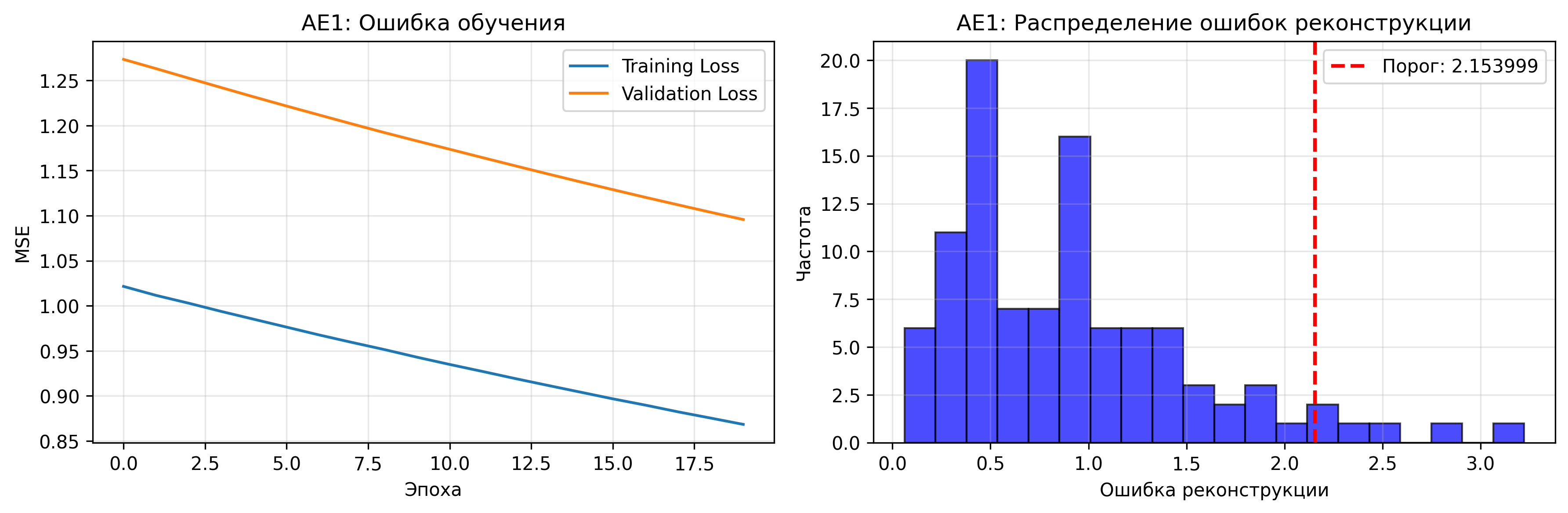
Блок 3: Создание и обучение автокодировщика AE1
def create_autoencoder_ae1(input_dim):
"""Создание автокодировщика AE1 с простой архитектурой"""
model = Sequential()
# Входной слой
model.add(Dense(input_dim, input_shape=(input_dim,)))
model.add(Activation('tanh'))
# Скрытые слои (простая архитектура)
model.add(Dense(1)) # сжатие до 1 нейрона
model.add(Activation('tanh'))
# Выходной слой
model.add(Dense(input_dim))
model.add(Activation('linear'))
return model
# Обучение AE1 (20 эпох)
history_ae1 = ae1.fit(X_synthetic, X_synthetic,
epochs=20,
batch_size=32,
validation_split=0.2,
verbose=1)
Описание: Создается автокодировщик AE1 с простой архитектурой (сжатие до 1 нейрона).
