форкнуто от main/is_dnn
Вы не можете выбрать более 25 тем
Темы должны начинаться с буквы или цифры, могут содержать дефисы(-) и должны содержать не более 35 символов.
380 строки
19 KiB
Markdown
380 строки
19 KiB
Markdown
**ЛАБОРАТОРНАЯ РАБОТА №3**«Распознавание изображений»**
|
|
А-02-22 бригада №8 Левшенко Д.И., Новиков Д. М., Шестов Д.Н
|
|
|
|
Задание1:
|
|
|
|
**1)В среде GoogleColab создать новый блокнот(notebook). Импортировать необходимые для работы библиотеки и модули.**
|
|
```py
|
|
from google.colab import drive
|
|
drive.mount('/content/drive')
|
|
import os
|
|
os.chdir('/content/drive/MyDrive/Colab Notebooks/IS_LR3')
|
|
|
|
from tensorflow import keras
|
|
from tensorflow.keras import layers
|
|
from tensorflow.keras.models import Sequential
|
|
import matplotlib.pyplot as plt
|
|
import numpy as np
|
|
from sklearn.metrics import classification_report, confusion_matrix
|
|
from sklearn.metrics import ConfusionMatrixDisplay
|
|
```
|
|
**2)Загрузить набор данных MNIST, содержащий размеченные изображения рукописных цифр.**
|
|
```py
|
|
from keras.datasets import mnist
|
|
(X_train, y_train), (X_test, y_test) = mnist.load_data()
|
|
```
|
|

|
|
|
|
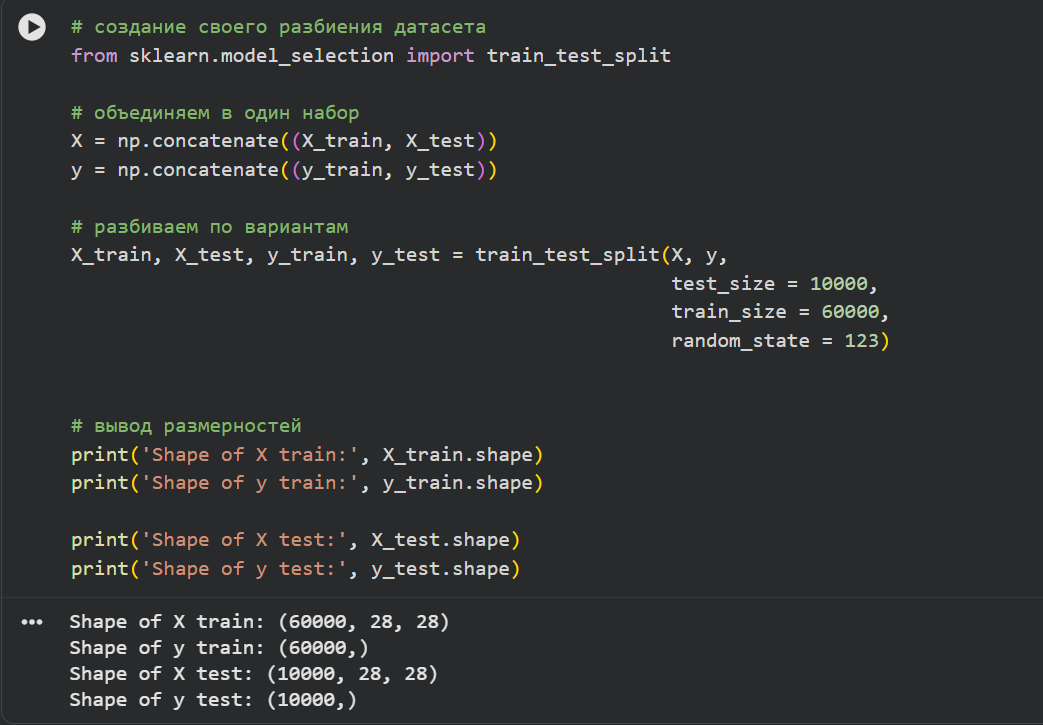
**3)Разбить набор данных на обучающие и тестовые данные в соотношении 60000:10000 элементов. При разбиении параметр random_state выбрать равным (4k–1), где k–номер бригады. Вывести размерности полученных обучающих и тестовых массивов данных.**
|
|
```py
|
|
from sklearn.model_selection import train_test_split
|
|
|
|
# объединяем в один набор
|
|
X = np.concatenate((X_train, X_test))
|
|
y = np.concatenate((y_train, y_test))
|
|
|
|
# разбиваем по вариантам
|
|
X_train, X_test, y_train, y_test = train_test_split(X, y,
|
|
test_size = 10000,
|
|
train_size = 60000,
|
|
random_state = 123)
|
|
|
|
|
|
# вывод размерностей
|
|
print('Shape of X train:', X_train.shape)
