форкнуто от main/is_dnn
Вы не можете выбрать более 25 тем
Темы должны начинаться с буквы или цифры, могут содержать дефисы(-) и должны содержать не более 35 символов.
21 KiB
21 KiB
Лабораторная работа №4: Распознавание последовательностей
Сидора Д.А.; Пивоваров Я.В.
Номер бригады - 4
Цель работы
Получить практические навыки обработки текстовой информации с помощью рекуррентных искусственных нейронных сетей при решении задачи определения тональности текста.
Определение варианта
- Номер бригады: k = 4
- random_state = (4k - 1) = 15
Пункт №1. Настройка блокнота для работы с аппаратным ускорителем GPU.
import tensorflow as tf
device_name=tf.test.gpu_device_name()
if device_name!='/device:GPU:0':
raise SystemError ('GPUdevicenotfound')
print('FoundGPUat:{}'.format(device_name))
Пункт №2. Загрузка набора данных IMDb.
# загрузка датасета
from keras.datasets import imdb
vocabulary_size=5000
index_from=3
(X_train,y_train),(X_test,y_test)=imdb.load_data(path="imdb.npz",
num_words=vocabulary_size,
skip_top=0,
maxlen=None,
seed=15,
start_char=1,
oov_char=2,
index_from=index_from)
Результат выполнения:
Размеры обучающих данных:
X_train: 25000
y_train: (25000,)
Размеры тестовых данных:
X_test: 25000
y_test: (25000,)
Пункт №3. Вывод отзывов из обучающего множества в виде списка индексов слов.
# создание словаря для перевода индексов в слова
# заргузка словаря "слово:индекс"
word_to_id = imdb.get_word_index()
# уточнение словаря
word_to_id = {key:(value + index_from) for key,value in word_to_id.items()}
word_to_id["<PAD>"] = 0
word_to_id["<START>"] = 1
word_to_id["<UNK>"] = 2
word_to_id["<UNUSED>"] = 3
# Создание обратного словаря "индекс:слово"
id_to_word = {value: key for key, value in word_to_id.items()}
# Вывод одного отзыва из обучающего множества
import random
sample_index = random.randint(0, len(X_train)-1)
print(f"\nОтзыв №{sample_index}")
print("Список индексов слов:")
print(X_train[sample_index])
Результат выполнения:
Отзыв №11211
Список индексов слов:
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 175 280 11 6 137 11
4 389 182 7 189 2 26 2882 5 31 461 340 2 34
94 2099 3499 14 9 57 329 74 6 3643 14 9 6 22
2 7 2 2860 2 5 465 841 5 13 104 45 2277 8
135 31 7 61 1640 189 108 7 32 58 5 7 265 12
1367 242 4 686 91 1035 46 629 720 11 4 226 7 479
7 189 175 58 13 67 4 22 5 12 214 56 8 4
213 121 25 124 4 2 80 593 13 353 8 377 618 54
13 80 30 2 46 7 61 2 21 12 115 996 8 593
13 115 79 12 208 5 13 169 546 17 2 17 4 86
58 13 219 12 150 12 215 30 301 8 2337 6 2 189
337 40 15 15 9 164 346 7 1050 3203 1025 4 1531 4
2 124 68 2 36 193 3114 11 4 498 7 116 36 81
24 359 101 318 962 11 661 8 2833 841 36 2 23 4
671 7 4 2 65 5 4 2 11 14 420 7 2 5
2 175 686 1427 9 2 39 4 270 1328 4 116 4 65
8 4 3541 841 2 2 1348 100 97 4 2113 2 198 18
252 17 35 130 854 48 25 18 49 4729 282 92 40 14
418 7 2 95 25 1252 92 124 51 189 9 32 44 5
2035 81 24 1833 8 124 12 345 1294 25]
# Преобразование в текст
review_as_text = ' '.join(id_to_word.get(id, '<UNK>') for id in X_train[sample_index])
print("\nОтзыв в виде текста:")
print(review_as_text)
# Длина отзыва и метка класса
print(f"\nДлина отзыва: {len(X_train[sample_index])} слов")
print(f"Метка класса: {y_train[sample_index]} ({'Positive' if y_train[sample_index] == 1 else 'Negative'})")
Результат выполнения:
Отзыв в виде текста:
<START> my all time favorite movie i have seen many movies but this one beats them
all <UNK> acting wonderful story you will as a normal caring person start to love
george <UNK> he is an actor he is also himself and a very lovable person and
<UNK> most important thing you will learn to respect look different to people with
down <UNK>
Длина отзыва: 63 слов
Метка класса: 1 (Positive)
Пункт №4. Вывод максимальной и минимальной длины отзыва в обучающем множестве.