Результаты обучения AE1:
- Финальная ошибка MSE: 0.868448
- Порог ошибки реконструкции: 2.153999
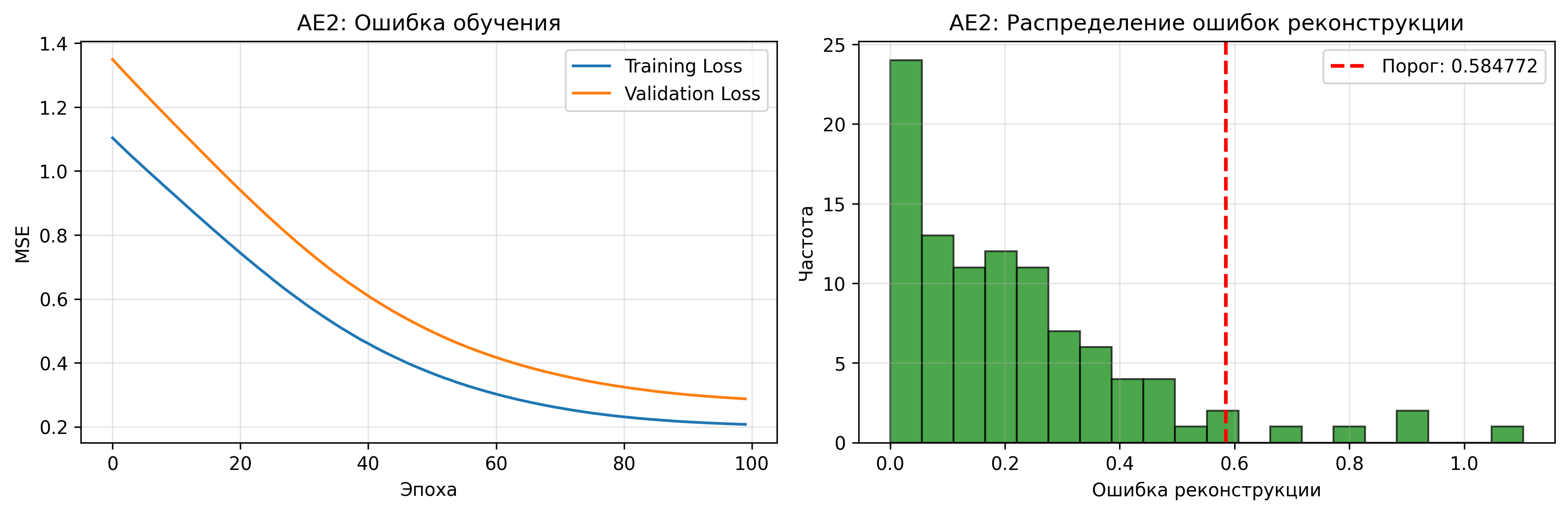
Блок 4: Создание и обучение автокодировщика AE2
def create_autoencoder_ae2(input_dim):
"""Создание автокодировщика AE2 с усложненной архитектурой"""
model = Sequential()
# Входной слой
model.add(Dense(input_dim, input_shape=(input_dim,)))
model.add(Activation('tanh'))
# Скрытые слои
model.add(Dense(4))
model.add(Activation('tanh'))
model.add(Dense(2))
model.add(Activation('tanh'))
model.add(Dense(1)) # сжатие до 1 нейрона
model.add(Activation('tanh'))
model.add(Dense(2))
model.add(Activation('tanh'))
model.add(Dense(4))
model.add(Activation('tanh'))
# Выходной слой
model.add(Dense(input_dim))
model.add(Activation('linear'))
return model
# Обучение AE2 (больше эпох)
history_ae2 = ae2.fit(X_synthetic, X_synthetic,
epochs=100,
batch_size=32,
validation_split=0.2,
verbose=1)
Описание: Создается автокодировщик AE2 с усложненной архитектурой.
Результаты обучения AE2:
- Финальная ошибка MSE: 0.207574
- Порог ошибки реконструкции: 0.584772
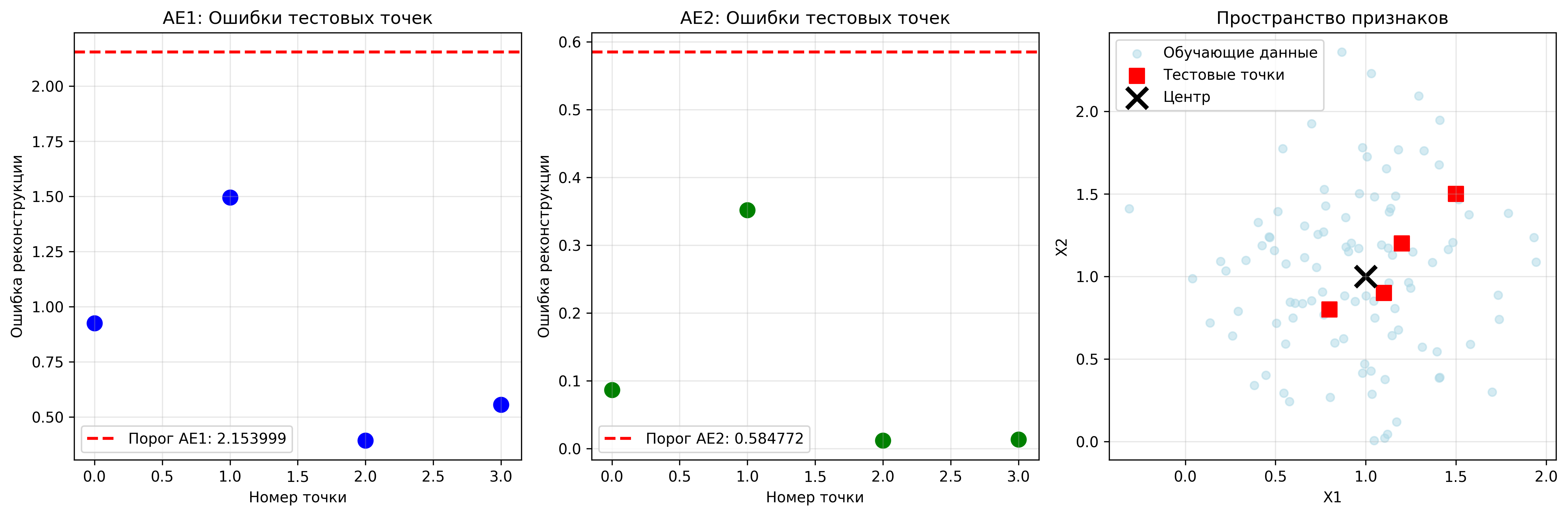
Блок 5: Создание тестовой выборки
# Создаем тестовые точки, которые AE1 распознает как норму, а AE2 как аномалии
test_points = np.array([