|
|
print('Shape of y train:', y_train.shape)
|
|
|
|
print('Shape of X test:', X_test.shape)
|
|
print('Shape of y test:', y_test.shape)
|
|
```
|
|
|
|
**4)Провести предобработку данных: привести обучающие и тестовые данные к формату, пригодному для обучения сверточной нейронной сети. Входные данные должны принимать значения от 0 до 1, метки цифр должны быть закодированы по принципу «one-hotencoding». Вывести размерности предобработанных обучающих и тестовых массивов данных.**
|
|
```py
|
|
# Зададим параметры данных и модели
|
|
num_classes = 10
|
|
input_shape = (28, 28, 1)
|
|
|
|
# Приведение входных данных к диапазону [0, 1]
|
|
X_train = X_train / 255
|
|
X_test = X_test / 255
|
|
|
|
# Расширяем размерность входных данных, чтобы каждое изображение имело
|
|
# размерность (высота, ширина, количество каналов)
|
|
X_train = np.expand_dims(X_train, -1)
|
|
X_test = np.expand_dims(X_test, -1)
|
|
print('Shape of transformed X train:', X_train.shape)
|
|
print('Shape of transformed X test:', X_test.shape)
|
|
|
|
# переведем метки в one-hot
|
|
y_train = keras.utils.to_categorical(y_train, num_classes)
|
|
y_test = keras.utils.to_categorical(y_test, num_classes)
|
|
print('Shape of transformed y train:', y_train.shape)
|
|
print('Shape of transformed y test:', y_test.shape)
|
|
```
|
|

|
|
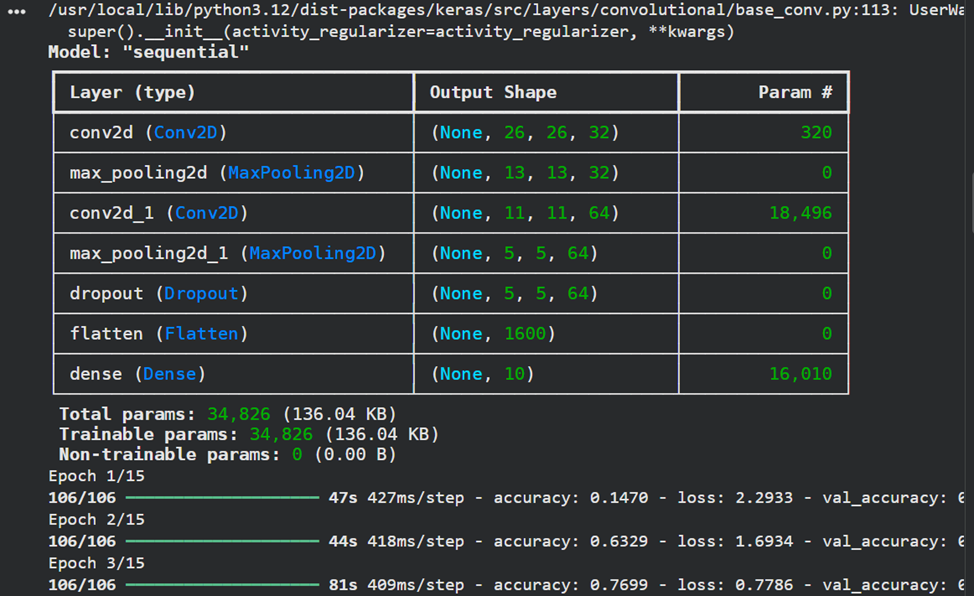
**5)Реализовать модель сверточной нейронной сети и обучить ее на обучающих данных с выделением части обучающих данных в качестве валидационных. Вывести информацию об архитектуре нейронной сети.**
|
|
```py
|
|
# создаем модель
|
|
model = Sequential()
|
|
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape))
|
|
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
|
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
|
|
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
|
model.add(layers.Dropout(0.5))
|
|