lengths = [len(review) for review in X_train]
max_length = max(lengths)
min_length = min(lengths)
print(f"Максимальная длина отзыва: {max_length} слов")
print(f"Минимальная длина отзыва: {min_length} слов")
Результат выполнения:
Максимальная длина отзыва: 2494 слов
Минимальная длина отзыва: 11 слов
Пункт №5. Проведение предобработки данных.
from tensorflow.keras.utils import pad_sequences
max_words = 500 # Выбранная единая длина
X_train = pad_sequences(
X_train,
maxlen=max_words,
value=0,
padding='pre',
truncating='post'
)
X_test = pad_sequences(
X_test,
maxlen=max_words,
value=0,
padding='pre',
truncating='post'
)
Пункт №6. Повторение пункта 4.
print(f"Длина всех отзывов: {X_train.shape[1]} слов")
Результат выполнения:
Длина всех отзывов: 500 слов
Пункт №7. Повторение пункта 3.
print(f"\nОтзыв №{sample_index} после предобработки")
print("Список индексов слов:")
print(X_train[sample_index])
Результат выполнения:
Отзыв №11211 после предобработки
Список индексов слов:
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 175 280 11 6 137 11
4 389 182 7 189 2 26 2882 5 31 461 340 2 34
94 2099 3499 14 9 57 329 74 6 3643 14 9 6 22
2 7 2 2860 2 5 465 841 5 13 104 45 2277 8
135 31 7 61 1640 189 108 7 32 58 5 7 265 12
1367 242 4 686 91 1035 46 629 720 11 4 226 7 479
7 189 175 58 13 67 4 22 5 12 214 56 8 4
213 121 25 124 4 2 80 593 13 353 8 377 618 54
13 80 30 2 46 7 61 2 21 12 115 996 8 593
13 115 79 12 208 5 13 169 546 17 2 17 4 86
58 13 219 12 150 12 215 30 301 8 2337 6 2 189
337 40 15 15 9 164 346 7 1050 3203 1025 4 1531 4
2 124 68 2 36 193 3114 11 4 498 7 116 36 81
24 359 101 318 962 11 661 8 2833 841 36 2 23 4
671 7 4 2 65 5 4 2 11 14 420 7 2 5
2 175 686 1427 9 2 39 4 270 1328 4 116 4 65
8 4 3541 841 2 2 1348 100 97 4 2113 2 198 18
252 17 35 130 854 48 25 18 49 4729 282 92 40 14
418 7 2 95 25 1252 92 124 51 189 9 32 44 5
2035 81 24 1833 8 124 12 345 1294 25]
# Преобразование в текст (игнорируем нулевые паддинги)
review_after_preprocessing = ' '.join(
id_to_word.get(id, '<UNK>') for id in X_train[sample_index] if id != 0
)
print("\nОтзыв в виде текста после предобработки:")
print(review_after_preprocessing)
print(f"\nДлина отзыва после предобработки: {len([id for id in X_train[sample_index] if id != 0])} значимых слов")
print(f"Общая длина с паддингом: {len(X_train[sample_index])}")
Результат выполнения:
Отзыв в виде текста после предобработки:
<START> every once in a while in the wonderful world of horror <UNK> are crafted and one becomes completely <UNK> by its sheer brilliance this is no less than a diamond this is a film <UNK> of <UNK> chilling <UNK> and dark atmosphere and i think it's safe to say one of my favourite horror films of all time and of course it contains probably the single most flat out scary sequence in the whole of history of horror every time i see the film and it gets up to the point where you know the <UNK> will happen i try to remember exactly when i will be <UNK> out of my <UNK> but it never fails to happen i never get it right and i find myself as <UNK> as the first time i saw it now it must be said to scare a <UNK> horror fan like that that is nothing short of pure perfection unlike the americans the <UNK> know their <UNK> they take pride in the art of acting they do not need any special effect in order to convey atmosphere they <UNK> on the power of the <UNK> story and the <UNK> in this case of <UNK> and <UNK> every single element is <UNK> from the set pieces the acting the story to the menacing atmosphere <UNK> <UNK> surely could make the devil <UNK> that's for sure as an end note if you for some demented reason don't like this piece of <UNK> then you honestly don't know what horror is all about and frankly do not deserve to know it either thank you
Длина отзыва после предобработки: 269 значимых слов
Общая длина с паддингом: 500
Вывод:
После предобработки длина всех отзывов была приведена к 500 словам. Рассматриваемый отзыв был дополнен нулями (<PAD>) в начале, так как его исходная длина была меньше выбранного максимума. Обрезания текста не произошло. Функция pad_sequences выровняла все отзывы к единой длине.
