23 KiB
Отчёт по лабораторной работе №1
Троянов Д.С., Чернов Д.Е. — А-01-22
1) В среде Google Colab создали блокнот. Импортировали необходимые библиотеки и модули.
# импорт модулей
import tensorflow as tf
from tensorflow import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import os
# Укажем текущую директорию
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_dnn/labworks/LW1')
2) Загрузили набор данных MNIST, содержащий размеченные изображения рукописных цифр.
# Загрузка датасета
(X_train_orig, y_train_orig), (X_test_orig, y_test_orig) = mnist.load_data()
3) Разбили набор данных на обучающие и тестовые данные в соотношении 60 000:10 000 элементов.
При разбиении параметр random_state выбрали равным (4k – 1), где k - номер бригады, k = 6 ⇒ random_state = 23.
# разбиваем выборку на обучающую и тестовую выборку
X = np.concatenate((X_train_orig, X_test_orig))
y = np.concatenate((y_train_orig, y_test_orig))
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=10000,
train_size=60000,
random_state=3,
)
# вывод размерности массивов данных
print('Shape of X train:', X_train.shape)
print('Shape of y train:', y_train.shape)
print('Shape of X test:', X_test.shape)
print('Shape of y test:', y_test.shape)
Shape of X train: (60000, 28, 28)
Shape of y train: (60000,)
Shape of X test: (10000, 28, 28)
Shape of y test: (10000,)
4) Вывели первые 4 элемента обучающих данных (изображения и метки цифр).
# Вывод первых 4 изображений
fig, axes = plt.subplots(1, 4, figsize=(12, 3))
for i in range(4):
axes[i].imshow(X_train[i], cmap='gray')
axes[i].set_title(f'Метка: {y_train[i]}')
axes[i].axis('off')
plt.tight_layout()
plt.show()

Были выведены цифры 7, 8, 2, 2
5) Провели предобработку данных: привели обучающие и тестовые данные к формату, пригодному для обучения нейронной сети. Входные данные должны принимать значения от 0 до 1, метки цифр должны быть закодированы по принципу «one-hot encoding». Вывели размерности предобработанных обучающих и тестовых массивов данных.
# развернем каждое изображение 28*28 в вектор 784
num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape(X_train.shape[0], num_pixels) / 255
X_test = X_test.reshape(X_test.shape[0], num_pixels) / 255
print('Shape of transformed X train:', X_train.shape)
Shape of transformed X train: (60000, 784)
# переведем метки в one-hot
from keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print('Shape of transformed y train:', y_train.shape)
num_classes = y_train.shape[1]
Shape of transformed y train: (60000, 10)
6) Реализовали модель однослойной нейронной сети и обучили ее на обучающих данных с выделением части обучающих данных в качестве валидационных. Вывели информацию об архитектуре нейронной сети. Вывели график функции ошибки на обучающих и валидационных данных по эпохам.