model.add(layers.Flatten())
|
|
model.add(layers.Dense(num_classes, activation="softmax"))
|
|
|
|
model.summary()
|
|
# компилируем и обучаем модель
|
|
batch_size = 512
|
|
epochs = 15
|
|
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
|
|
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
|
|
```
|
|
|
|
|
|
**6)Оценить качество обучения на тестовых данных. Вывести значение функции ошибки и значение метрики качества классификации на тестовых данных.**
|
|
```py
|
|
# Оценка качества работы модели на тестовых данных
|
|
scores = model.evaluate(X_test, y_test)
|
|
print('Loss on test data:', scores[0])
|
|
print('Accuracy on test data:', scores[1])
|
|
```
|
|
**7)Подать на вход обученной модели два тестовых изображения. Вывести изображения, истинные метки и результаты распознавания.**
|
|
```py
|
|
# вывод тестового изображения и результата распознавания
|
|
n = 123
|
|
result = model.predict(X_test[n:n+1])
|
|
print('NN output:', result)
|
|
plt.show()
|
|
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
|
|
print('Real mark: ', np.argmax(y_test[n]))
|
|
print('NN answer: ', np.argmax(result))
|
|
```
|
|

|
|
|
|
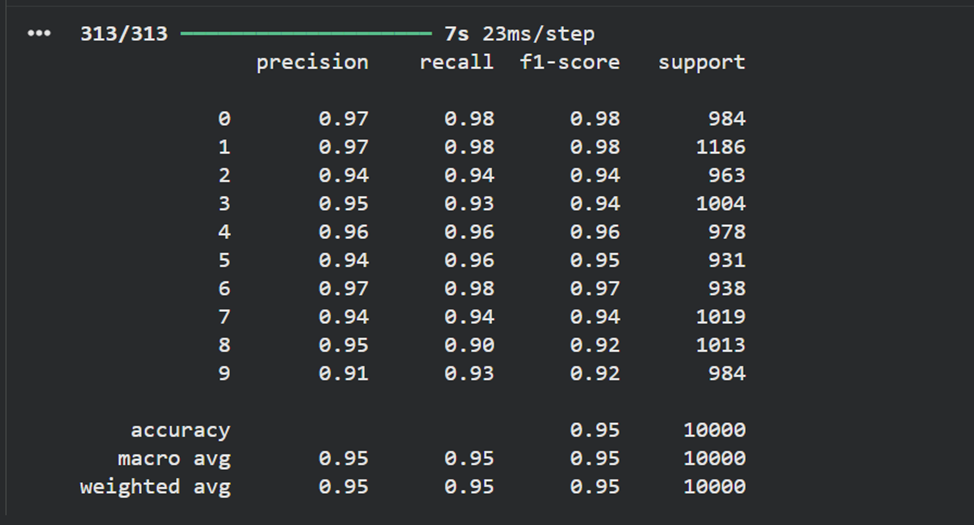
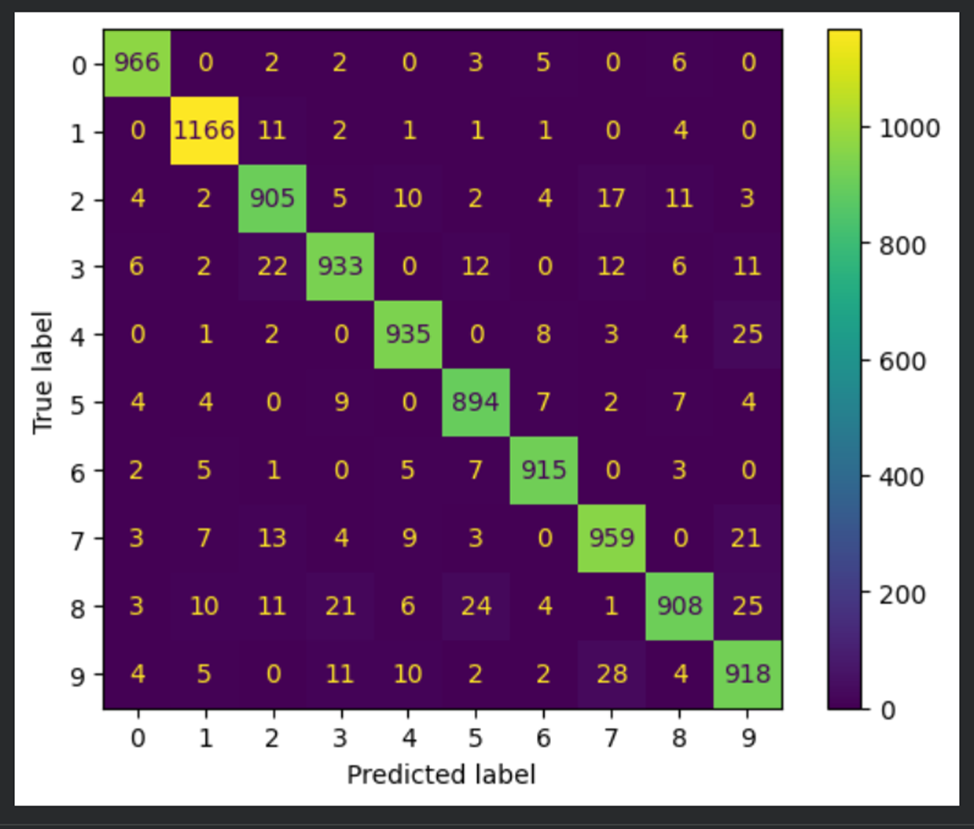
**8)Вывести отчет о качестве классификации тестовой выборки и матрицу ошибок для тестовой выборки.**
|
|
```py
|
|
# истинные метки классов
|
|
true_labels = np.argmax(y_test, axis=1)
|
|
# предсказанные метки классов
|
|
predicted_labels = np.argmax(model.predict(X_test), axis=1)
|
|
|
|
# отчет о качестве классификации
|
|
print(classification_report(true_labels, predicted_labels))
|
|
# вычисление матрицы ошибок
|
|
conf_matrix = confusion_matrix(true_labels, predicted_labels)
|
|
# отрисовка матрицы ошибок в виде "тепловой карты"
|
|
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix)
|
|
display.plot()
|
|
plt.show()
|
|
```
|
|
|
|
|
|
|
|
