27 KiB
Отчёт по лабораторной работе №3
Текотова В.А., Секирин А.А. — А-02-22
Задание 1
1) В среде Google Colab создали новый блокнот (notebook). Импортировали необходимые для работы библиотеки и модули.
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab3')
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
2) Загрузили набор данных MNIST, содержащий размеченные изображения рукописных цифр.
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
3) Разбили набор данных на обучающие и тестовые данные в соотношении 60 000:10 000 элементов. Параметр random_state выбрали равным (4k – 1)=3, где k=1 –номер бригады. Вывели размерности полученных обучающих и тестовых массивов данных.
# создание своего разбиения датасета
from sklearn.model_selection import train_test_split
# объединяем в один набор
X = np.concatenate((X_train, X_test))
y = np.concatenate((y_train, y_test))
# разбиваем по вариантам
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 10000,
train_size = 60000,
random_state = 3)
# вывод размерностей
print('Shape of X train:', X_train.shape)
print('Shape of y train:', y_train.shape)
print('Shape of X test:', X_test.shape)
print('Shape of y test:', y_test.shape)
Shape of X train: (60000, 28, 28)
Shape of y train: (60000,)
Shape of X test: (10000, 28, 28)
Shape of y test: (10000,)
4) Провели предобработку данных: привели обучающие и тестовые данные к формату, пригодному для обучения сверточной нейронной сети. Входные данные принимают значения от 0 до 1, метки цифр закодированы по принципу «one-hot encoding». Вывели размерности предобработанных обучающих и тестовых массивов данных.
# Зададим параметры данных и модели
num_classes = 10
input_shape = (28, 28, 1)
# Приведение входных данных к диапазону [0, 1]
X_train = X_train / 255
X_test = X_test / 255
# Расширяем размерность входных данных, чтобы каждое изображение имело
# размерность (высота, ширина, количество каналов)
X_train = np.expand_dims(X_train, -1)
X_test = np.expand_dims(X_test, -1)
print('Shape of transformed X train:', X_train.shape)
print('Shape of transformed X test:', X_test.shape)
# переведем метки в one-hot
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('Shape of transformed y train:', y_train.shape)
print('Shape of transformed y test:', y_test.shape)
Shape of transformed X train: (60000, 28, 28, 1)
Shape of transformed X test: (10000, 28, 28, 1)
Shape of transformed y train: (60000, 10)
Shape of transformed y test: (10000, 10)
5) Реализовали модель сверточной нейронной сети и обучили ее на обучающих данных с выделением части обучающих данных в качестве валидационных. Вывели информацию об архитектуре нейронной сети.
model = Sequential()
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Dropout(0.5))
model.add(layers.Flatten())
model.add(layers.Dense(num_classes, activation="softmax"))
model.summary()
**Model: "sequential"**
| Layer (type) | Output Shape | Param # |
|--------------------------------|---------------------|--------:|
| conv2d (Conv2D) | (None, 26, 26, 32) | 320 |
| max_pooling2d_8 (MaxPooling2D) | (None, 13, 13, 32) | 0 |
| conv2d_1 (Conv2D) | (None, 11, 11, 64) | 18,496 |
| max_pooling2d_9 (MaxPooling2D) | (None, 5, 5, 64) | 0 |
| dropout (Dropout) | (None, 5, 5, 64) | 0 |
| flatten (Flatten) | (None, 1600) | 0 |
| dense (Dense) | (None, 10) | 16,010 |
**Total params:** 34,826 (136.04 KB)
**Trainable params:** 34,826 (136.04 KB)
**Non-trainable params:** 0 (0.00 B)
```python
batch_size = 512
epochs = 15
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
Epoch 1/15
106/106 ━━━━━━━━━━━━━━━━━━━━ 6s 34ms/step - accuracy: 0.5991 - loss: 1.2739 - val_accuracy: 0.9427 - val_loss: 0.1933
Epoch 2/15
106/106 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.9363 - loss: 0.2175 - val_accuracy: 0.9645 - val_loss: 0.1128
...
