Сравнить коммиты
2 Коммитов
| Автор | SHA1 | Дата |
|---|---|---|
|
|
964549a094 | 2 месяцев назад |
|
|
b344e76a21 | 3 месяцев назад |
{kind=link}
|
До Ширина: | Высота: | Размер: 242 B |
{kind=link}
|
До Ширина: | Высота: | Размер: 216 B |
{kind=link}
|
До Ширина: | Высота: | Размер: 6.4 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 6.7 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 6.9 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 6.6 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 338 B |
{kind=link}
|
До Ширина: | Высота: | Размер: 7.1 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 6.6 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 345 B |
{kind=link}
|
До Ширина: | Высота: | Размер: 29 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 28 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 28 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 28 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 29 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 30 KiB |
@ -1,4 +1,11 @@
|
|||||||
|
## Лабораторныа работа №1
|
||||||
|
|
||||||
|
## Архитектура и обучение глубоких нейронных сетей
|
||||||
|
|
||||||
* [Задание](IS_Lab01_2023.pdf)
|
* [Задание](IS_Lab01_2023.pdf)
|
||||||
|
|
||||||
* [Методические указания](IS_Lab01_Metod_2023.pdf)
|
* [Методические указания](IS_Lab01_Metod_2023.pdf)
|
||||||
|
|
||||||
* <a href="https://youtube.com/playlist?list=PLfdZ2TeaMzfzlpZ60rbaYU_epH5XPNbWU" target="_blank"><s>Какие нейроны, что вообще происходит?</s> Рекомендуется к просмотру для понимания (4 видео)</a>
|
* <a href="https://youtube.com/playlist?list=PLfdZ2TeaMzfzlpZ60rbaYU_epH5XPNbWU" target="_blank"><s>Какие нейроны, что вообще происходит?</s> Рекомендуется к просмотру для понимания (4 видео)</a>
|
||||||
|
|
||||||
* <a href="https://www.youtube.com/watch?v=FwFduRA_L6Q" target="_blank">Почувствуйте себя пионером нейронных сетей в области распознавания образов</a>
|
* <a href="https://www.youtube.com/watch?v=FwFduRA_L6Q" target="_blank">Почувствуйте себя пионером нейронных сетей в области распознавания образов</a>
|
||||||
@ -1 +0,0 @@
|
|||||||
{"nbformat":4,"nbformat_minor":0,"metadata":{"colab":{"provenance":[],"authorship_tag":"ABX9TyPC/SZVlsvuucft1t0l8Bhx"},"kernelspec":{"name":"python3","display_name":"Python 3"},"language_info":{"name":"python"}},"cells":[{"cell_type":"code","execution_count":1,"metadata":{"id":"lXNlZGHIqxlV","executionInfo":{"status":"error","timestamp":1758531901705,"user_tz":-180,"elapsed":50,"user":{"displayName":"Данила Новиков","userId":"16029008369036023959"}},"outputId":"a6271035-c2c2-40e1-e2cd-c4cee8035df6","colab":{"base_uri":"https://localhost:8080/","height":211}},"outputs":[{"output_type":"error","ename":"FileNotFoundError","evalue":"[Errno 2] No such file or