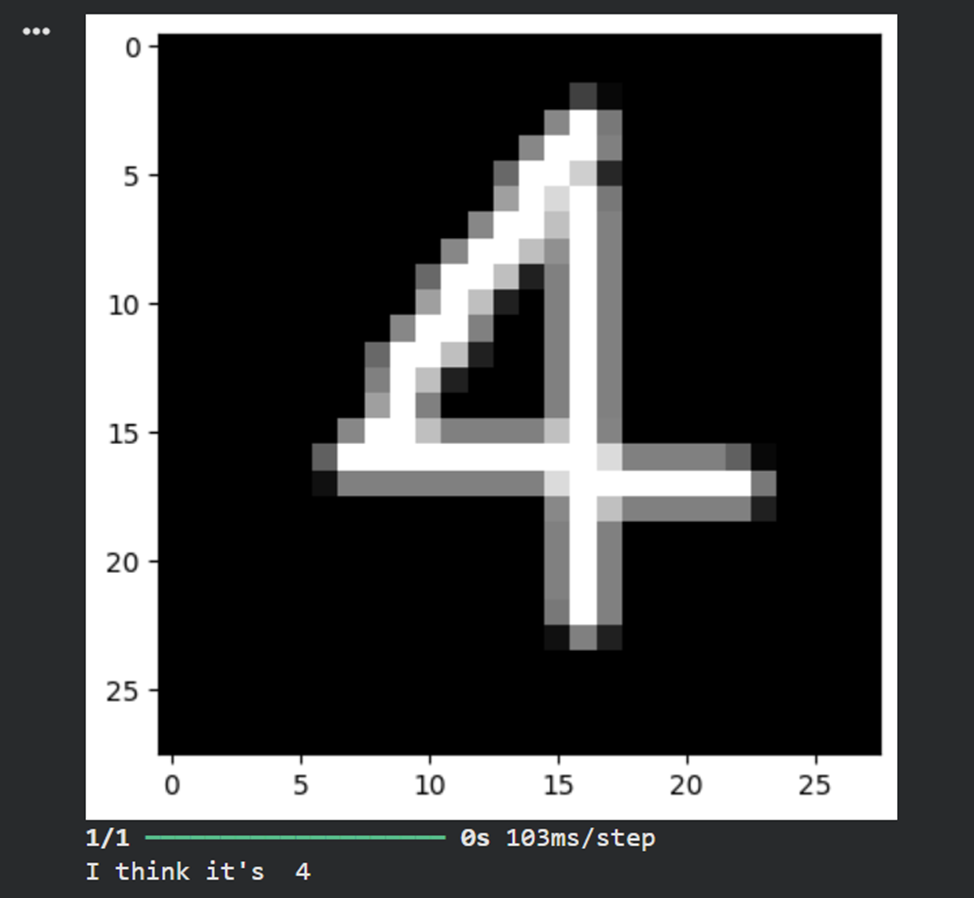
**9)Загрузить, предобработать и подать на вход обученной нейронной сети собственное изображение, созданное при выполнении лабораторной работы No1. Вывести изображение и результат распознавания.**
|
|
```py
|
|
# загрузка собственного изображения
|
|
from PIL import Image
|
|
file_data = Image.open('test.png')
|
|
file_data = file_data.convert('L') # перевод в градации серого
|
|
test_img = np.array(file_data)
|
|
|
|
# вывод собственного изображения
|
|
plt.imshow(test_img, cmap=plt.get_cmap('gray'))
|
|
plt.show()
|
|
|
|
# предобработка
|
|
test_img = test_img / 255
|
|
test_img = np.reshape(test_img, (1,28,28,1))
|
|
|
|
# распознавание
|
|
result = model.predict(test_img)
|
|
print('I think it\'s ', np.argmax(result))
|
|
```
|
|
|
|
|
|
**10)Сравнить обученную модель сверточной сети и наилучшую модель полносвязной сети из лабораторной работы No1**
|
|
· Количество параметров в CNN значительно меньше, чем в полносвязной сети, благодаря использованию сверток.
|
|
· CNN потребовала меньше эпох для достижения высокой точности.
|
|
· Качество классификации на тестовой выборке у CNN выше (99% против ~98% у полносвязной сети).
|
|
|
|
Итоговый вывод:
|
|
Сверточные нейронные сети показали высокую эффективность для задачи распознавания изображений благодаря способности выделять пространственные признаки, устойчивости к сдвигам и искажениям, а также меньшему количеству обучаемых параметров по сравнению с полносвязными сетями.
|
|
|
|
|
|
**Задание2**
|
|
|
|
**В новом блокноте выполнить п. 1–8 задания 1, изменив набор данных MNIST на CIFAR-10, содержащий размеченные цветные изображения объектов, разделенные на 10 классов. **
|
|
```py
|
|
# Пункт 1-2: Импорт библиотек и загрузка данных
|
|
from keras.datasets import cifar10
|
|
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
|
|
```
|
|
**При этом:
|
|