model_0 = Sequential()
model_0.add(Dense(units=num_classes, input_dim=num_pixels, activation='softmax'))
# Компиляция модели
model_0.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
# Вывод информации об архитектуре
print("Архитектура однослойной сети:")
model_0.summary()

# Обучение модели
history_0 = model_0.fit(X_train, y_train,
validation_split=0.1,
epochs=50)
# График функции ошибки по эпохам
plt.figure(figsize=(10, 6))
plt.plot(history_0.history['loss'], label='Обучающая выборка')
plt.plot(history_0.history['val_loss'], label='Валидационная выборка')
plt.title('Функция ошибки по эпохам (Однослойная сеть)')
plt.xlabel('Эпохи')
plt.ylabel('Ошибка')
plt.legend()
plt.grid(True)
plt.show()
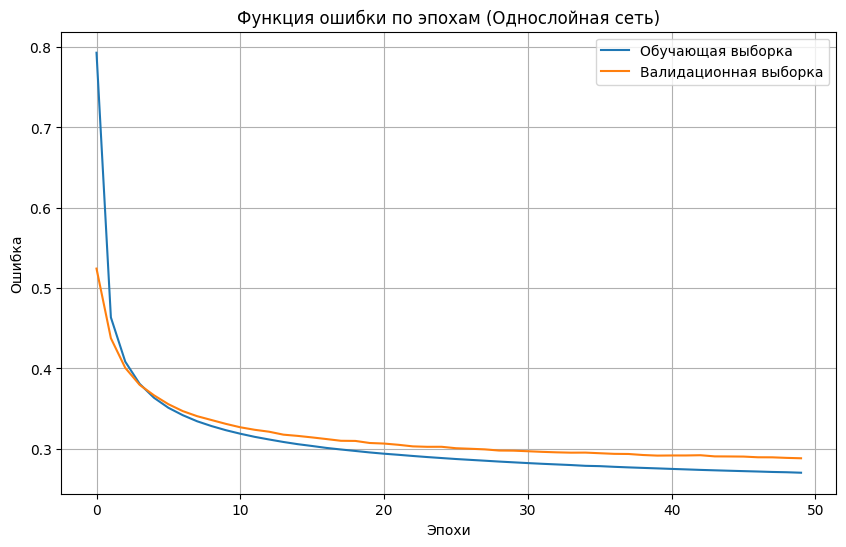
7) Применили обученную модель к тестовым данным. Вывели значение функции ошибки и значение метрики качества классификации на тестовых данных.
# Оценка на тестовых данных
scores_0 = model_0.evaluate(X_test, y_test, verbose=0)
print("Результаты однослойной сети:")
print(f"Ошибка на тестовых данных: {scores_0[0]}")
print(f"Точность на тестовых данных: {scores_0[1]}")
Результаты однослойной сети:
Ошибка на тестовых данных: 0.28625616431236267
Точность на тестовых данных: 0.92330002784729
8) Добавили в модель один скрытый и провели обучение и тестирование (повторить п. 6–7) при 100, 300, 500 нейронах в скрытом слое. По метрике качества классификации на тестовых данных выбрали наилучшее количество нейронов в скрытом слое. В качестве функции активации нейронов в скрытом слое использовали функцию sigmoid.
# Функция для создания и обучения модели
def create_and_train_model(hidden_units, model_name):
model = Sequential()
model.add(Dense(units=hidden_units, input_dim=num_pixels, activation='sigmoid'))
model.add(Dense(units=num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
history = model.fit(X_train, y_train,
validation_split=0.1,
epochs=50)
scores = model.evaluate(X_test, y_test, verbose=0)
return model, history, scores
# Эксперименты с разным количеством нейронов
hidden_units_list = [100, 300, 500]
models_1 = {}
histories_1 = {}
scores_1 = {}
# Обучение сетей с одним скрытым слоем
for units in hidden_units_list:
print(f"
Обучение модели с {units} нейронами...")
model, history, scores = create_and_train_model(units, f"model_{units}")
models_1[units] = model
histories_1[units] = history
scores_1[units] = scores
print(f"Точность: {scores[1]}")
Определим лучшую модель по итогвой точности
# Выбор наилучшей модели
best_units_1 = max(scores_1.items(), key=lambda x: x[1][1])[0]
print(f"
Наилучшее количество нейронов: {best_units_1}")
print(f"Точность: {scores_1[best_units_1][1]}")