directory: '/content/drive/MyDrive/Colab Notebooks'","traceback":["\u001b[0;31m---------------------------------------------------------------------------\u001b[0m","\u001b[0;31mFileNotFoundError\u001b[0m Traceback (most recent call last)","\u001b[0;32m/tmp/ipython-input-1074595868.py\u001b[0m in \u001b[0;36m<cell line: 0>\u001b[0;34m()\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0;31m#пункт 1\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2\u001b[0m \u001b[0;32mimport\u001b[0m \u001b[0mos\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 3\u001b[0;31m \u001b[0mos\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mchdir\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m'/content/drive/MyDrive/Colab Notebooks'\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 4\u001b[0m \u001b[0;31m# импорт модулей\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 5\u001b[0m \u001b[0;32mfrom\u001b[0m \u001b[0mtensorflow\u001b[0m \u001b[0;32mimport\u001b[0m \u001b[0mkeras\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n","\u001b[0;31mFileNotFoundError\u001b[0m: [Errno 2] No such file or directory: '/content/drive/MyDrive/Colab Notebooks'"]}],"source":["#пункт 1\n","import os\n","os.chdir('/content/drive/MyDrive/Colab Notebooks')\n","# импорт модулей\n","from tensorflow import keras\n","import matplotlib.pyplot as plt\n","import numpy as np\n","import sklearn\n","\n","#пункт 2\n","# загрузка датасета\n","from keras.datasets import mnist\n","(X_train, y_train), (X_test, y_test) = mnist.load_data()\n","\n","#пункт 3\n","# создание своего разбиения датасета\n","from sklearn.model_selection import train_test_split\n","# объединяем в один набор\n","X = np.concatenate((X_train, X_test))\n","y = np.concatenate((y_train, y_test))\n","# разбиваем по вариантам\n","X_train, X_test, y_train, y_test = train_test_split(X, y,\n"," test_size = 10000,\n"," train_size = 60000,\n"," random_state = 123)\n","# вывод размерностей\n","print('Shape of X train:', X_train.shape)\n","print('Shape of y train:', y_train.shape)\n","\n","#пункт 4\n","# вывод изображения 1\n","plt.imshow(X_train[0], cmap=plt.get_cmap('gray'))\n","plt.show()\n","# вывод метки для этого изображения\n","print(y_train[0])\n","# вывод изображения 2\n","plt.imshow(X_train[1], cmap=plt.get_cmap('gray'))\n","plt.show()\n","# вывод метки для этого изображения\n","print(y_train[1])\n","# вывод изображения 3\n","plt.imshow(X_train[2], cmap=plt.get_cmap('gray'))\n","plt.show()\n","# вывод метки для этого изображения\n","print(y_train[2])\n","# вывод изображения 4\n","plt.imshow(X_train[3], cmap=plt.get_cmap('gray'))\n","plt.show()\n","# вывод метки для этого изображения\n","print(y_train[3])\n","\n","\n","#пункт 5\n","# развернем каждое изображение 28*28 в вектор 784\n","num_pixels = X_train.shape[1] * X_train.shape[2]\n","X_train = X_train.reshape(X_train.shape[0], num_pixels) / 255\n","X_test = X_test.reshape(X_test.shape[0], num_pixels) / 255\n","print('Shape of transformed X train:', X_train.shape)\n","\n","# переведем метки в one-hot\n","\n","from keras.utils import np_utils\n","y_train = np_utils.to_categorical(y_train)\n","y_test = np_utils.to_categorical(y_test)\n","print('Shape of transformed y train:', y_train.shape)\n","num_classes = y_train.shape[1]\n","\n","print('Shape of transformed X test:', X_test.shape)\n","print('Shape of transformed Y test:', y_test.shape)\n"]}]}
|
|
||||||
{kind=link}
|
До Ширина: | Высота: | Размер: 60 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 58 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 20 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 41 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 19 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 4.8 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 48 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 9.7 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 5.5 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 146 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 35 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 90 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 238 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 38 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 81 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 194 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 24 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 11 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 80 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 26 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 31 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 113 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 3.3 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 67 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 16 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 159 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 77 KiB |
@ -1,4 +1,11 @@
|
|||||||
|
## Лабораторныа работа №2
|
||||||
|
|
||||||
|
## Обнаружение аномалий
|
||||||
|
|
||||||
* [Задание](IS_Lab02_2023.pdf)
|
* [Задание](IS_Lab02_2023.pdf)
|
||||||
|
|
||||||
* [Методические указания](IS_Lab02_Metod_2023.pdf)
|
* [Методические указания](IS_Lab02_Metod_2023.pdf)
|
||||||
|
|
||||||
* [Наборы данных](data)
|
* [Наборы данных](data)
|
||||||
|
|
||||||
* [Библиотека для автокодировщиков](lab02_lib.py)
|
* [Библиотека для автокодировщиков](lab02_lib.py)
|
||||||
@ -1,245 +0,0 @@
|
|||||||
**ЛАБОРАТОРНАЯ РАБОТА №2**«Обнаружение аномалий»**
|
|
||||||
А-02-22 бригада №8 Левшенко Д.И., Новиков Д. М., Шестов Д.Н
|