Epoch 15/15
106/106 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.9851 - loss: 0.0460 - val_accuracy: 0.9895 - val_loss: 0.0350
<keras.src.callbacks.history.History at 0x78575e329e50>
6) Оценили качество обучения на тестовых данных. Вывели значение функции ошибки и значение метрики качества классификации на тестовых данных.
scores = model.evaluate(X_test, y_test)
print('Loss on test data:', scores[0])
print('Accuracy on test data:', scores[1])
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - accuracy: 0.9867 - loss: 0.0411
Loss on test data: 0.04398002102971077
Accuracy on test data: 0.9865000247955322
7) Подали на вход обученной модели два тестовых изображения. Вывели изображения, истинные метки и результаты распознавания.
for n in [3,26]:
result = model.predict(X_test[n:n+1])
print('NN output:', result)
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
plt.show()
print('Real mark: ', np.argmax(y_test[n]))
print('NN answer: ', np.argmax(result))
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 332ms/step
NN output: [[1.9338373e-09 8.8185527e-12 4.5429974e-08 2.5885814e-04 1.7587592e-08 9.9952632e-01 1.1317411e-08 1.5951617e-08 1.6658140e-08 2.1473359e-04]]
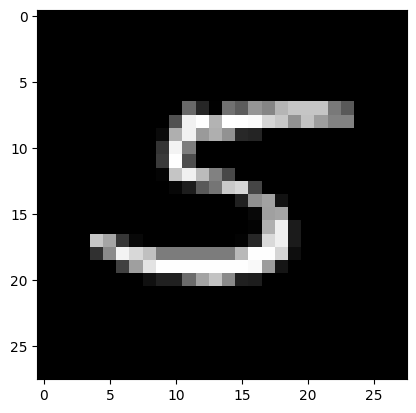
Real mark: 5
NN answer: 5
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 28ms/step
NN output: [[2.6663812e-04 5.6896381e-09 3.4766167e-04 2.4042051e-09 2.7227568e-04 6.0989500e-08 9.9911338e-01 2.0191379e-08 4.6584045e-08 1.9427532e-08]]
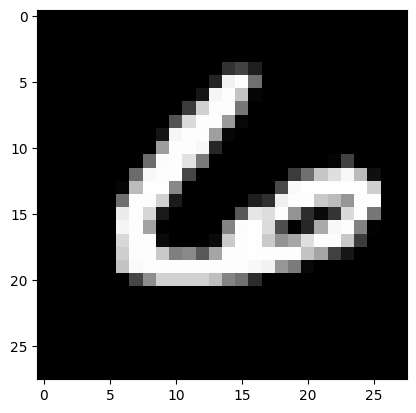
Real mark: 6
NN answer: 6
8) Вывели отчет о качестве классификации тестовой выборки и матрицу ошибок для тестовой выборки.
# истинные метки классов
true_labels = np.argmax(y_test, axis=1)
# предсказанные метки классов
predicted_labels = np.argmax(model.predict(X_test), axis=1)
# отчет о качестве классификации
print(classification_report(true_labels, predicted_labels))
# вычисление матрицы ошибок
conf_matrix = confusion_matrix(true_labels, predicted_labels)
# отрисовка матрицы ошибок в виде "тепловой карты"
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix)
display.plot()
plt.show()
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step
precision recall f1-score support
0 0.99 0.99 0.99 1009
1 0.99 1.00 1.00 1147
2 0.98 0.98 0.98 969
3 0.98 0.99 0.99 1025
4 0.99 0.98 0.99 939
5 0.98 0.98 0.98 881
6 0.99 0.99 0.99 1037
7 0.98 0.99 0.98 1001
8 0.99 0.98 0.98 950
9 0.99 0.98 0.98 1042
accuracy 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000

9) Загрузили, предобработали и подали на вход обученной нейронной сети собственное изображение, созданное при выполнении лабораторной работы №1. Вывели изображение и результат распознавания.