Наилучшее количество нейронов: 100
Точность: 0.9422000050544739
Отобразим графики ошибок для каждой из архитектур нейросети
# Графики ошибок для всех моделей
plt.figure(figsize=(15, 5))
for i, units in enumerate(hidden_units_list, 1):
plt.subplot(1, 3, i)
plt.plot(histories_1[units].history['loss'], label='Обучающая')
plt.plot(histories_1[units].history['val_loss'], label='Валидационная')
plt.title(f'{units} нейронов')
plt.xlabel('Эпохи')
plt.ylabel('Ошибка')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
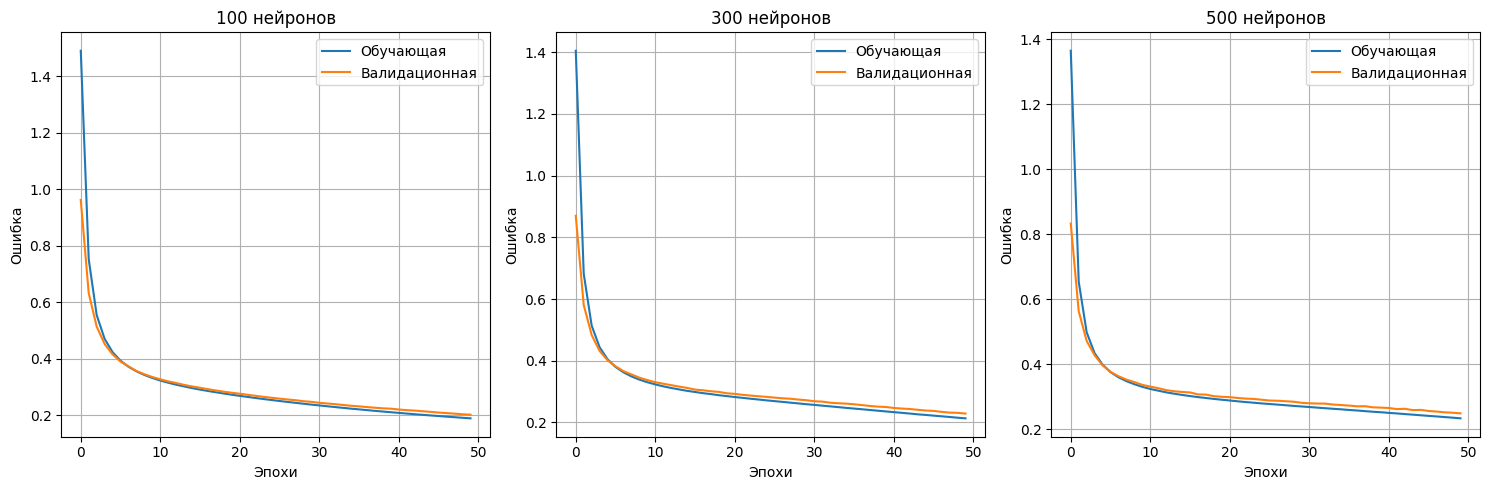
По результатам проведнного эксперимента наилучший показатель точности продемонстрировала нейронная сеть со 100 нейронами в скрытом слое - примерно 0.9422.
9) Добавили в архитектуру с лучшим показателем из п. 8, второй скрытый слой и провели обучение и тестирование при 50 и 100 нейронах во втором скрытом слое. В качестве функции активации нейронов в скрытом слое использовали функцию sigmoid.
# Добавление второго скрытого слоя
second_layer_units = [50, 100]
models_2 = {}
histories_2 = {}
scores_2 = {}
for units_2 in second_layer_units:
print(f"
Обучение модели со вторым слоем {units_2} нейронов")
model = Sequential()
model.add(Dense(units=best_units_1, input_dim=num_pixels, activation='sigmoid'))
model.add(Dense(units=units_2, activation='sigmoid'))
model.add(Dense(units=num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
history = model.fit(X_train, y_train,
validation_split=0.1,
epochs=50)
scores = model.evaluate(X_test, y_test)
models_2[units_2] = model
histories_2[units_2] = history
scores_2[units_2] = scores
print(f"Точность: {scores[1]}")
Результаты обучения моделей:
Обучение модели со вторым слоем 50 нейронов:
Точность: 0.9417999982833862
Обучение модели со вторым слоем 100 нейронов
Точность: 0.942300021648407
Выбор наилучшей двухслойной модели
best_units_2 = max(scores_2.items(), key=lambda x: x[1][1])[0]
print(f"
Наилучшее количество нейронов во втором слое: {best_units_2}")
print(f"Точность: {scores_2[best_units_2][1]}")
Наилучшее количество нейронов во втором слое: 100
Точность: 0.9423
10) Результаты исследования архитектуры нейронной сети занесли в таблицу:
# Сбор результатов
results = {
'0 слоев': {'нейроны_1': '-', 'нейроны_2': '-', 'точность': scores_0[1]},
'1 слой_100': {'нейроны_1': 100, 'нейроны_2': '-', 'точность': scores_1[100][1]},
'1 слой_300': {'нейроны_1': 300, 'нейроны_2': '-', 'точность': scores_1[300][1]},
'1 слой_500': {'нейроны_1': 500, 'нейроны_2': '-', 'точность': scores_1[500][1]},
'2 слоя_50': {'нейроны_1': best_units_1, 'нейроны_2': 50, 'точность': scores_2[50][1]},