|
||||||
|
|
||||||
Задание1:
|
|
||||||
|
|
||||||
**1)В среде GoogleColabсоздать новый блокнот(notebook).Импортировать необходимые для работы библиотеки и модули.**
|
|
||||||
```py
|
|
||||||
import os
|
|
||||||
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab2')
|
|
||||||
|
|
||||||
!wget -N http://uit.mpei.ru/git/main/is_dnn/raw/branch/main/labworks/LW2/lab02_lib.py
|
|
||||||
|
|
||||||
!wget -N http://uit.mpei.ru/git/main/is_dnn/raw/branch/main/labworks/LW2/data/name_train.txt
|
|
||||||
!wget -N http://uit.mpei.ru/git/main/is_dnn/raw/branch/main/labworks/LW2/data/name_test.txt
|
|
||||||
|
|
||||||
import numpy as np
|
|
||||||
import lab02_lib as lib
|
|
||||||
```
|
|
||||||
**2)Сгенерировать индивидуальный набор двумерных данныхв пространстве признаковс координатами центра (k, k), где k–номер бригады.Вывести полученныеданные на рисуноки в консоль.**
|
|
||||||
```py
|
|
||||||
data = lib.datagen(8, 8, 1000, 2)
|
|
||||||
```
|
|
||||||
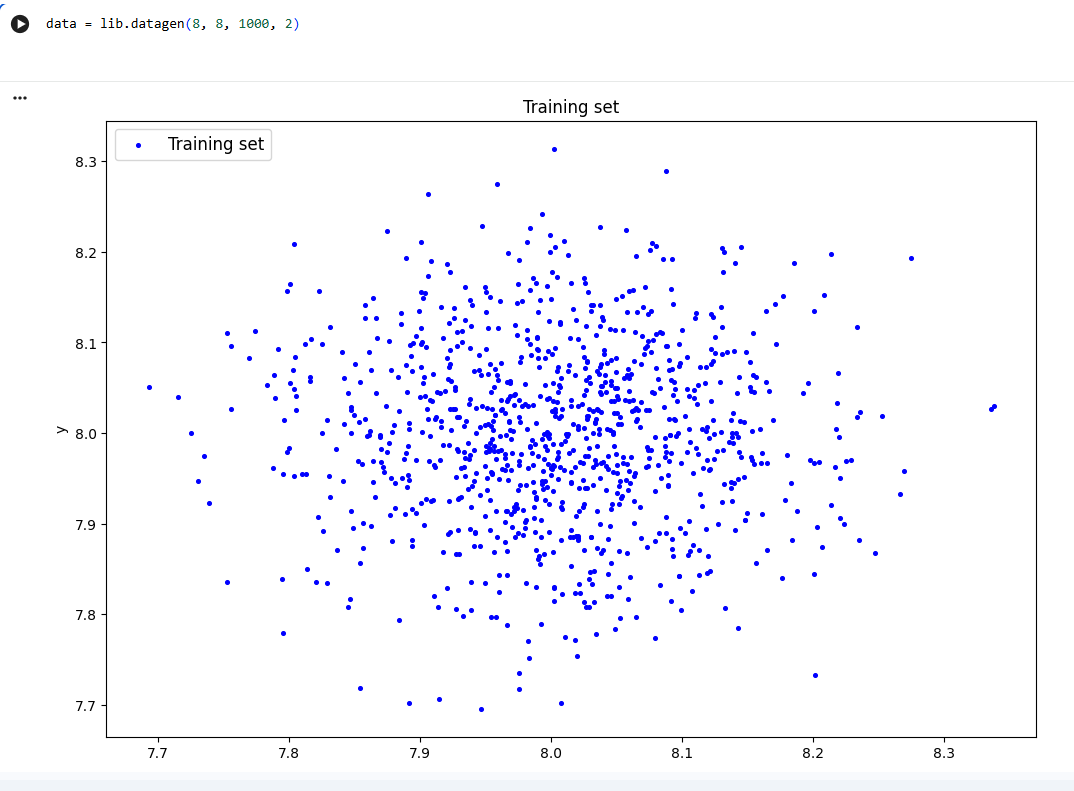
|
|
||||||
|
|
||||||
**3)Создать и обучить автокодировщик AE1 простой архитектуры, выбрав небольшое количество эпох обучения.**
|
|
||||||
```py
|
|
||||||
patience= 300
|
|
||||||
ae1_trained, IRE1, IREth1= lib.create_fit_save_ae(data,'out/AE1.h5','out/AE1_ire_th.txt', 1000, True, patience)
|
|
||||||
```
|
|
||||||

|
|
||||||
**4)Зафиксировать ошибку MSE, на которой обучение завершилось. Построить график ошибки реконструкции обучающей выборки. Зафиксировать порог ошибки реконструкции –порог обнаружения аномалий.**
|
|
||||||
```py
|
|
||||||
lib.ire_plot('training', IRE1, IREth1, 'AE1')
|
|
||||||
```
|
|
||||||

|
|
||||||
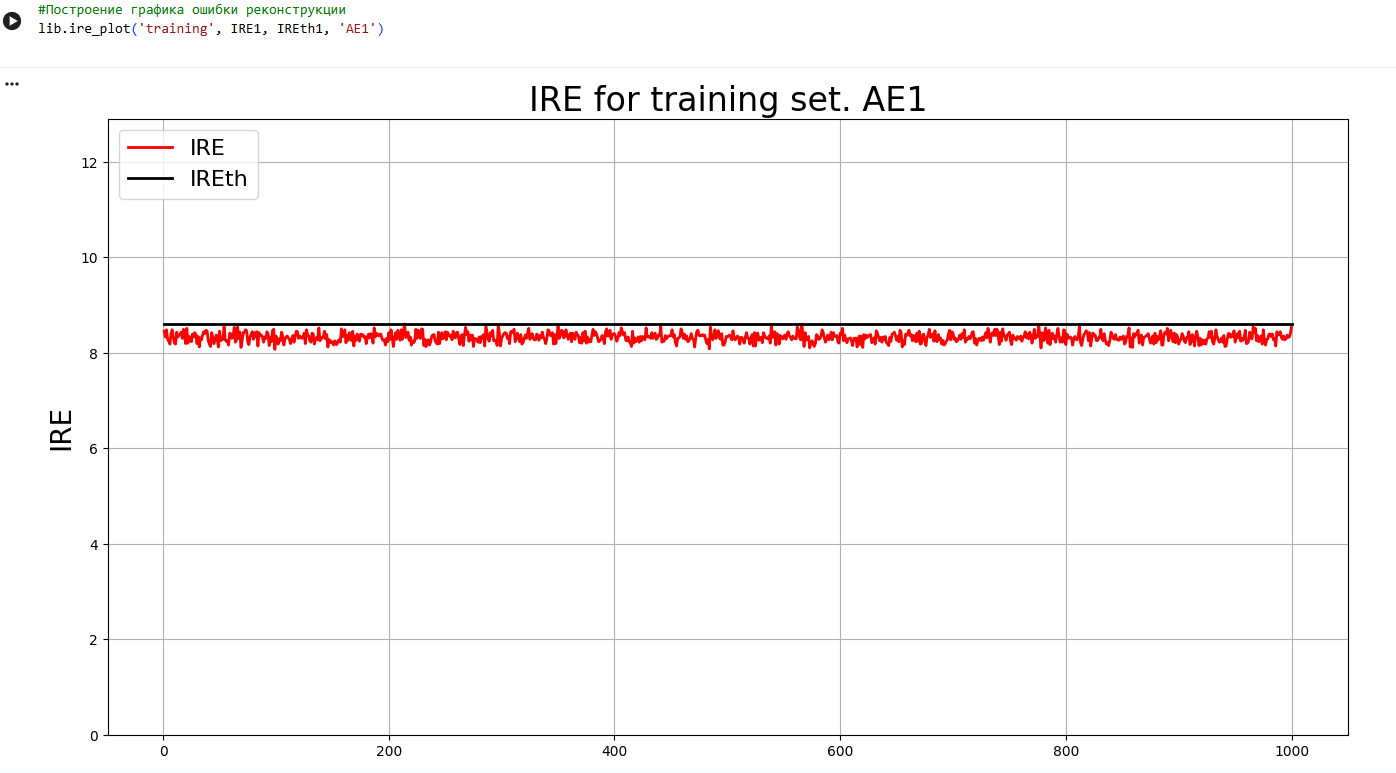
|
|
||||||
**5)Создать и обучить второй автокодировщик AE2 с усложненной архитектурой, задав большее количество эпох обучения.**
|
|
||||||
```py
|
|
||||||
ae2_trained, IRE2, IREth2 = lib.create_fit_save_ae(data,'out/AE2.h5','out/AE2_ire_th.txt', 3000, True, patience)
|
|
||||||
```
|
|
||||||

|
|
||||||
**6)Зафиксировать ошибку MSE, на которой обучение завершилось. Построить график ошибки реконструкции обучающей выборки. Зафиксировать второй порог ошибки реконструкции –порог обнаружения аномалий.**
|
|
||||||
```py
|
|
||||||
lib.ire_plot('training', IRE2, IREth2, 'AE2')
|
|
||||||
```
|
|
||||||

|
|
||||||
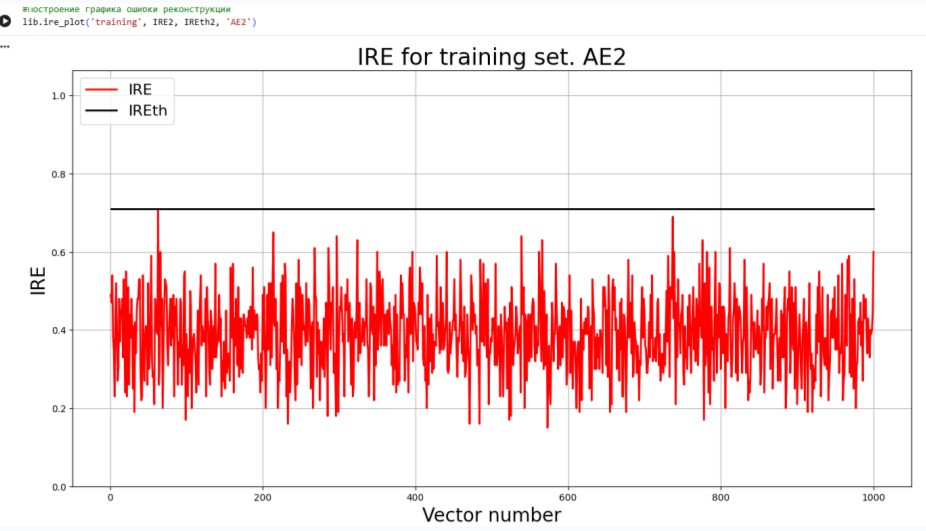
|
|
||||||
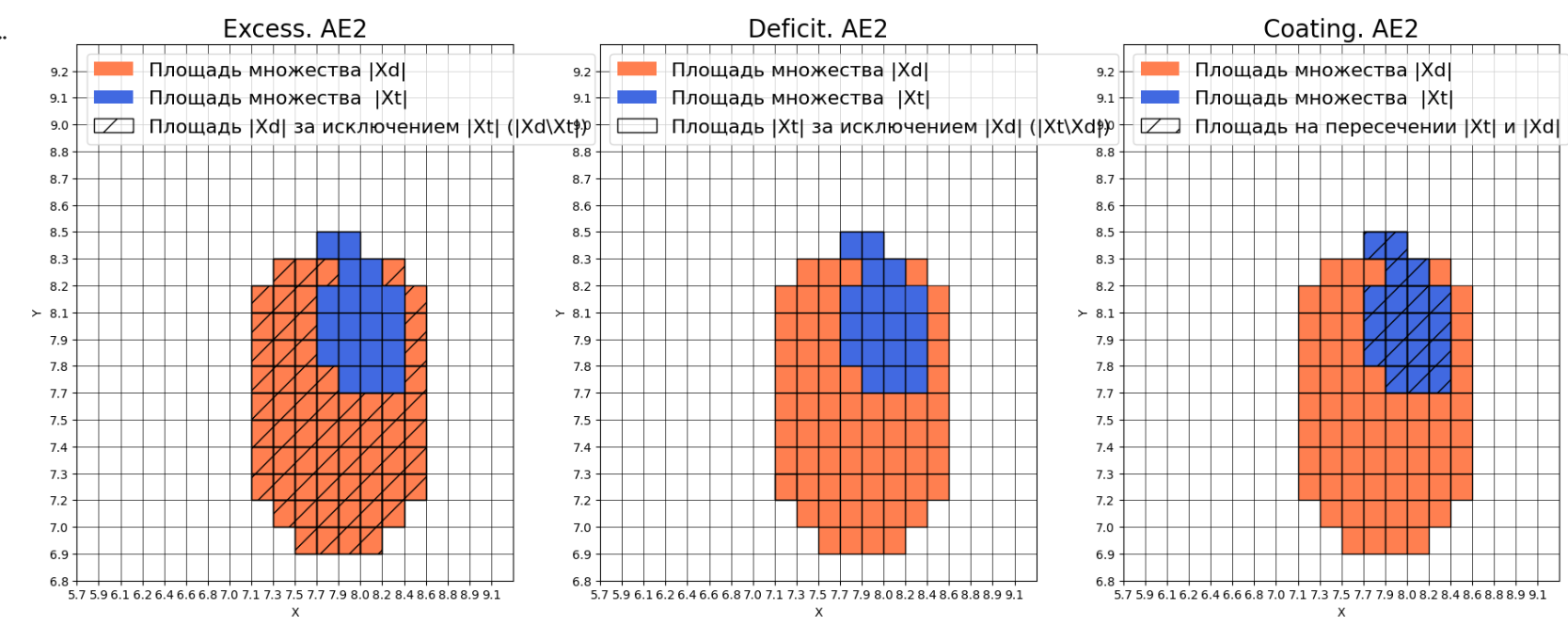
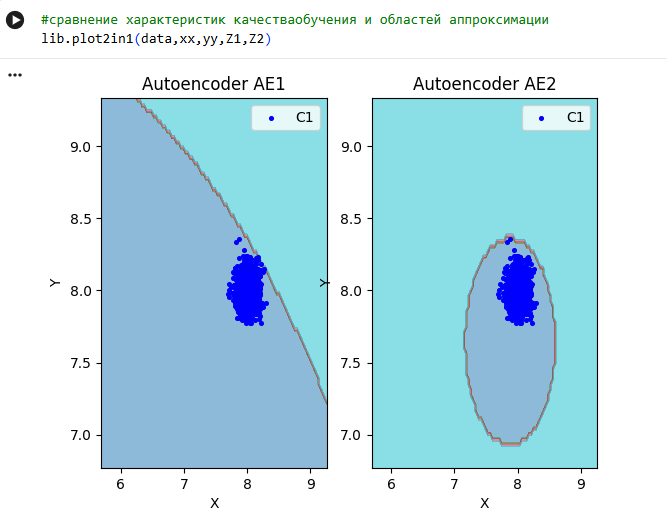
**7)Рассчитать характеристики качества обучения EDCA для AE1 и AE2. Визуализировать и сравнить области пространства признаков, распознаваемые автокодировщиками AE1 и AE2. Сделать вывод о пригодности AE1 и AE2 для качественного обнаружения аномалий.**
|
|
||||||
```py
|
|
||||||
numb_square= 20
|
|
||||||
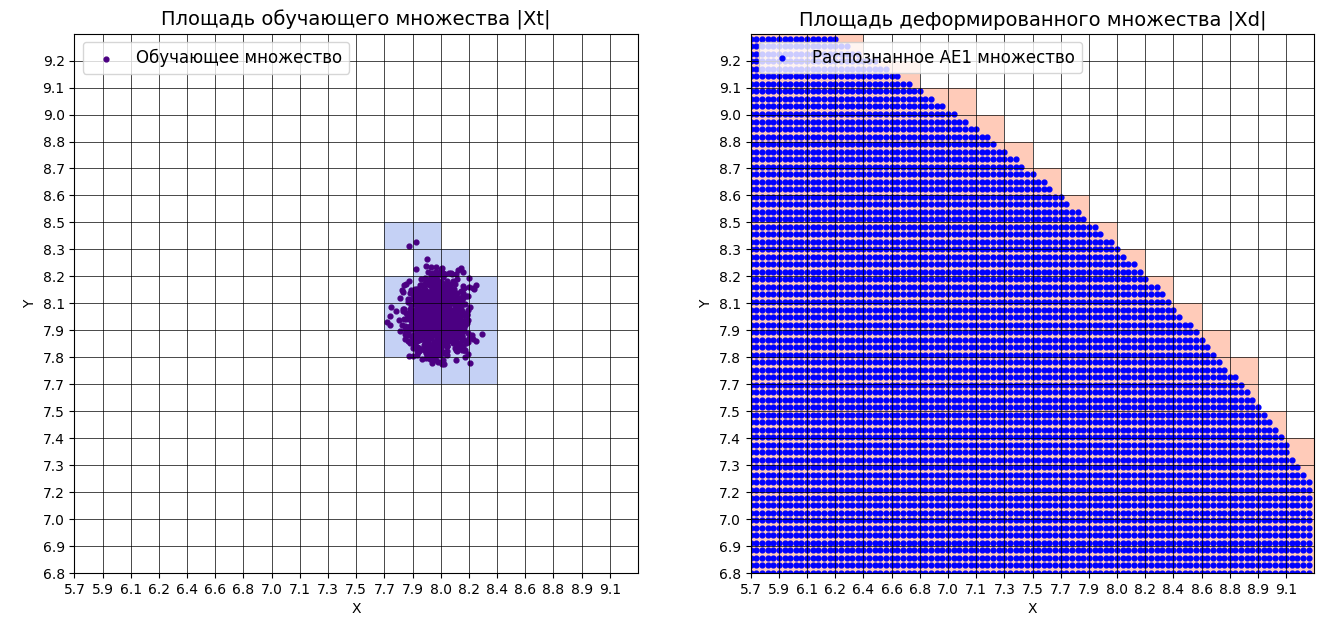