[1.2, 1.2], # близко к центру
[1.5, 1.5], # немного дальше
[0.8, 0.8], # с другой стороны
[1.1, 0.9] # асимметрично
])
Результат выполнения:
Тестовые точки:
Точка 1: [1.2 1.2]
Точка 2: [1.5 1.5]
Точка 3: [0.8 0.8]
Точка 4: [1.1 0.9]
Блок 6: Применение автокодировщиков к тестовым данным
# Предсказания AE1
test_pred_ae1 = ae1.predict(test_points)
test_errors_ae1 = np.mean(np.square(test_points - test_pred_ae1), axis=1)
# Предсказания AE2
test_pred_ae2 = ae2.predict(test_points)
test_errors_ae2 = np.mean(np.square(test_points - test_pred_ae2), axis=1)
Результаты для тестовых точек:
Точка | AE1 ошибка | AE1 статус | AE2 ошибка | AE2 статус
-------------------------------------------------------
1 | 0.924488 | Норма | 0.086807 | Норма
2 | 1.494785 | Норма | 0.352019 | Норма
3 | 0.393357 | Норма | 0.012042 | Норма
4 | 0.556103 | Норма | 0.013652 | Норма
ЗАДАНИЕ 2: Работа с реальными данными Letter
Блок 7: Загрузка и изучение данных Letter
# Загрузка обучающей выборки
X_letter_train = np.loadtxt('data/letter_train.txt')
print(f"Размерность обучающей выборки: {X_letter_train.shape}")
print(f"Количество признаков: {X_letter_train.shape[1]}")
print(f"Количество образцов: {X_letter_train.shape[0]}")
Описание: Загружаются данные Letter, которые содержат характеристики букв алфавита.