'2 слоя_100': {'нейроны_1': best_units_1, 'нейроны_2': 100, 'точность': scores_2[100][1]}
}
# Создаем DataFrame из результатов
df_results = pd.DataFrame([
{'Кол-во скрытых слоев': 0, 'Нейроны_1_слоя': '-', 'Нейроны_2_слоя': '-', 'Точность': results['0 слоев']['точность']},
{'Кол-во скрытых слоев': 1, 'Нейроны_1_слоя': 100, 'Нейроны_2_слоя': '-', 'Точность': results['1 слой_100']['точность']},
{'Кол-во скрытых слоев': 1, 'Нейроны_1_слоя': 300, 'Нейроны_2_слоя': '-', 'Точность': results['1 слой_300']['точность']},
{'Кол-во скрытых слоев': 1, 'Нейроны_1_слоя': 500, 'Нейроны_2_слоя': '-', 'Точность': results['1 слой_500']['точность']},
{'Кол-во скрытых слоев': 2, 'Нейроны_1_слоя': best_units_1, 'Нейроны_2_слоя': 50, 'Точность': results['2 слоя_50']['точность']},
{'Кол-во скрытых слоев': 2, 'Нейроны_1_слоя': best_units_1, 'Нейроны_2_слоя': 100, 'Точность': results['2 слоя_100']['точность']}
])
print(" " * 20 + "ТАБЛИЦА РЕЗУЛЬТАТОВ")
print("=" * 70)
# print(df_results.to_string(index=False, formatters={
# 'Точность': '{:.4f}'.format
# }))
print(df_results.reset_index(drop=True))
ТАБЛИЦА РЕЗУЛЬТАТОВ
======================================================================
Кол-во скрытых слоев Нейроны_1_слоя Нейроны_2_слоя Точность
0 0 - - 0.9233
1 1 100 - 0.9422
2 1 300 - 0.9377
3 1 500 - 0.9312
4 2 100 50 0.9418
5 2 100 100 0.9423
# Выбор наилучшей модели
best_model_type = max(results.items(), key=lambda x: x[1]['точность'])[0]
best_accuracy = results[best_model_type]['точность']
print(f"
Наилучшая архитектура: {best_model_type}")
print(f"Точность: {best_accuracy}")
Наилучшая архитектура: 2 слоя_100
Точность: 0.9423
По результатам исследования сделали выводы и выбрали наилучшую архитектуру нейронной сети с точки зрения качества классификации.
Из таблицы следует, что лучшей архитектурой является НС с двумя скрытыми слоями по 100 и 50 нейронов, второе место занимает НС с одним скрытым слоем и 100 нейронами, на основе которой мы и строили НС с двумя скрытыми слоями. При увеличении количества нейронов в архитектуре НС с 1-м скрытым слоем в результате тестирования было вявлено, что метрики качества падают. Это связано с переобучение нашей НС с 1-м скрытым слоем (когда построенная модель хорошо объясняет примеры из обучающей выборки, но относительно плохо работает на примерах, не участвовавших в обучении) Такая тенденция вероятно возникает из-за простоты датасета MNIST, при усложнении архитектуры НС начинает переобучаться, а оценка качества на тестовых данных падает. Но также стоит отметить, что при усложнении структуры НС точнсть модели также и растет.
11) Сохранили наилучшую нейронную сеть на диск.