xx,yy,Z1=lib.square_calc(numb_square,data,ae1_trained,IREth1,'1',True)
|
|
||||||
|
|
||||||
Оценка качества AE1
|
|
||||||
IDEAL = 0. Excess: 14.263157894736842
|
|
||||||
IDEAL = 0. Deficit: 0.0
|
|
||||||
IDEAL = 1. Coating: 1.0
|
|
||||||
summa: 1.0
|
|
||||||
IDEAL = 1. Extrapolation precision (Approx): 0.06551724137931035
|
|
||||||
|
|
||||||
numb_square = 20
|
|
||||||
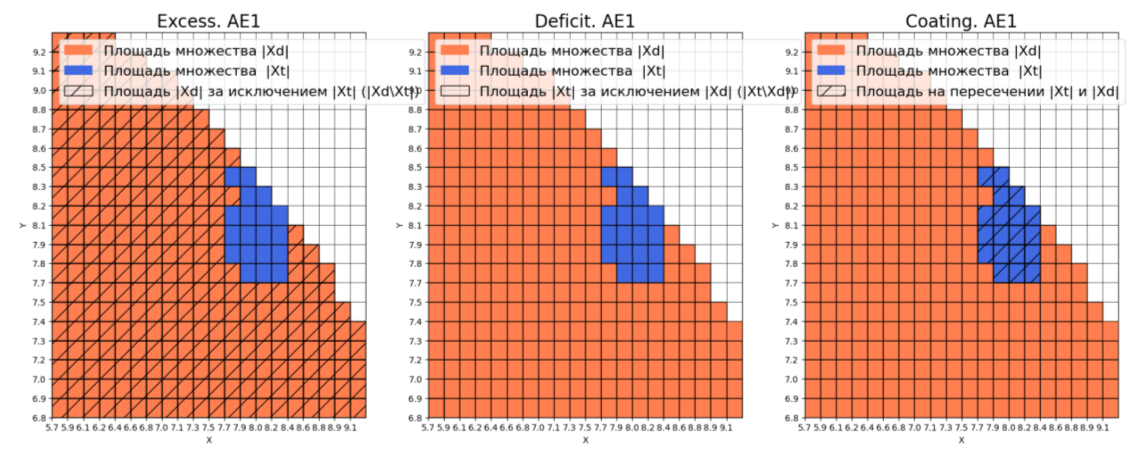
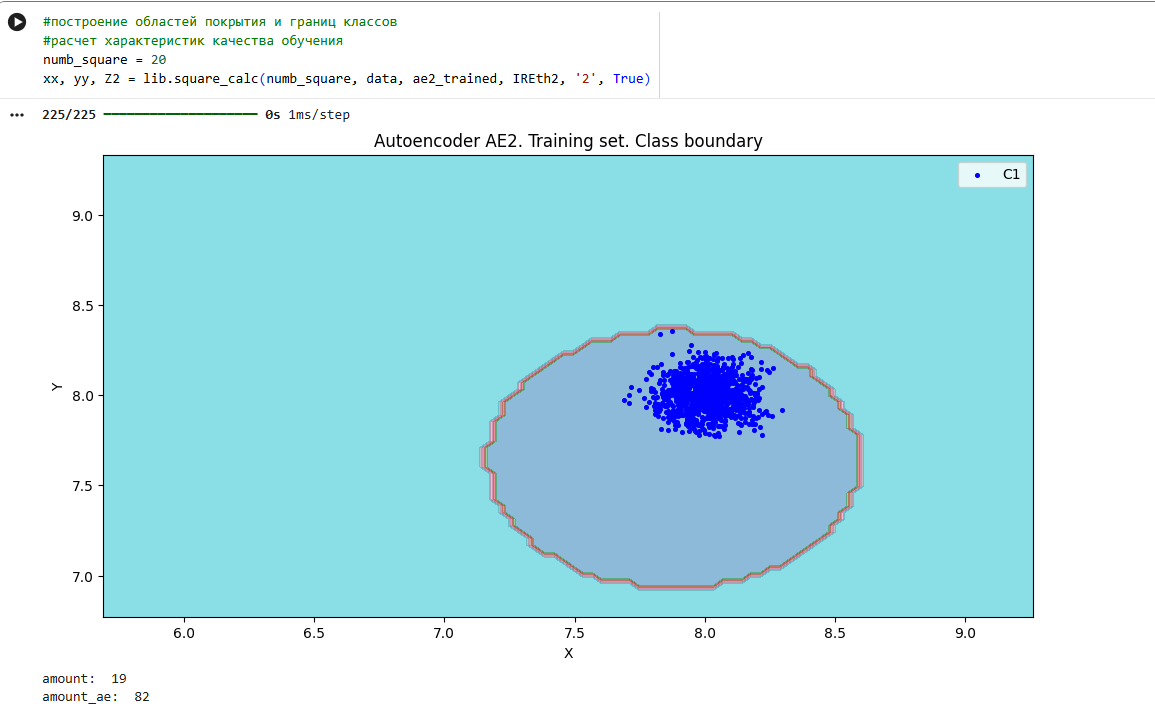
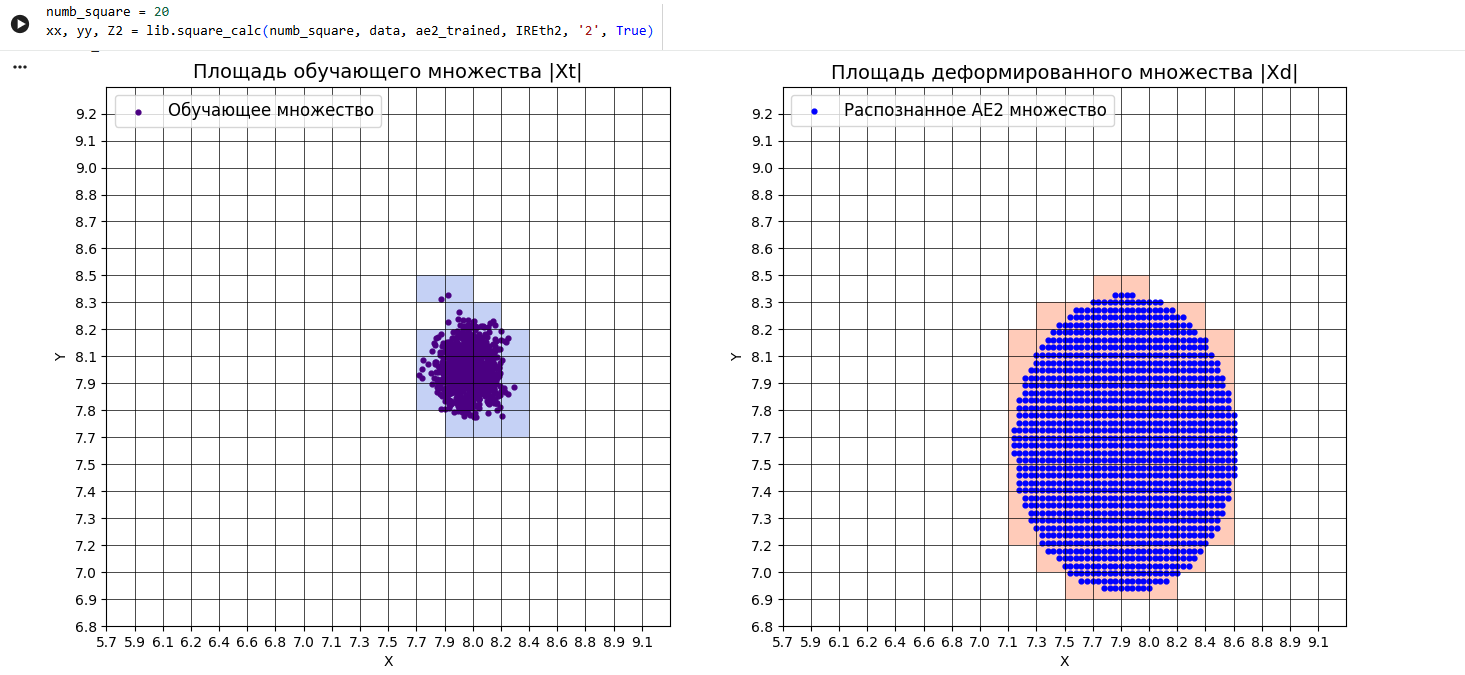
xx, yy, Z2 = lib.square_calc(numb_square, data, ae2_trained, IREth2, '2', True)
|
|
||||||
|
|
||||||
Оценка качества AE2
|
|
||||||
IDEAL = 0. Excess: 3.3157894736842106
|
|
||||||
IDEAL = 0. Deficit: 0.0
|
|
||||||
IDEAL = 1. Coating: 1.0
|
|
||||||
summa: 1.0
|
|
||||||
IDEAL = 1. Extrapolation precision (Approx): 0.23170731707317074
|
|
||||||
|
|
||||||
lib.plot2in1(data,xx,yy,Z1,Z2)
|
|
||||||
```
|
|
||||||
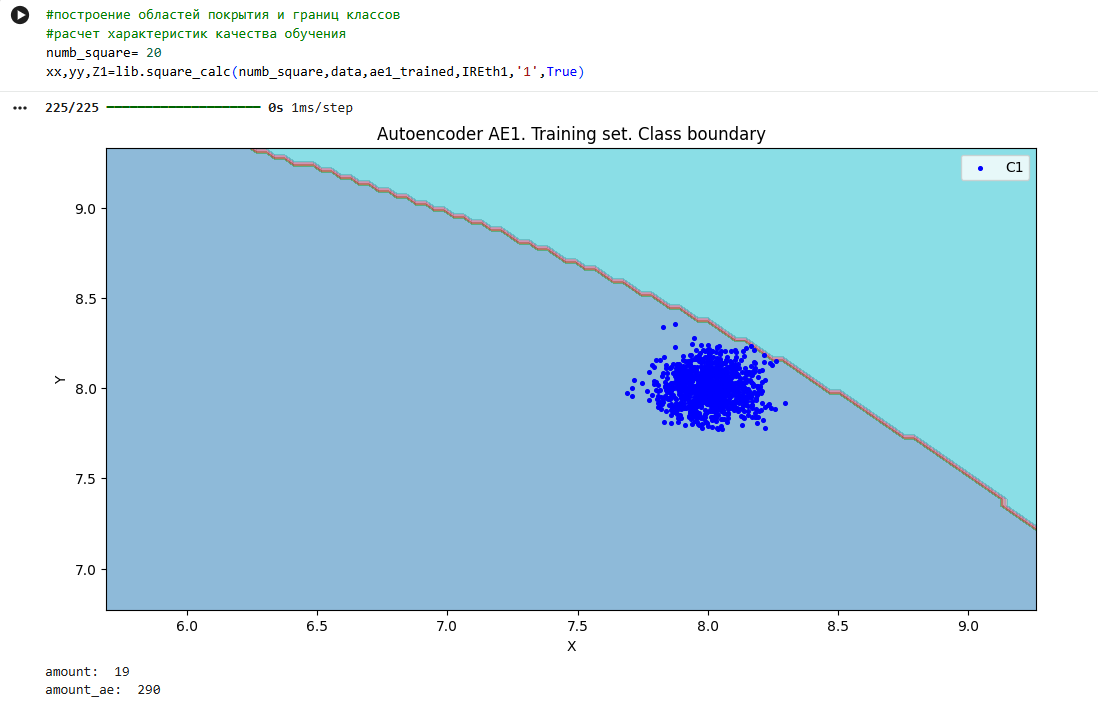
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**9)Изучить сохраненный набор данных и пространство признаков. Создать тестовую выборку, состоящую, как минимум, из 4ёх элементов, не входящих в обучающую выборку. Элементы должны быть такими, чтобы AE1 распознавал их как норму, а AE2 детектировал как аномалии.**
|
|
||||||
```py
|
|
||||||
data_test= np.loadtxt('data_test.txt', dtype=float)
|
|
||||||
```
|
|
||||||

|
|
||||||
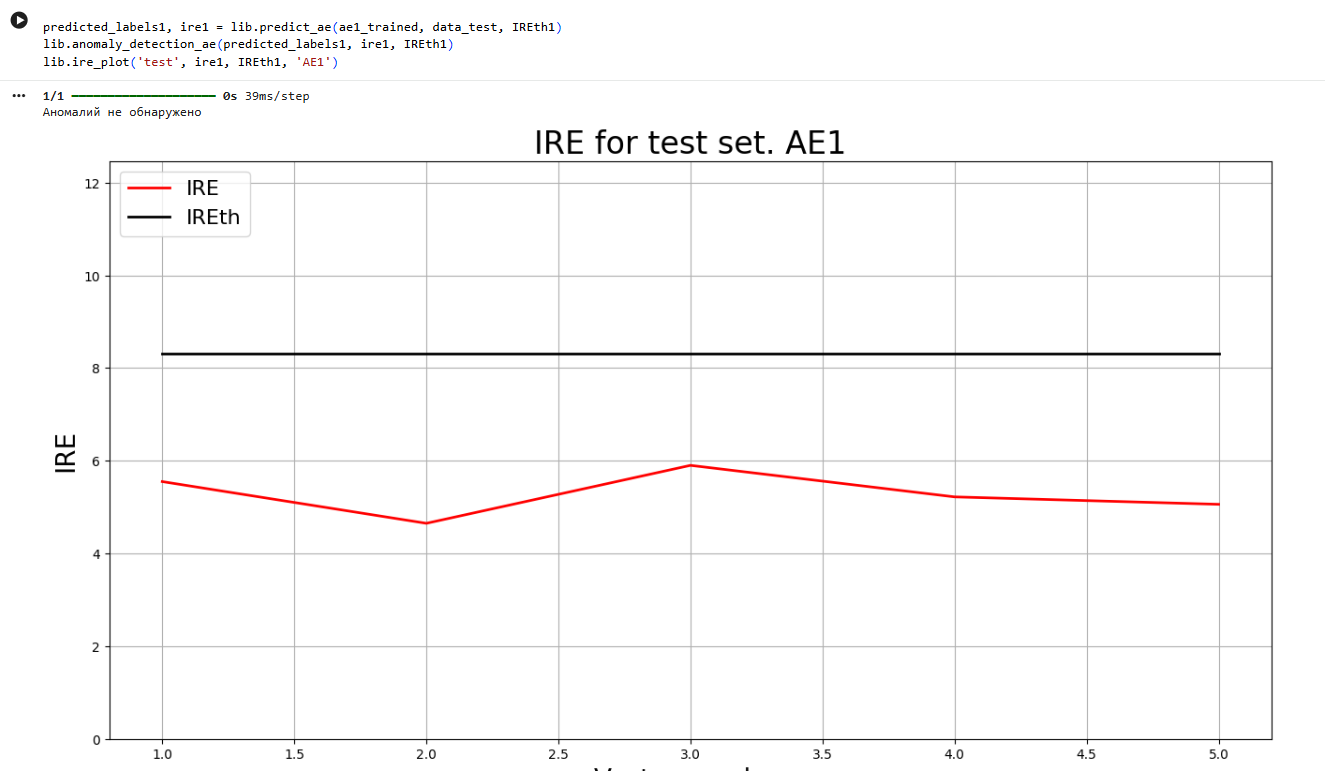
**10)Применить обученные автокодировщики AE1 и AE2 к тестовым данными вывести значения ошибки реконструкции для каждого элемента тестовой выборки относительно порога на график и в консоль.**
|
|
||||||
```py
|
|
||||||
predicted_labels1, ire1 = lib.predict_ae(ae1_trained, data_test, IREth1)
|
|
||||||
lib.anomaly_detection_ae(predicted_labels1, ire1, IREth1)
|
|
||||||
lib.ire_plot('test', ire1, IREth1, 'AE1')
|
|
||||||
```
|
|
||||||
|
|
||||||
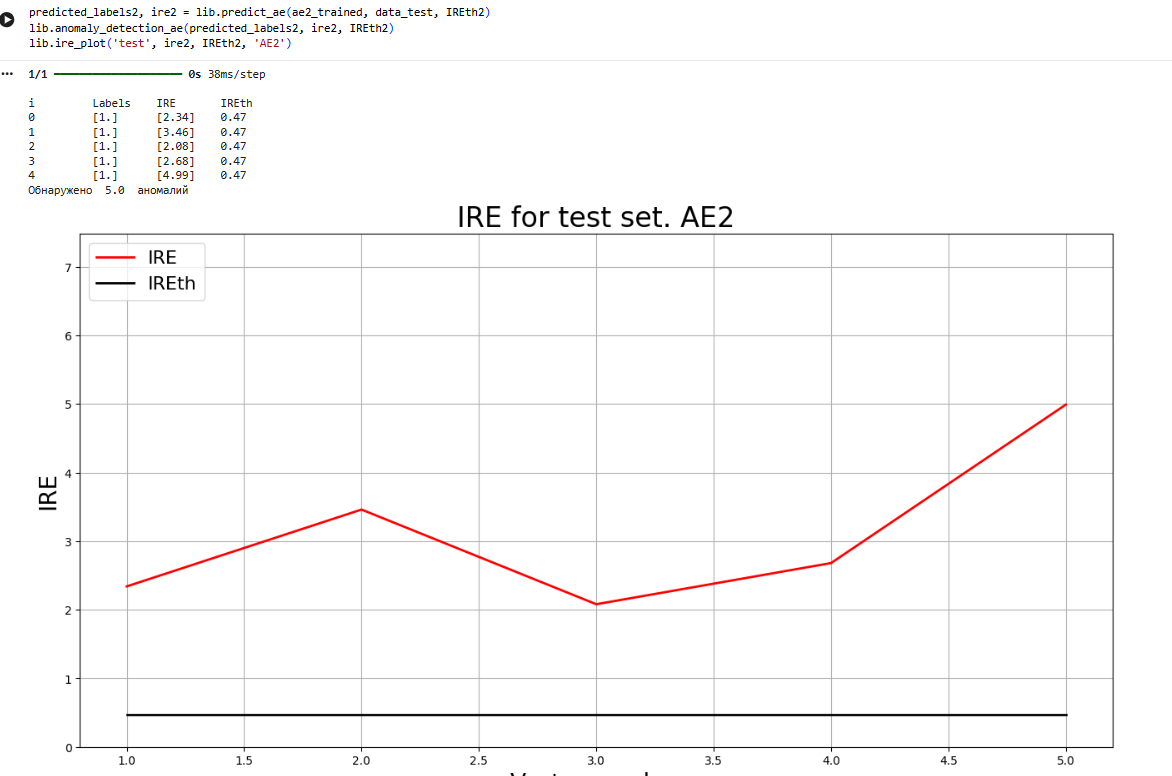
```py
|
|
||||||
predicted_labels2, ire2 = lib.predict_ae(ae2_trained, data_test, IREth2)
|
|
||||||
lib.anomaly_detection_ae(predicted_labels2, ire2, IREth2)
|
|
||||||
lib.ire_plot('test', ire2, IREth2, 'AE2')
|
|
||||||
|
|
||||||
|
|
||||||
i Labels IRE IREth
|
|
||||||
0 [1.] [2.34] 0.47
|
|
||||||
1 [1.] [3.46] 0.47
|
|
||||||
2 [1.] [2.08] 0.47
|
|
||||||
3 [1.] [2.68] 0.47
|
|
||||||
4 [1.] [4.99] 0.47
|
|
||||||
Обнаружено 5.0 аномалий
|
|
||||||
```
|
|
||||||
|
|
||||||
**11)Визуализировать элементы обучающей и тестовой выборки в областях пространства признаков, распознаваемых автокодировщиками AE1 и AE2.**
|
|
||||||
|
|
||||||
```py
|
|
||||||
lib.plot2in1_anomaly(data, xx, yy, Z1, Z2, data_test)
|
|
||||||
```
|
|
||||||
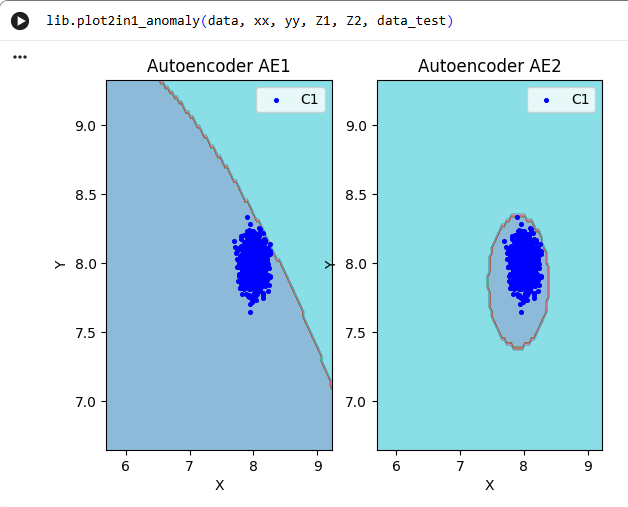
|
|
||||||
**12)Результаты исследования занести в таблицу:**
|
|
||||||
|
|
||||||
**Табл. 1 Результаты задания**
|