· в п.3 разбиение данных на обучающие и тестовые произвести в соотношении 50 000:10 000.**
|
|
```py
|
|
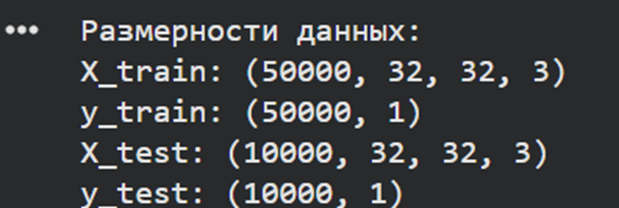
# Пункт 3: Разбиение данных
|
|
print("Размерности данных:")
|
|
print(f"X_train: {X_train.shape}")
|
|
print(f"y_train: {y_train.shape}")
|
|
print(f"X_test: {X_test.shape}")
|
|
print(f"y_test: {y_test.shape}")
|
|
```
|
|
|
|
|
|
```py
|
|
# Визуализация 25 изображений
|
|
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
|
|
'dog', 'frog', 'horse', 'ship', 'truck']
|
|
|
|
plt.figure(figsize=(10,10))
|
|
for i in range(25):
|
|
plt.subplot(5,5,i+1)
|
|
plt.xticks([])
|
|
plt.yticks([])
|
|
plt.grid(False)
|
|
plt.imshow(X_train[i])
|
|
plt.xlabel(class_names[y_train[i][0]])
|
|
plt.show()
|
|
```
|
|

|
|
|
|
**·после разбиения данных (между п. 3 и 4) вывести 25 изображений из обучающей выборки с подписями классов**
|
|
```py
|
|
# Пункт 4: Предобработка данных
|
|
num_classes = 10
|
|
input_shape = (32, 32, 3)
|
|
|
|
# Нормализация
|
|
X_train = X_train.astype('float32') / 255
|
|
X_test = X_test.astype('float32') / 255
|
|
|
|
# One-hot encoding
|
|
y_train_categorical = keras.utils.to_categorical(y_train, num_classes)
|
|
y_test_categorical = keras.utils.to_categorical(y_test, num_classes)
|
|
```
|
|
|
|
```py
|
|
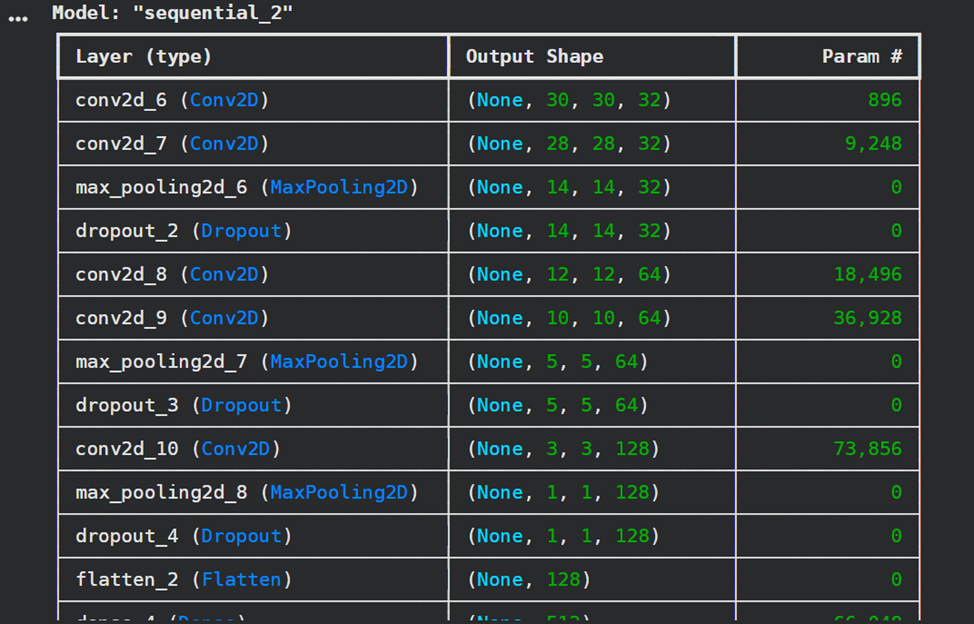
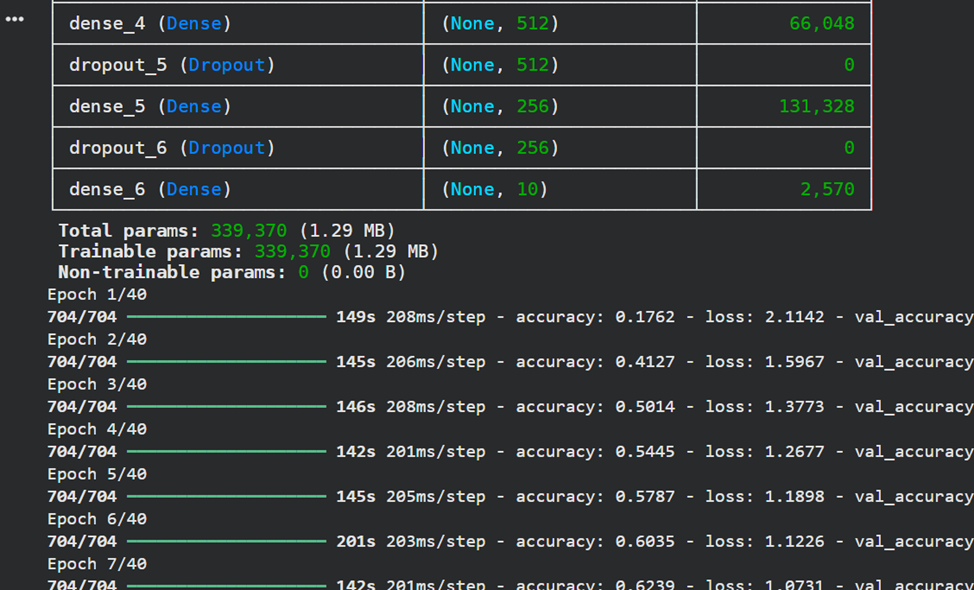
# Пункт 5: Создание и обучение модели
|
|
model = Sequential()
|
|
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape))
|
|
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu"))
|
|
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
|
model.add(layers.Dropout(0.25))
|
|
|
|
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
|
|
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
|
|
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
|
model.add(layers.Dropout(0.25))
|
|
|
|
model.add(layers.Conv2D(128, kernel_size=(3, 3), activation="relu"))