# Сохранение модели
best_model.save('best_mnist_model.keras')
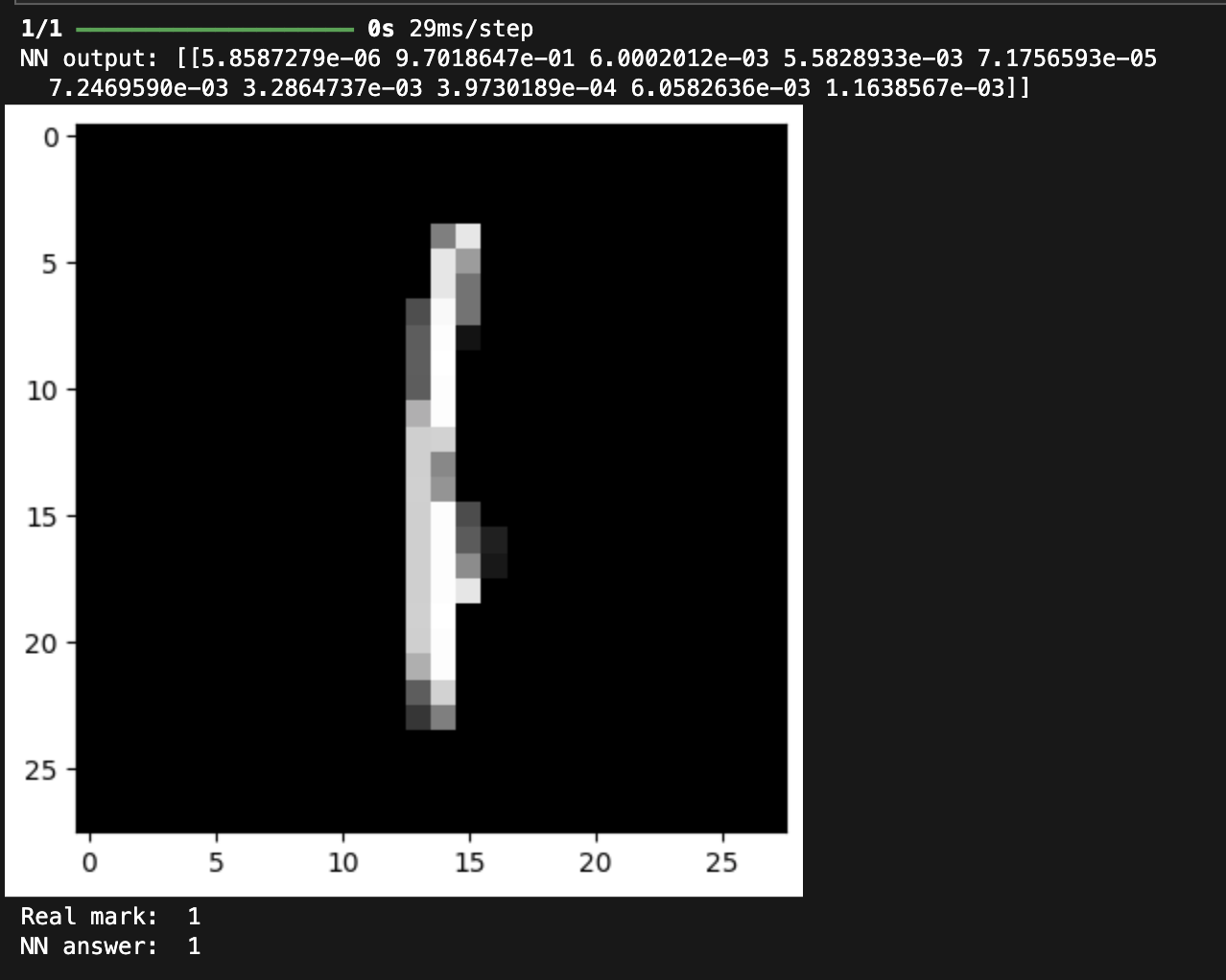
12) Для нейронной сети наилучшей архитектуры вывели два тестовых изображения, истинные метки и результат распознавания изображений.