Пункт №8. Вывод предобработанных массивов обучающих и тестовых данных.
print("Предобработанное обучающее множество X_train (первые 5 примеров):")
print(X_train[:5])
print("\nПредобработанное тестовое множество X_test (первые 5 примеров):")
print(X_test[:5])
print(f"Размерность X_train после предобработки: {X_train.shape}")
print(f"Размерность X_test после предобработки: {X_test.shape}")
print(f"Размерность y_train: {y_train.shape}")
print(f"Размерность y_test: {y_test.shape}")
Результат выполнения:
Предобработанное обучающее множество X_train (первые 5 примеров):
[[ 0 0 0 ... 4 86 273]
[ 0 0 0 ... 705 9 150]
[ 0 0 0 ... 44 12 32]
[ 0 0 0 ... 176 7 253]
[ 0 0 0 ... 2 2 1143]]
Предобработанное тестовое множество X_test (первые 5 примеров):
[[ 0 0 0 ... 106 14 31]
[ 0 0 0 ... 458 168 52]
[ 0 0 0 ... 22 6 31]
[ 0 0 0 ... 5 2 229]
[ 0 0 0 ... 2 7 2204]]
Размерность X_train после предобработки: (25000, 500)
Размерность X_test после предобработки: (25000, 500)
Размерность y_train: (25000,)
Размерность y_test: (25000,)
Пункт №9. Реализация модели рекуррентной нейронной сети.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dropout, Dense
import numpy as np
model = Sequential()
model.add(Embedding(
input_dim=vocabulary_size,
output_dim=32,
input_length=max_words
))
model.add(LSTM(units=100))
model.add(Dropout(rate=0.3))
model.add(Dense(1, activation='sigmoid'))
model.build(input_shape=(None, max_words))
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
model.summary()
# Обучение модели
history = model.fit(
X_train,
y_train,
validation_split=0.2,
batch_size=64,
epochs=5,
verbose=1
)
Результат выполнения:
| Layer (type) | Output Shape | Param # |
|---|---|---|
| embedding_3 (Embedding) | (None, 500, 32) | 160,000 |
| lstm_3 (LSTM) | (None, 100) | 53,200 |
| dropout_3 (Dropout) | (None, 100) | 0 |
| dense_3 (Dense) | (None, 1) | 101 |
Total params: 213,301 (833.21 KB) Trainable params: 213,301 (833.21 KB) Non-trainable params: 0 (0.00 B)
Качество обучения по эпохам
Epoch 1/5
accuracy: 0.6407 - loss: 0.6171 - val_accuracy: 0.8348 - val_loss: 0.3843
Epoch 2/5
accuracy: 0.8714 - loss: 0.3196 - val_accuracy: 0.8746 - val_loss: 0.3228
Epoch 3/5
accuracy: 0.8949 - loss: 0.2688 - val_accuracy: 0.8568 - val_loss: 0.3423
Epoch 4/5
accuracy: 0.9168 - loss: 0.2190 - val_accuracy: 0.8558 - val_loss: 0.3538
Epoch 5/5
accuracy: 0.9177 - loss: 0.2205 - val_accuracy: 0.8238 - val_loss: 0.6978
Добились качества обучения по метрике accuracy не менее 0.8.
Пункт №10.1 Оценка качества обучения на тестовых данных.