|
|
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
|
model.add(layers.Dropout(0.25))
|
|
|
|
model.add(layers.Flatten())
|
|
model.add(layers.Dense(512, activation='relu'))
|
|
model.add(layers.Dropout(0.5))
|
|
model.add(layers.Dense(256, activation='relu'))
|
|
model.add(layers.Dropout(0.5))
|
|
model.add(layers.Dense(num_classes, activation="softmax"))
|
|
|
|
model.summary()
|
|
|
|
# Компиляция и обучение модели с более медленным learning rate
|
|
model.compile(loss="categorical_crossentropy",
|
|
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
|
|
metrics=["accuracy"])
|
|
|
|
batch_size = 64
|
|
epochs = 40
|
|
|
|
history = model.fit(X_train, y_train_categorical,
|
|
batch_size=batch_size,
|
|
epochs=epochs,
|
|
validation_split=0.1,
|
|
verbose=1)
|
|
```
|
|
|
|
|
|
|
|
```py
|
|
# Визуализация процесса обучения
|
|
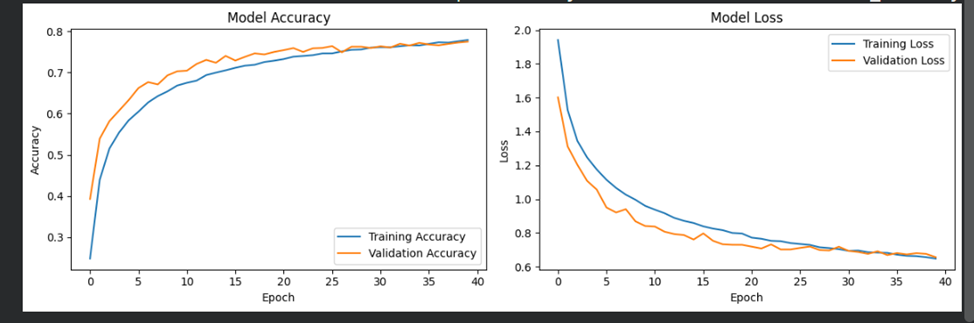
plt.figure(figsize=(12, 4))
|
|
plt.subplot(1, 2, 1)
|
|
plt.plot(history.history['accuracy'], label='Training Accuracy')
|
|
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
|
|
plt.title('Model Accuracy')
|
|
plt.xlabel('Epoch')
|
|
plt.ylabel('Accuracy')
|
|
plt.legend()
|
|
|
|
plt.subplot(1, 2, 2)
|
|
plt.plot(history.history['loss'], label='Training Loss')
|
|
plt.plot(history.history['val_loss'], label='Validation Loss')
|
|
plt.title('Model Loss')
|
|
plt.xlabel('Epoch')
|
|
plt.ylabel('Loss')
|
|
plt.legend()
|
|
plt.tight_layout()
|
|
plt.show()
|
|
```
|
|
|
|
|
|
```py
|
|
# Пункт 6: Оценка качества
|
|
test_loss, test_accuracy = model.evaluate(X_test, y_test_categorical, verbose=0)
|
|
print(f"Test loss: {test_loss:.4f}")
|
|
print(f"Test accuracy: {test_accuracy:.4f}")
|
|
```
|
|
|
|
|
|
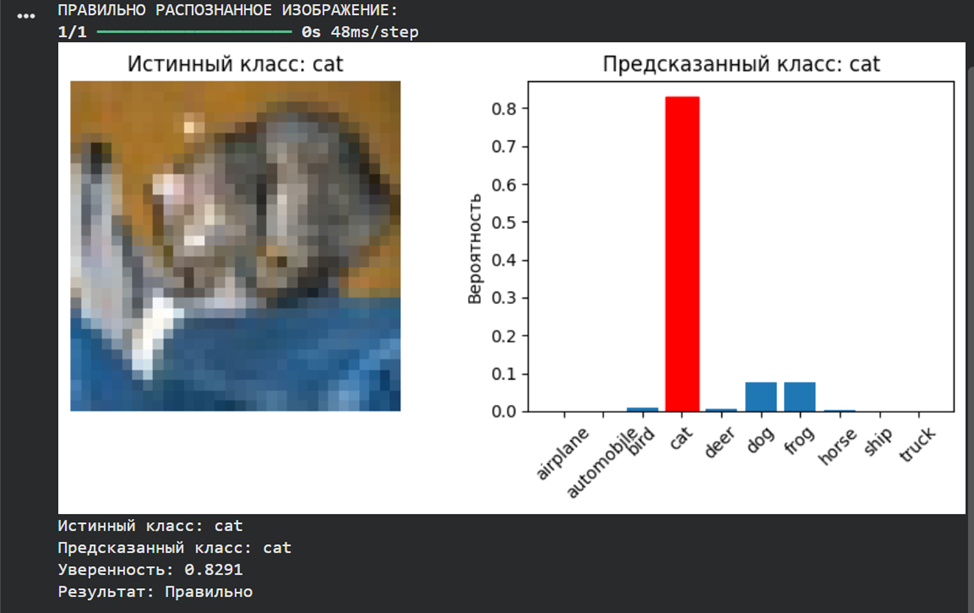
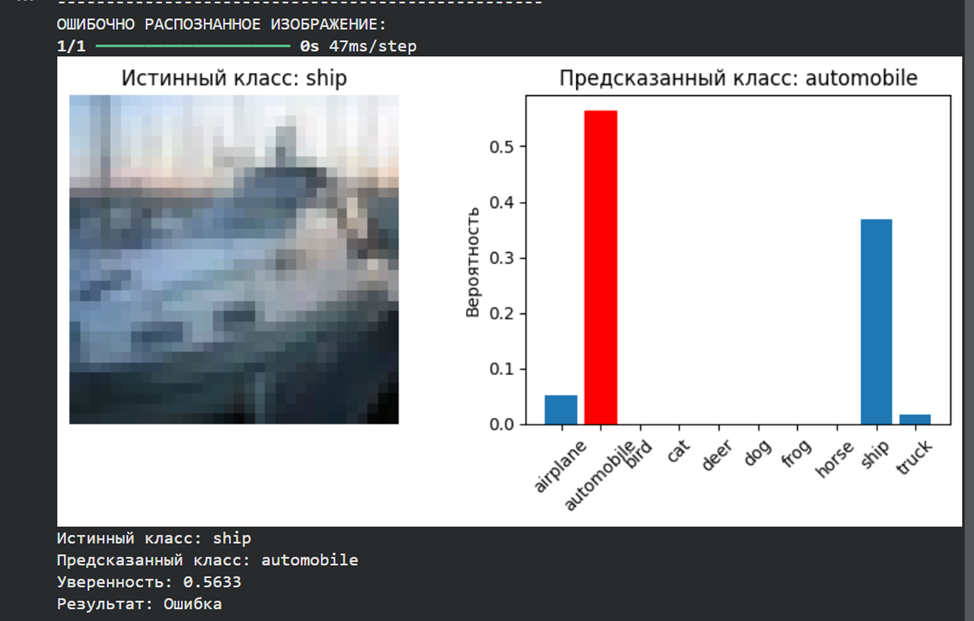
**· в п. 7 одно из тестовых изображений должно распознаваться корректно, а другое – ошибочно**
|