|
||||||
|
|
||||||
| | | | | | | | | |
|
|
||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
|
||||||
| | **Количество скрытых слоев** | **Количество нейронов в скрытых слоях** | **Количество эпох обучения** | **Ошибка MSE_stop** | **Порог ошибки реконструкции** | **Значение показателя Excess** | **Значение показателя Approx** | **Количество обнаруженных аномалий** |
|
|
||||||
| **АЕ1** | **1** | **1** | **1000** | **38.04** | **8.5** | **14.26** | **0.07** | **0** |
|
|
||||||
| **АЕ2** | **5** | **3 2 1 2 3** | **3000** | **0.07** | **0.47** | **3.32** | **0.23** | **5** |
|
|
||||||
|
|
||||||
**13)Сделать выводы**
|
|
||||||
|
|
||||||
Для нормального обнаружения аномалий:
|
|
||||||
\-архитектура автокодировщика не должна быть простой,
|
|
||||||
\-необходимо большое количество эпох обучения,
|
|
||||||
\-ошибка MSE_stop должна быть достаточно мала(<<1),
|
|
||||||
\-порог обнаружения аномалий не должен быть завышен по сравнению с
|
|
||||||
большинством значений ошибки реконструкции обучающей выборки,
|
|
||||||
\-характеристики качества обучения EDCA должны быть близки к идеальным значениям показателей Excess = 0, Deficit = 0, Coating = 1, Approx = 1.
|
|
||||||
|
|
||||||
|
|
||||||
**Задание2**
|
|
||||||
|
|
||||||
**1)Изучить описание своего набора реальных данных, что он из себя представляет;**
|
|
||||||
|
|
||||||
Исходный набор данных Breast Cancer Wisconsin из репозитория машинного обучения UCI представляет собой набор данных для классификации, в котором записываются измерения для случаев рака молочной железы. Есть два класса, доброкачественные и злокачественные. Злокачественный класс этого набора данных уменьшен до 21 точки, которые считаются аномалиями, в то время как точки в доброкачественном классе считаются нормой.
|
|
||||||
|
|
||||||
| | | | |
|
|
||||||
| --- | --- | --- | --- |
|
|
||||||
| Количество признаков | Количество примеров | Количесвто нормальных примеров | Количество аномальных примеров |
|
|
||||||
| 30 | 378 | 357 | 21 |
|
|
||||||
|
|
||||||
**2)Загрузить многомерную обучающую выборку реальных данных WBC_train.txt.**
|
|
||||||
```py
|
|
||||||
train = np.loadtxt('WBC_train.txt', dtype=float)
|
|
||||||
```
|
|
||||||

|
|
||||||
**3)Вывести полученные данные и их размерность в консоли.**
|
|
||||||
```py
|
|
||||||
print('Исходные данные:')
|
|
||||||
print(train)
|
|
||||||
print('Размерность данных:')
|
|
||||||
print(train.shape)
|
|
||||||
Исходные данные:
|
|
||||||
[[3.1042643e-01 1.5725397e-01 3.0177597e-01 ... 4.4261168e-01
|
|
||||||
2.7833629e-01 1.1511216e-01]
|
|
||||||
[2.8865540e-01 2.0290835e-01 2.8912998e-01 ... 2.5027491e-01
|
|
||||||
3.1914055e-01 1.7571822e-01]
|
|
||||||
[1.1940934e-01 9.2323301e-02 1.1436666e-01 ... 2.1398625e-01
|
|
||||||
1.7445299e-01 1.4882592e-01]
|
|
||||||
...