# загрузка собственного изображения
from PIL import Image
for name_image in ['цифра 3.png', 'цифра 6.png']:
file_data = Image.open(name_image)
file_data = file_data.convert('L') # перевод в градации серого
test_img = np.array(file_data)
# вывод собственного изображения
plt.imshow(test_img, cmap=plt.get_cmap('gray'))
plt.show()
# предобработка
test_img = test_img / 255
test_img = np.reshape(test_img, (1,28,28,1))
# распознавание
result = model.predict(test_img)
print('I think it\'s', np.argmax(result))

I think it's 2

I think it's 5
10) Загрузили с диска модель, сохраненную при выполнении лабораторной работы №1. Вывели информацию об архитектуре модели. Повторили для этой модели п. 6.
model_lr1 = keras.models.load_model("model_1h100_2h50.keras")
model_lr1.summary()
Model: "sequential_10"
| Layer (type) | Output Shape | Param # |
|------------------|-------------:|--------:|
| dense_1 (Dense) | (None, 100) | 78,500 |
| dense_2 (Dense) | (None, 10) | 1,010 |
Total params: 79,512 (310.60 KB)
Trainable params: 79,510 (310.59 KB)
Non-trainable params: 0 (0.00 B)
Optimizer params: 2 (12.00 B)
# развернем каждое изображение 28*28 в вектор 784
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 10000,
train_size = 60000,
random_state = 3)
num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape(X_train.shape[0], num_pixels) / 255
X_test = X_test.reshape(X_test.shape[0], num_pixels) / 255
print('Shape of transformed X train:', X_train.shape)
print('Shape of transformed X train:', X_test.shape)
# переведем метки в one-hot
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('Shape of transformed y train:', y_train.shape)
print('Shape of transformed y test:', y_test.shape)
Shape of transformed X train: (60000, 784)
Shape of transformed X train: (10000, 784)
Shape of transformed y train: (60000, 10)
Shape of transformed y test: (10000, 10)
# Оценка качества работы модели на тестовых данных
scores = model_lr1.evaluate(X_test, y_test)
print('Loss on test data:', scores[0])
print('Accuracy on test data:', scores[1])
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.9452 - loss: 0.1976
Loss on test data: 0.19490210711956024
Accuracy on test data: 0.944599986076355
11) Сравнили обученную модель сверточной сети и наилучшую модель полносвязной сети из лабораторной работы №1 по следующим показателям:
- количество настраиваемых параметров в сети
- количество эпох обучения
- качество классификации тестовой выборки.
Сделали выводы по результатам применения сверточной нейронной сети для распознавания изображений.
| Модель | Количество настраиваемых параметров | Количество эпох обучения | Качество классификации тестовой выборки |
|----------|-------------------------------------|---------------------------|-----------------------------------------|
| Сверточная | 34 826 | 15 | accuracy:0.986 ; loss:0.044 |
| Полносвязная | 84 062 | 50 | accuracy:0.944 ; loss:0.195 |
Вывод:Сравнительный анализ показывает явное преимущество свёрточной нейронной сети перед полносвязной в задачах распознавания изображений: при вдвое меньшем количестве параметров (34 826 против 79 512) и трёхкратном сокращении числа эпох обучения (15 против 50) CNN достигает более высокой точности (98,65% против 94,46%) и значительно меньшей ошибки (0,044 против 0,195).
Задание 2
1) Загрузили набор данных CIFAR-10, содержащий цветные изображения размеченные на 10 классов: самолет, автомобиль, птица, кошка, олень, собака, лягушка, лошадь, корабль, грузовик.
# загрузка датасета
from keras.datasets import cifar10
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
2) Разбили набор данных на обучающие и тестовые данные в соотношении 50 000:10 000 элементов. Параметр random_state выбрали равным (4k – 1)=23, где k=6 –номер бригады. Вывели размерности полученных обучающих и тестовых массивов данных.
# создание своего разбиения датасета
# объединяем в один набор
X = np.concatenate((X_train, X_test))
y = np.concatenate((y_train, y_test))
# разбиваем по вариантам
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 10000,
train_size = 50000,
random_state = 3)
# вывод размерностей
print('Shape of X train:', X_train.shape)
print('Shape of y train:', y_train.shape)
print('Shape of X test:', X_test.shape)
print('Shape of y test:', y_test.shape)
Shape of X train: (50000, 32, 32, 3)
Shape of y train: (50000, 1)
Shape of X test: (10000, 32, 32, 3)
Shape of y test: (10000, 1)
Вывели 25 изображений из обучающей выборки с подписью классов.