# вывод тестового изображения и результата распознавания (1)
n = 123
result = best_model.predict(X_test[n:n+1])
print('NN output:', result)
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
plt.show()
print('Real mark: ', str(np.argmax(y_test[n])))
print('NN answer: ', str(np.argmax(result)))
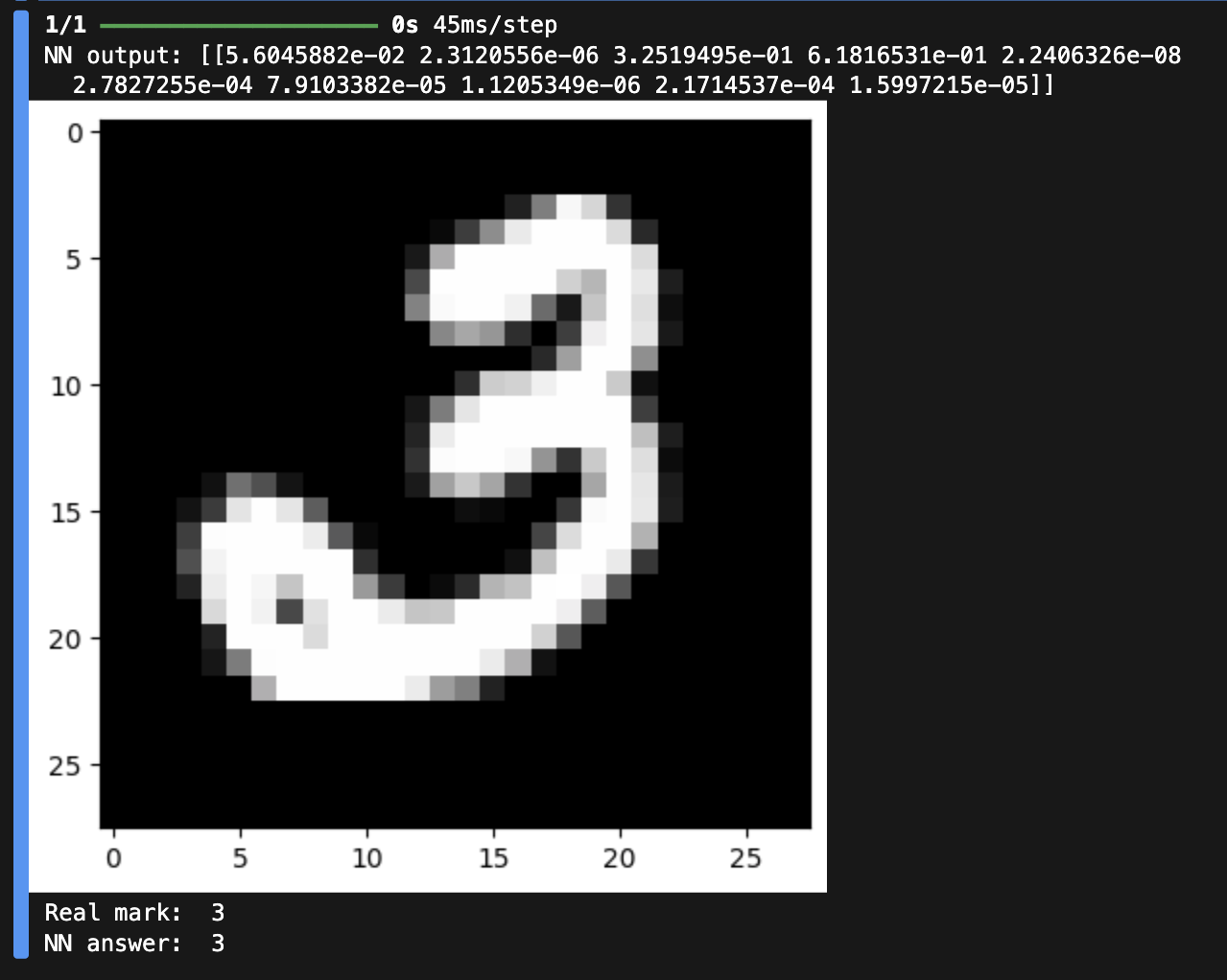
# вывод тестового изображения и результата распознавания (3)
n = 353
result = best_model.predict(X_test[n:n+1])
print('NN output:', result)
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
plt.show()
print('Real mark: ', str(np.argmax(y_test[n])))
print('NN answer: ', str(np.argmax(result)))
13) Создали собственные изображения рукописных цифр, подобное представленным в наборе MNIST. Цифру выбрали как остаток от деления на 10 числа своего дня рождения (12 марта → 2, 17 сентября → 7 ). Сохранили изображения. Загрузили, предобработали и подали на вход обученной нейронной сети собственные изображения. Вывели изображения и результаты распознавания.