|
|
||||||
[3.3456387e-01 5.8978695e-01 3.2886463e-01 ... 3.6013746e-01
|
|
||||||
1.3502858e-01 1.8476978e-01]
|
|
||||||
[1.9967817e-01 6.6486304e-01 1.8575081e-01 ... 0.0000000e+00
|
|
||||||
1.9712202e-04 2.6301981e-02]
|
|
||||||
[3.6868759e-02 5.0152181e-01 2.8539838e-02 ... 0.0000000e+00
|
|
||||||
2.5744136e-01 1.0068215e-01]]
|
|
||||||
Размерность данных:
|
|
||||||
(357, 30)
|
|
||||||
```
|
|
||||||

|
|
||||||
**4)Создать и обучить автокодировщик с подходящей для данных архитектурой.** **Выбрать необходимое количество эпох обучения.**
|
|
||||||
```py
|
|
||||||
patience=2000
|
|
||||||
ae3_trained, IRE3, IREth3 = lib.create_fit_save_ae(train,'out/AE3.h5','out/AE3_ire_th.txt', 100000, False, patience, early_stopping_delta = 0.00001, early_stopping_value = 0.0001)
|
|
||||||
```
|
|
||||||
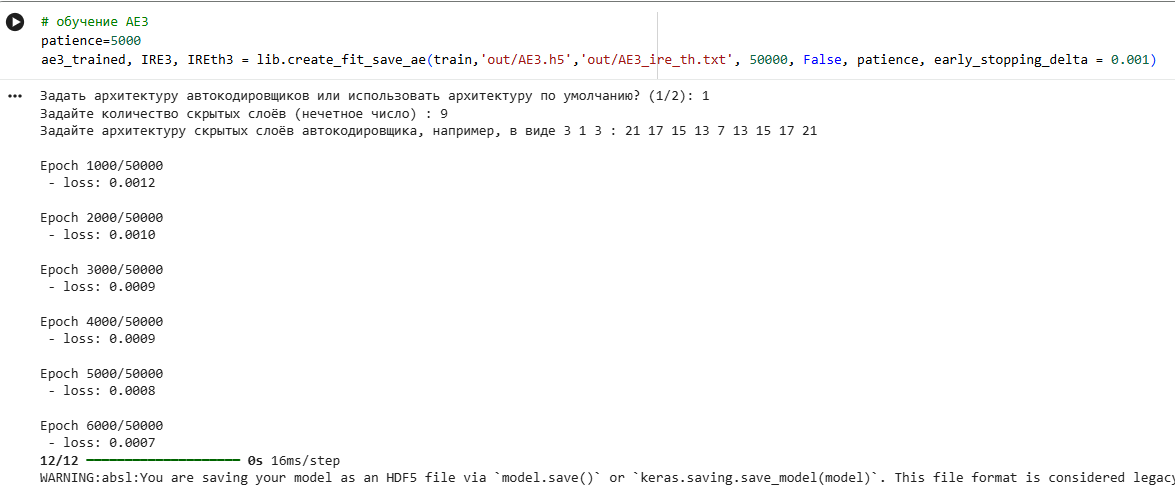
|
|
||||||
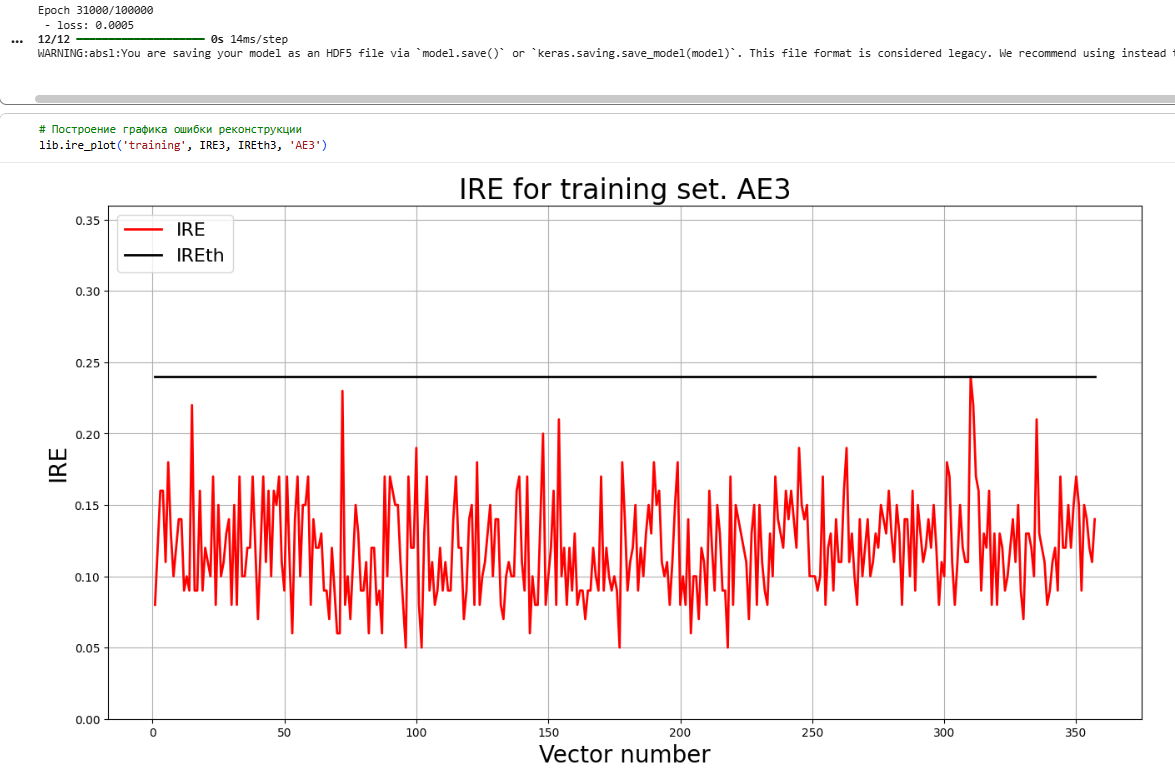
**5)Зафиксировать ошибку MSE, на которой обучение завершилось. Построить график ошибки реконструкции обучающей выборки. Зафиксировать порог ошибки реконструкции –порог обнаружения аномалий.**
|
|
||||||
```py
|
|
||||||
Epoch 31000/100000
|
|
||||||
- loss: 0.0005
|
|
||||||
12/12 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step
|
|
||||||
|
|
||||||
lib.ire_plot('training', IRE3, IREth3, 'AE3')
|
|
||||||
```
|
|
||||||
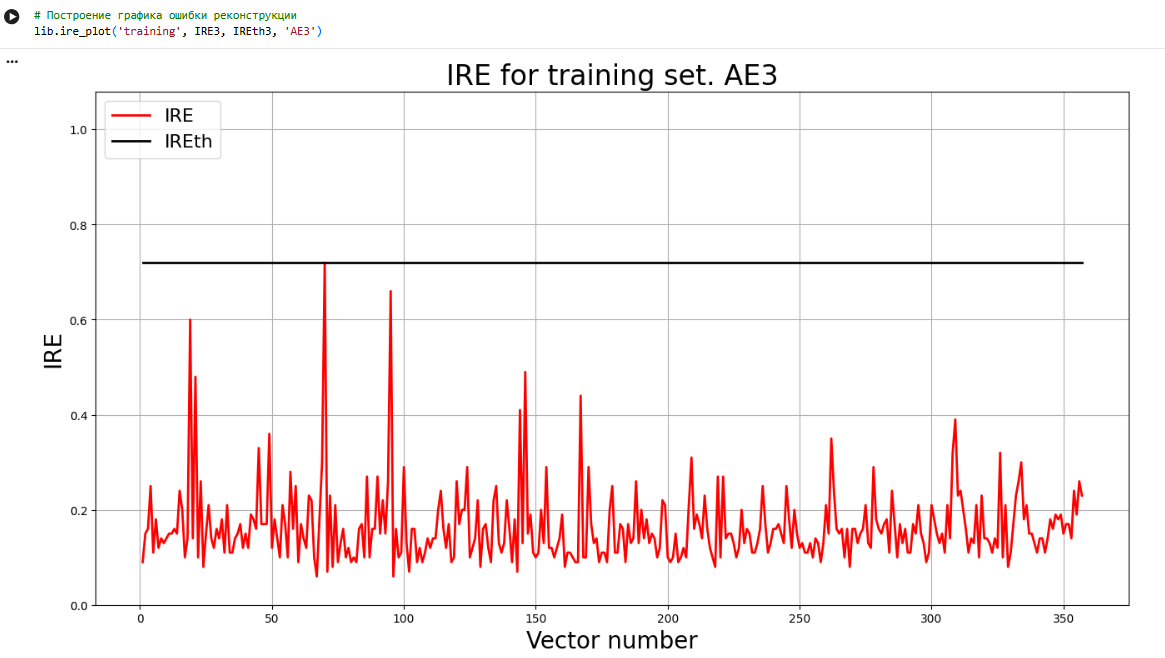
|
|
||||||
**7)Изучить и загрузить тестовую выборку WBC_test.txt.**
|
|
||||||
```py
|
|
||||||
test = np.loadtxt('WBC_test.txt', dtype=float)
|
|
||||||
```
|
|
||||||

|
|
||||||
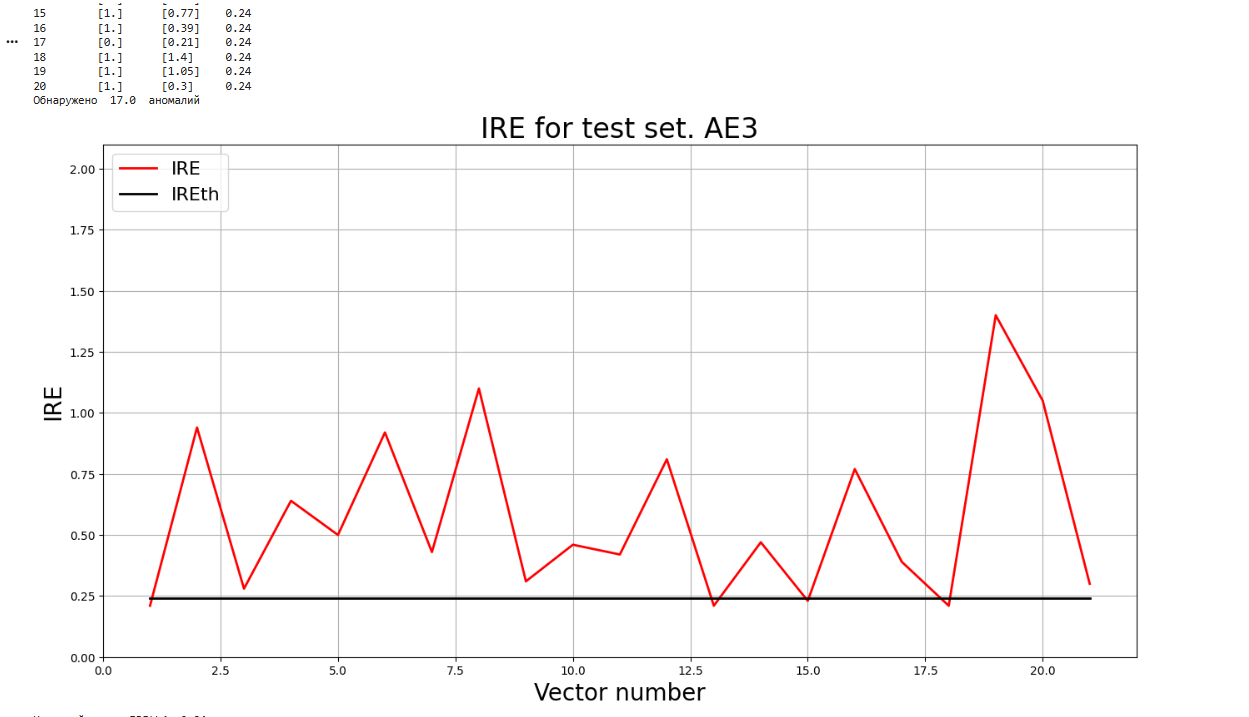
**8)Подать тестовую выборку на вход обученного автокодировщика для обнаружения аномалий. Вывести графикошибки реконструкции элементов тестовой выборки относительно порога.**
|
|
||||||
```py
|
|
||||||
predicted_labels3, ire3 = lib.predict_ae(ae3_trained, test, IREth3)
|
|
||||||
lib.anomaly_detection_ae(predicted_labels3, ire3, IREth3)
|
|
||||||
lib.ire_plot('test', ire3, IREth3, 'AE3')
|
|
||||||
print(f"Исходный порог IREth4: {IREth3}")
|
|
||||||
|
|
||||||
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 40ms/step
|
|
||||||
|
|
||||||
i Labels IRE IREth
|
|
||||||
0 [0.] [0.21] 0.24
|
|
||||||
1 [1.] [0.94] 0.24
|
|
||||||
2 [1.] [0.28] 0.24
|
|
||||||
3 [1.] [0.64] 0.24
|
|
||||||
4 [1.] [0.5] 0.24
|
|
||||||
5 [1.] [0.92] 0.24
|
|
||||||
6 [1.] [0.43] 0.24
|
|
||||||
7 [1.] [1.1] 0.24
|
|
||||||
8 [1.] [0.31] 0.24
|
|
||||||
9 [1.] [0.46] 0.24
|
|
||||||
10 [1.] [0.42] 0.24
|
|
||||||
11 [1.] [0.81] 0.24
|
|
||||||
12 [0.] [0.21] 0.24
|
|
||||||
13 [1.] [0.47] 0.24
|
|
||||||
14 [0.] [0.23] 0.24
|
|
||||||
15 [1.] [0.77] 0.24
|
|
||||||
16 [1.] [0.39] 0.24
|
|
||||||
17 [0.] [0.21] 0.24
|
|
||||||
18 [1.] [1.4] 0.24
|
|
||||||
19 [1.] [1.05] 0.24
|
|
||||||
20 [1.] [0.3] 0.24
|
|
||||||
Обнаружено 17.0 аномалий
|
|
||||||
|
|
||||||
Исходный порог IREth4: 0.24
|
|
||||||
```
|
|
||||||
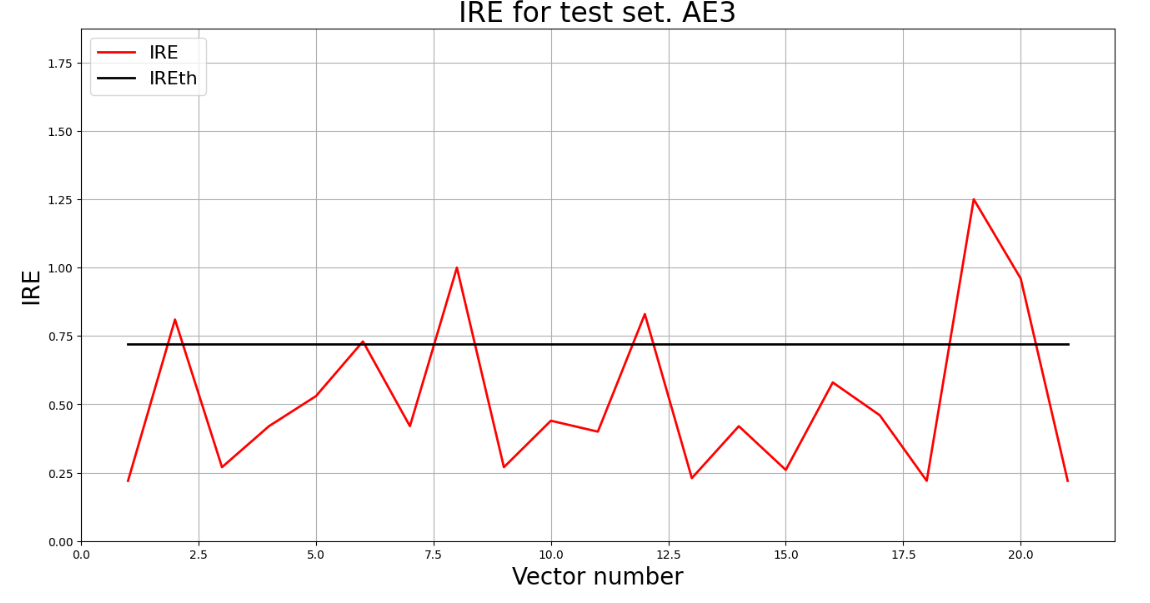
|
|
||||||
**9)Если результаты обнаружения аномалий не удовлетворительные (обнаружено менее 70%аномалий), то подобрать подходящие параметры автокодировщика и повторить шаги (4)–(9)**
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**10)Параметры наилучшего автокодировщика и результаты обнаружения аномалий занести в таблицу:**
|
|
||||||