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(X_train[i])
plt.xlabel(class_names[y_train[i][0]])
plt.show()

3) Провели предобработку данных: привели обучающие и тестовые данные к формату, пригодному для обучения сверточной нейронной сети. Входные данные принимают значения от 0 до 1, метки цифр закодированы по принципу «one-hot encoding». Вывели размерности предобработанных обучающих и тестовых массивов данных.
# Зададим параметры данных и модели
num_classes = 10
input_shape = (32, 32, 3)
# Приведение входных данных к диапазону [0, 1]
X_train = X_train / 255
X_test = X_test / 255
print('Shape of transformed X train:', X_train.shape)
print('Shape of transformed X test:', X_test.shape)
# переведем метки в one-hot
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('Shape of transformed y train:', y_train.shape)
print('Shape of transformed y test:', y_test.shape)
Shape of transformed X train: (50000, 32, 32, 3)
Shape of transformed X test: (10000, 32, 32, 3)
Shape of transformed y train: (50000, 10)
Shape of transformed y test: (10000, 10)
4) Реализовали модель сверточной нейронной сети и обучили ее на обучающих данных с выделением части обучающих данных в качестве валидационных. Вывели информацию об архитектуре нейронной сети.
# создаем модель
model = Sequential()
# Блок 1
model.add(layers.Conv2D(32, (3, 3), padding="same",
activation="relu", input_shape=input_shape))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(32, (3, 3), padding="same", activation="relu"))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.25))
# Блок 2
model.add(layers.Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.25))
# Блок 3
model.add(layers.Conv2D(128, (3, 3), padding="same", activation="relu"))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(128, (3, 3), padding="same", activation="relu"))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.4))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(num_classes, activation="softmax"))
model.summary()
Model: "sequential_9"
| Layer (type) | Output Shape | Param # |
|--------------------------------------------|-------------------|---------:|
| conv2d_16 (Conv2D) | (None, 32, 32, 32) | 896 |
| batch_normalization_12 (BatchNormalization) | (None, 32, 32, 32) | 128 |
| conv2d_17 (Conv2D) | (None, 32, 32, 32) | 9,248 |
| batch_normalization_13 (BatchNormalization) | (None, 32, 32, 32) | 128 |
| max_pooling2d_10 (MaxPooling2D) | (None, 16, 16, 32) | 0 |
| dropout_10 (Dropout) | (None, 16, 16, 32) | 0 |
| conv2d_18 (Conv2D) | (None, 16, 16, 64) | 18,496 |
| batch_normalization_14 (BatchNormalization) | (None, 16, 16, 64) | 256 |
| conv2d_19 (Conv2D) | (None, 16, 16, 64) | 36,928 |
| batch_normalization_15 (BatchNormalization) | (None, 16, 16, 64) | 256 |
| max_pooling2d_11 (MaxPooling2D) | (None, 8, 8, 64) | 0 |
| dropout_11 (Dropout) | (None, 8, 8, 64) | 0 |
| conv2d_20 (Conv2D) | (None, 8, 8, 128) | 73,856 |
| batch_normalization_16 (BatchNormalization)| (None, 8, 8, 128) | 512 |
| conv2d_21 (Conv2D) | (None, 8, 8, 128) | 147,584 |
| batch_normalization_17 (BatchNormalization)| (None, 8, 8, 128) | 512 |
| max_pooling2d_12 (MaxPooling2D) | (None, 4, 4, 128) | 0 |
| dropout_12 (Dropout) | (None, 4, 4, 128) | 0 |
| flatten_4 (Flatten) | (None, 2048) | 0 |
| dense_6 (Dense) | (None, 128) | 262,272 |
| dropout_13 (Dropout) | (None, 128) | 0 |
| dense_7 (Dense) | (None, 10) | 1,290 |
Total params: 552,362 (2.11 MB)
Trainable params: 551,466 (2.10 MB)
Non-trainable params: 896 (3.50 KB)
# компилируем и обучаем модель
batch_size = 64
epochs = 50
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
Epoch 1/50
704/704 ━━━━━━━━━━━━━━━━━━━━ 25s 21ms/step - accuracy: 0.2474 - loss: 2.1347 - val_accuracy: 0.5014 - val_loss: 1.3804
Epoch 2/50
704/704 ━━━━━━━━━━━━━━━━━━━━ 7s 10ms/step - accuracy: 0.4517 - loss: 1.4843 - val_accuracy: 0.5648 - val_loss: 1.2039
...