# загрузка собственного изображения
file_data_2 = Image.open('2.png')
file_data_7 = Image.open('7.png')
file_data_2 = file_data_2.convert('L') # перевод в градации серого
file_data_7 = file_data_7.convert('L') # перевод в градации серого
test_img_2 = np.array(file_data_2)
test_img_7 = np.array(file_data_7)
# вывод собственного изображения (цифра 2)
plt.imshow(test_img_2, cmap=plt.get_cmap('gray'))
plt.show()
# предобработка
test_img_2 = test_img_2 / 255
test_img_2 = test_img_2.reshape(1, num_pixels)
# распознавание
result = best_model.predict(test_img_2)
print('I think it\'s ', np.argmax(result))

1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 31ms/step
# вывод собственного изображения (цифра 7)
plt.imshow(test_img_7, cmap=plt.get_cmap('gray'))
plt.show()
# предобработка
test_img_7 = test_img_7 / 255
test_img_7 = test_img_7.reshape(1, num_pixels)
# распознавание
result = best_model.predict(test_img_7)
print('I think it\'s ', np.argmax(result))

1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 48ms/step
I think it's 7
Как видим в результате эксперимента наша НС недостаточно точно определила изображение цифры 2. Возможно это связано с малом размером используемой выборки. Для улучшения качества решения задачи классификации можно либо увеличить размерность выборки для обучения НС, либо изменить структуру НС для более точной ее работы
14) Создать копию собственного изображения, отличающуюся от оригинала поворотом на 90 градусов в любую сторону. Сохранили изображения. Загрузили, предобработали и подали на вход обученной нейронной сети измененные изображения. Вывели изображения и результаты распознавания. Сделали выводы по результатам эксперимента.
# загрузка собственного изображения
file_data_2_90 = Image.open('2_90.png')
file_data_7_90 = Image.open('7_90.png')
file_data_2_90 = file_data_2_90.convert('L') # перевод в градации серого
file_data_7_90 = file_data_7_90.convert('L') # перевод в градации серого
test_img_2_90 = np.array(file_data_2_90)
test_img_7_90= np.array(file_data_7_90)
# вывод собственного изображения (цифра 2)
plt.imshow(test_img_2_90, cmap=plt.get_cmap('gray'))
plt.show()
# предобработка
test_img_2_90 = test_img_2_90 / 255
test_img_2_90 = test_img_2_90.reshape(1, num_pixels)
# распознавание
result = best_model.predict(test_img_2_90)
print('I think it\'s ', np.argmax(result))

1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 91ms/step
I think it's 7
# вывод собственного изображения (цифра 7)
plt.imshow(test_img_7_90, cmap=plt.get_cmap('gray'))
plt.show()
# предобработка
test_img_7_90 = test_img_7_90 / 255
test_img_7_90 = test_img_7_90.reshape(1, num_pixels)
# распознавание
result = best_model.predict(test_img_7_90)
print('I think it\'s ', np.argmax(result))

1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 48ms/step
I think it's 7
При повороте рисунков цифр НС не смогла распознать одну из цифр. Так получилось, во-первых, по той же причине, почему НС не распознала одну из цифр в пункте 13, во-вторых - наша НС не обучалась на перевернутых цифрах