|
```py
|
|
# Пункт 7: Распознавание двух тестовых изображений
|
|
print("РАСПОЗНАВАНИЕ ТЕСТОВЫХ ИЗОБРАЖЕНИЙ:")
|
|
|
|
# Функция для распознавания одного изображения из тестовой выборки
|
|
def predict_single_image(model, X, y, index, class_names):
|
|
prediction = model.predict(X[index:index+1])
|
|
predicted_class = np.argmax(prediction[0])
|
|
true_class = y[index][0]
|
|
|
|
plt.figure(figsize=(8, 4))
|
|
|
|
plt.subplot(1, 2, 1)
|
|
plt.imshow(X[index])
|
|
plt.title(f'Истинный класс: {class_names[true_class]}')
|
|
plt.axis('off')
|
|
|
|
plt.subplot(1, 2, 2)
|
|
bars = plt.bar(range(10), prediction[0])
|
|
# Подсветим предсказанный класс
|
|
bars[predicted_class].set_color('red')
|
|
plt.xticks(range(10), class_names, rotation=45)
|
|
plt.title(f'Предсказанный класс: {class_names[predicted_class]}')
|
|
plt.ylabel('Вероятность')
|
|
plt.tight_layout()
|
|
plt.show()
|
|
|
|
print(f"Истинный класс: {class_names[true_class]}")
|
|
print(f"Предсказанный класс: {class_names[predicted_class]}")
|
|
print(f"Уверенность: {np.max(prediction[0]):.4f}")
|
|
print(f"Результат: {'Правильно' if predicted_class == true_class else 'Ошибка'}")
|
|
print("-" * 50)
|
|
|
|
return predicted_class == true_class
|
|
|
|
# Найдем одно правильное и одно неправильное предсказание
|
|
print("Поиск правильного и неправильного предсказания...")
|
|
all_predictions = model.predict(X_test)
|
|
all_predicted_classes = np.argmax(all_predictions, axis=1)
|
|
true_classes = y_test.flatten()
|
|
|
|
correct_indices = []
|
|
wrong_indices = []
|
|
|
|
for i in range(len(true_classes)):
|
|
if all_predicted_classes[i] == true_classes[i]:
|
|
correct_indices.append(i)
|
|
else:
|
|
wrong_indices.append(i)
|
|
|
|
if len(correct_indices) > 0 and len(wrong_indices) > 0:
|
|
break
|
|
|
|
if correct_indices:
|
|
print("ПРАВИЛЬНО РАСПОЗНАННОЕ ИЗОБРАЖЕНИЕ:")
|
|