Epoch 50/50
704/704 ━━━━━━━━━━━━━━━━━━━━ 9s 13ms/step - accuracy: 0.9183 - loss: 0.2363 - val_accuracy: 0.8370 - val_loss: 0.5748
<keras.src.callbacks.history.History at 0x78575551f7a0>
5) Оценили качество обучения на тестовых данных. Вывели значение функции ошибки и значение метрики качества классификации на тестовых данных.
# Оценка качества работы модели на тестовых данных
scores = model.evaluate(X_test, y_test)
print('Loss on test data:', scores[0])
print('Accuracy on test data:', scores[1])
313/313 ━━━━━━━━━━━━━━━━━━━━ 3s 5ms/step - accuracy: 0.8535 - loss: 0.5236
Loss on test data: 0.5263504981994629
Accuracy on test data: 0.8525000214576721
6) Подали на вход обученной модели два тестовых изображения. Вывели изображения, истинные метки и результаты распознавания.
# вывод двух тестовых изображений и результатов распознавания
for n in [3,15]:
result = model.predict(X_test[n:n+1])
print('NN output:', result)
plt.imshow(X_test[n].reshape(32,32,3), cmap=plt.get_cmap('gray'))
plt.show()
print('Real mark: ', np.argmax(y_test[n]))
print('NN answer: ', np.argmax(result))
1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 662ms/step
NN output: [[3.9128518e-13 3.7927967e-14 9.7535979e-10 9.2453198e-11 2.2669273e-13 4.2581650e-13 1.0000000e+00 2.1332333e-19 5.8570602e-13 1.1833489e-11]]
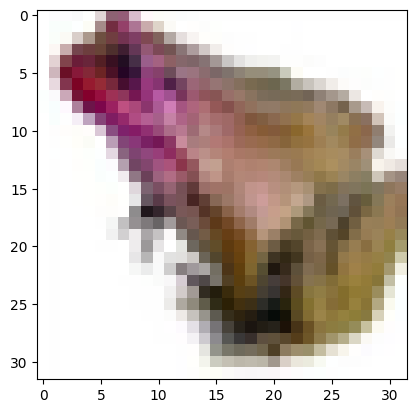
Real mark: 6
NN answer: 6
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 40ms/step
NN output: [[9.5250229e-08 5.8261224e-10 2.7865291e-05 2.9105169e-03 9.8321760e-01 1.3797697e-02 2.7701269e-06 4.3220436e-05 2.0006892e-08 1.8016836e-07]]

Real mark: 4
NN answer: 4
7) Вывели отчет о качестве классификации тестовой выборки и матрицу ошибок для тестовой выборки.
# истинные метки классов
true_labels = np.argmax(y_test, axis=1)
# предсказанные метки классов
predicted_labels = np.argmax(model.predict(X_test), axis=1)
# отчет о качестве классификации
print(classification_report(true_labels, predicted_labels, target_names=class_names))
# вычисление матрицы ошибок
conf_matrix = confusion_matrix(true_labels, predicted_labels)
# отрисовка матрицы ошибок в виде "тепловой карты"
fig, ax = plt.subplots(figsize=(6, 6))
disp = ConfusionMatrixDisplay(confusion_matrix=conf_matrix,display_labels=class_names)
disp.plot(ax=ax, xticks_rotation=45) # поворот подписей по X и приятная палитра
plt.tight_layout() # чтобы всё влезло
plt.show()
313/313 ━━━━━━━━━━━━━━━━━━━━ 2s 4ms/step
precision recall f1-score support
airplane 0.90 0.84 0.87 1007
automobile 0.92 0.93 0.93 1037
bird 0.86 0.78 0.82 1030
cat 0.68 0.72 0.70 990
deer 0.84 0.83 0.83 966
dog 0.77 0.79 0.78 1009
frog 0.78 0.94 0.86 972
horse 0.95 0.84 0.89 991
ship 0.94 0.93 0.94 990
truck 0.91 0.92 0.92 1008
accuracy 0.85 10000
macro avg 0.86 0.85 0.85 10000
weighted avg 0.86 0.85 0.85 10000