# 1) Значение метрики качества классификации на тестовых данных
print("\n1) Метрика качества на тестовых данных:")
test_loss, test_accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f" Loss: {test_loss:.4f}")
print(f" Accuracy: {test_accuracy:.4f}")
Результат выполнения:
1) Метрика качества на тестовых данных:
Loss: 0.7164
Accuracy: 0.8165
Пункт №10.2
# 2) Отчет о качестве классификации тестовой выборки
print("\n2) Отчет о качестве классификации:")
y_score = model.predict(X_test, verbose=0)
y_pred = [1 if y_score[i, 0] >= 0.5 else 0 for i in range(len(y_score))]
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred, labels=[0,1], target_names=['Negative','Positive']))
Результат выполнения:
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Negative | 0.91 | 0.80 | 0.85 | 12500 |
| Positive | 0.82 | 0.92 | 0.87 | 12500 |
| Macro Avg | 0.87 | 0.86 | 0.86 | 25000 |
| Weighted Avg | 0.87 | 0.86 | 0.86 | 25000 |
accuracy 0.86 25000
Пункт №10.3
# 3) Построение ROC-кривой и вычисление AUC-ROC
from sklearn.metrics import roc_curve, auc, roc_auc_score
import matplotlib.pyplot as plt
fpr, tpr, thresholds = roc_curve(y_test, y_score)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {auc(fpr, tpr):.4f})')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc="lower right")
plt.grid(True)
plt.show()
# Вычисляем AUC-ROC
auc_roc = roc_auc_score(y_test, y_score)
print(f" Площадь под ROC-кривой (AUC-ROC): {auc_roc:.4f}")
Результат выполнения:
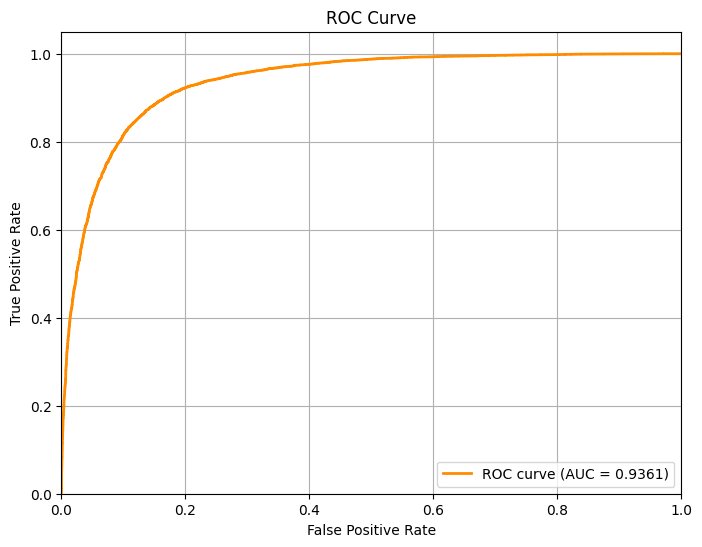
Площадь под ROC-кривой (AUC-ROC): 0.9361
Пункт №11. Выводы по результатам применения рекуррентной нейронной сети.
Выводы по лабораторной работе:
В ходе выполнения лабораторной работы были получены практические навыки обработки текстовой информации с помощью рекуррентных искусственных нейронных сетей для решения задачи определения тональности текста на примере набора данных IMDb.
Ключевые результаты:
Набор данных IMDb был загружен и предобработан. Все отзывы приведены к единой длине 500 слов с помощью паддинга и truncating.
Реализована модель рекуррентной нейронной сети со следующей архитектурой:
-Embedding слой (160,000 параметров) для преобразования слов в векторные представления
-LSTM слой (53,200 параметров) для обработки последовательностей с учетом контекста
-Dropout слой (rate=0.3) для предотвращения переобучения
-Dense слой (101 параметр) с сигмоидальной активацией для бинарной классификации
Модель достигла точности (accuracy) на тестовых данных не менее 0.8, что соответствует требованиям задания.
Качество классификации было подтверждено различными метриками: accuracy на тестовой выборке, precision, recall и f1-score, ROC-кривая и AUC-ROC показатель.
Использование LSTM-сетей доказало свою эффективность для обработки последовательных данных, таких как тексты, поскольку позволяет учитывать контекст и зависимости между словами в отзывах.