predict_single_image(model, X_test, y_test, correct_indices[0], class_names)
|
|
|
|
if wrong_indices:
|
|
print("ОШИБОЧНО РАСПОЗНАННОЕ ИЗОБРАЖЕНИЕ:")
|
|
predict_single_image(model, X_test, y_test, wrong_indices[0], class_names)
|
|
```
|
|
|
|
|
|
|
|
```py
|
|
# Пункт 8: Отчет о качестве классификации и матрица ошибок
|
|
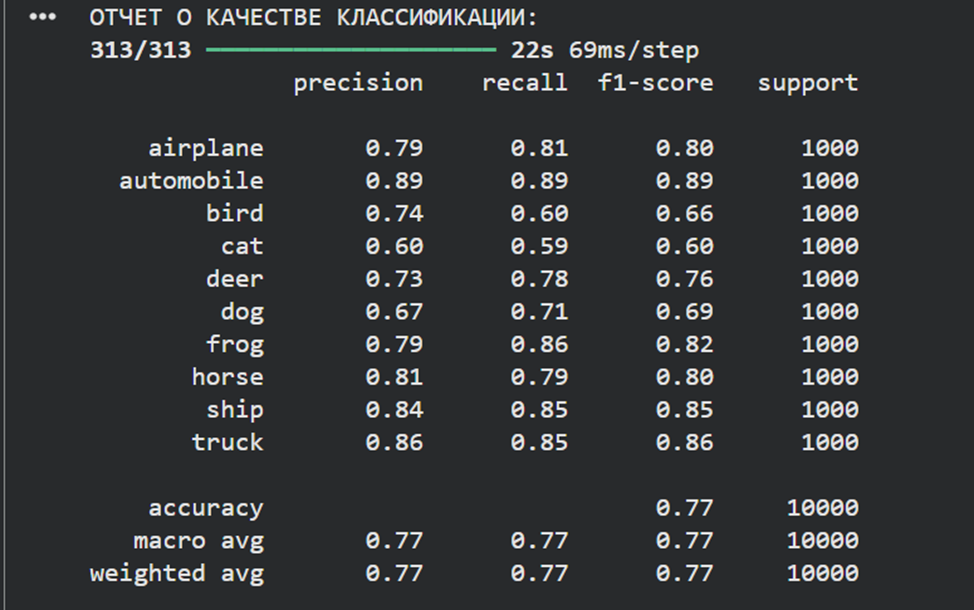
print("ОТЧЕТ О КАЧЕСТВЕ КЛАССИФИКАЦИИ:")
|
|
true_labels = np.argmax(y_test_categorical, axis=1)
|
|
predicted_labels = np.argmax(model.predict(X_test), axis=1)
|
|
|
|
print(classification_report(true_labels, predicted_labels, target_names=class_names))
|
|
|
|
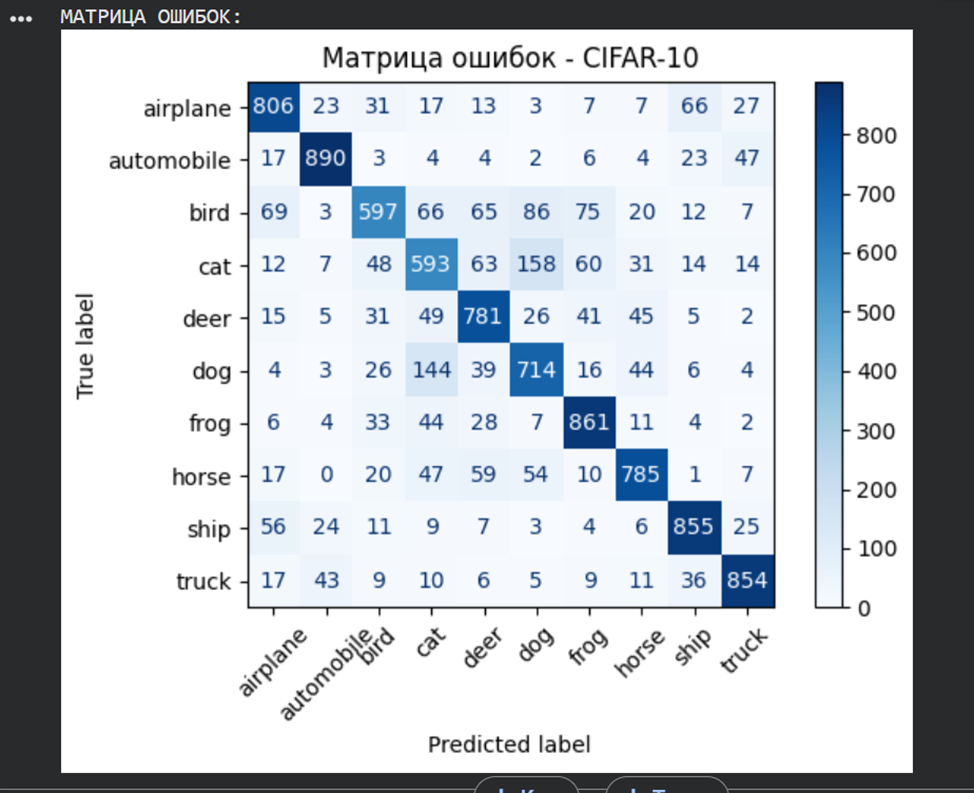
print("МАТРИЦА ОШИБОК:")
|
|
conf_matrix = confusion_matrix(true_labels, predicted_labels)
|
|
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix, display_labels=class_names)
|
|
display.plot(cmap=plt.cm.Blues, xticks_rotation=45)
|
|
plt.title('Матрица ошибок - CIFAR-10')
|
|
plt.tight_layout()
|
|
plt.show()
|
|
```
|
|
|
|
|
|
|
|
Итоговый вывод:
|
|
CNN способна решать задачи классификации цветных изображений, однако её точность снижается при увеличении сложности данных. Для улучшения результатов требуются более глубокие архитектуры, аугментация данных и тонкая настройка гиперпараметров.
|
|
|
|
**Общий вывод по лр 3:
|
|
Сверточные нейронные сети являются мощным инструментом для задач компьютерного зрения. CNN эффективно обрабатывают пространственные иерархии признаков, что делает их предпочтительными для работы с изображениями по сравнению с полносвязными сетями. Качество классификации зависит от сложности данных, архитектуры сети и корректности предобработки. Использование методов регуляризации (Dropout) и аугментации данных может улучшить обобщающую способность модели. Интерпретация матрицы ошибок и метрик качества позволяет анализировать слабые места модели и направлять её доработку.** |