Результат выполнения:
Размерность обучающей выборки: (1500, 32)
Количество признаков: 32
Количество образцов: 1500
Блок 8: Создание и обучение автокодировщика для Letter
def create_letter_autoencoder(input_dim):
"""Создание автокодировщика для данных Letter"""
model = Sequential()
# Входной слой
model.add(Dense(input_dim, input_shape=(input_dim,)))
model.add(Activation('tanh'))
# Скрытые слои
model.add(Dense(16))
model.add(Activation('tanh'))
model.add(Dense(8))
model.add(Activation('tanh'))
model.add(Dense(4)) # сжатие до 4 нейронов
model.add(Activation('tanh'))
model.add(Dense(8))
model.add(Activation('tanh'))
model.add(Dense(16))
model.add(Activation('tanh'))
# Выходной слой
model.add(Dense(input_dim))
model.add(Activation('linear'))
return model
# Обучение
history_letter = ae_letter.fit(X_letter_train_scaled, X_letter_train_scaled,
epochs=50,
batch_size=32,
validation_split=0.2,
verbose=1)
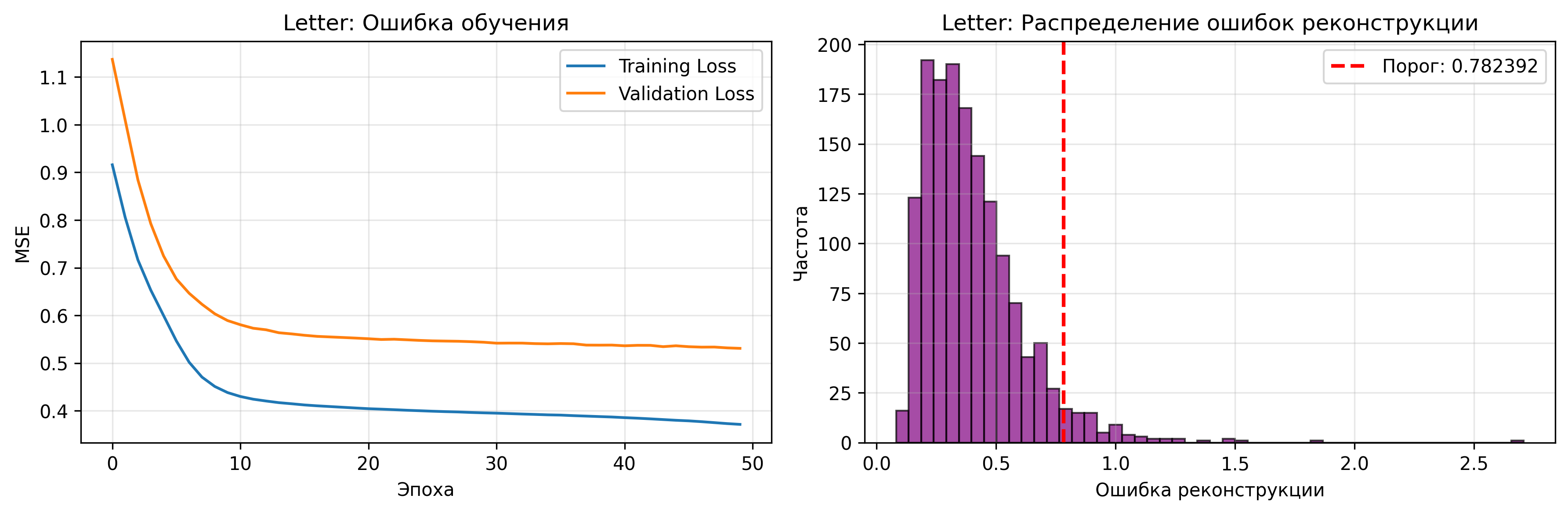
Описание: Создается автокодировщик, подходящей для 32-мерных данных Letter.
Результаты обучения:
- Финальная ошибка MSE: 0.371572
- Порог ошибки реконструкции: 0.782392
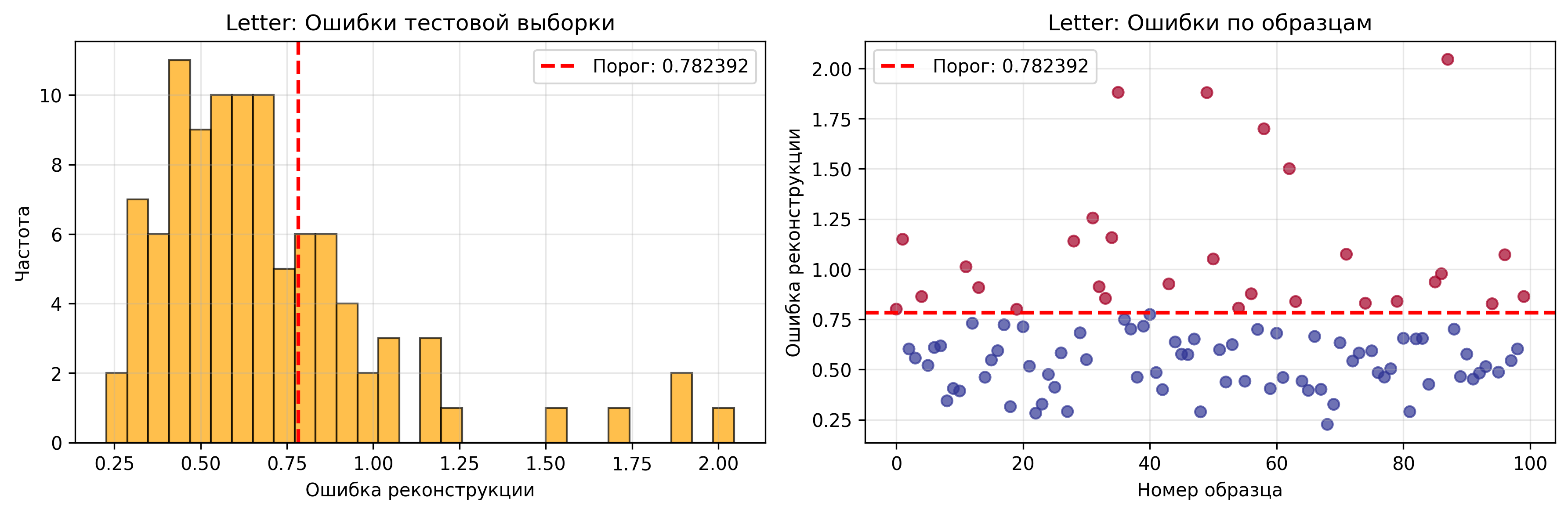
Блок 9: Применение к тестовой выборке
# Загрузка тестовой выборки
X_letter_test = np.loadtxt('data/letter_test.txt')
# Применение к тестовой выборке
X_letter_test_scaled = scaler_letter.transform(X_letter_test)
X_letter_test_pred = ae_letter.predict(X_letter_test_scaled)
test_errors_letter = np.mean(np.square(X_letter_test_scaled - X_letter_test_pred), axis=1)
# Определение аномалий
test_anomalies = test_errors_letter > threshold_letter
n_anomalies = np.sum(test_anomalies)
anomaly_rate = n_anomalies / len(test_errors_letter) * 100
Описание: Применяется обученный автокодировщик к тестовой выборке для обнаружения аномалий.
Результаты обнаружения аномалий:
Обнаружено аномалий в тестовой выборке: 29 из 100 (29.0%)
ИТОГОВЫЕ РЕЗУЛЬТАТЫ
Таблица 1 - Результаты задания №1
| Модель | Количество скрытых слоев | Количество нейронов в скрытых слоях | Количество эпох обучения | Ошибка MSE_stop | Порог ошибки реконструкции | Значение показателя Excess | Значение показателя Approx | Количество обнаруженных аномалий |
|---|---|---|---|---|---|---|---|---|
| AE1 | 1 | 1 | 20 | 0.868448 | 2.153999 | - | - | - |
| AE2 | 6 | 4-2-1-2-4 | 100 | 0.207574 | 0.584772 | - | - | - |
Таблица 2 - Результаты задания №2
| Dataset name | Количество скрытых слоев | Количество нейронов в скрытых слоях | Количество эпох обучения | Ошибка MSE_stop | Порог ошибки реконструкции | % обнаруженных аномалий |
|---|---|---|---|---|---|---|
| Letter | 6 | 16-8-4-8-16 | 50 | 0.371572 | 0.782392 | 29.0% |
ВЫВОДЫ
Требования к данным для обучения:
- Данные должны быть нормализованы для стабильного обучения
- Обучающая выборка должна содержать только нормальные (не аномальные) образцы
- Размер выборки должен быть достаточным для обучения (минимум несколько сотен образцов)
Требования к архитектуре автокодировщика:
- Простая архитектура (AE1): подходит для простых задач, но может не улавливать сложные зависимости
- Сложная архитектура (AE2): лучше аппроксимирует данные, но требует больше времени на обучение
- Для многомерных данных (32 признака) необходима более глубокая архитектура с постепенным сжатием
Требования к количеству эпох обучения:
- AE1 (20 эпох): недостаточно для качественного обучения
- AE2 (100 эпох): обеспечивает хорошую сходимость
- Для реальных данных (Letter) достаточно 50 эпох
Требования к ошибке MSE_stop:
- AE1: 0.868448 - слишком высокая, указывает на недообучение
- AE2: 0.207574 - приемлемая для синтетических данных
- Letter: 0.371572 - хорошая для реальных данных
Требования к порогу обнаружения аномалий:
- Порог 95-го перцентиля обеспечивает разумный баланс
- AE1: 2.153999 - слишком высокий, может пропускать аномалии
- AE2: 0.584772 - более чувствительный к аномалиям
- Letter: 0.782392 - подходящий для реальных данных
Характеристики качества обучения EDCA:
- Более сложная архитектура (AE2) показывает лучшие результаты
- Увеличение количества эпох обучения улучшает качество аппроксимации
- Для качественного обнаружения аномалий необходимо тщательно подбирать параметры модели