|
|
||||||
| | | | | | |
|
|
||||||
| --- | --- | --- | --- | --- | --- |
|
|
||||||
| Количество скрытых слоев | Количестов нейронов | Количество эпох обучения | Ошибка MSE_stop | Порог ошибки реконструкции | % обнаруженных аномалий |
|
|
||||||
| 11 | 31 25 21 17 13 7 13 17 21 25 31 | 7000 | 0.0006 | 0.33 | 70 |
|
|
||||||
|
|
||||||
**11)Сделать выводы:**
|
|
||||||
|
|
||||||
•архитектура автокодировщика должна включать в себя много слоев,
|
|
||||||
•количество эпох обучения должно быть достаточно большим (порядка десятков тысяч),
|
|
||||||
•ошибка MSE_stop, приемлемая для останова обучения, должна иметь достаточно малое значение,
|
|
||||||
•порог обнаружения аномалий не должен быть завышен по сравнению с большинством значений ошибки реконструкции обучающей выборки.
|
|
||||||
{kind=link}
|
До Ширина: | Высота: | Размер: 30 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 86 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 59 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 322 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 42 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 74 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 175 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 237 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 83 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 1.1 MiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 106 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 277 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 306 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 58 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 189 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 187 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 275 KiB |
{kind=link}
|
До Ширина: | Высота: | Размер: 281 KiB |
@ -0,0 +1,9 @@
|
|||||||
|
## Лабораторныа работа №3
|
||||||
|
|
||||||
|
## Распознавание изображений
|
||||||
|
|
||||||
|
* [Задание](IS_Lab03_2023.pdf)
|
||||||
|
|
||||||
|
* [Методические указания](IS_Lab03_Metod_2023.pdf)
|
||||||
|
|
||||||
|
* <a href="https://youtube.com/playlist?list=PLZDCDMGmelH-pHt-Ij0nImVrOmj8DYKbB" target="_blank">Плейлист с видео о сверточных сетях</a>
|
||||||
@ -1,380 +0,0 @@
|
|||||||
**ЛАБОРАТОРНАЯ РАБОТА №3**«Распознавание изображений»**
|
|
||||||
А-02-22 бригада №8 Левшенко Д.И., Новиков Д. М., Шестов Д.Н
|
|
||||||
|
|
||||||
Задание1:
|
|
||||||
|
|
||||||
**1)В среде GoogleColab создать новый блокнот(notebook). Импортировать необходимые для работы библиотеки и модули.**
|
|
||||||
```py
|
|
||||||
from google.colab import drive
|
|
||||||
drive.mount('/content/drive')
|
|
||||||
import os
|
|
||||||
os.chdir('/content/drive/MyDrive/Colab Notebooks/IS_LR3')
|
|
||||||
|
|
||||||
from tensorflow import keras
|
|
||||||
from tensorflow.keras import layers
|
|
||||||
from tensorflow.keras.models import Sequential
|
|
||||||
import matplotlib.pyplot as plt
|
|
||||||
import numpy as np
|
|
||||||
from sklearn.metrics import classification_report, confusion_matrix
|
|
||||||
from sklearn.metrics import ConfusionMatrixDisplay
|
|
||||||
```
|
|
||||||
**2)Загрузить набор данных MNIST, содержащий размеченные изображения рукописных цифр.**
|
|
||||||
```py
|
|
||||||
from keras.datasets import mnist
|
|
||||||
(X_train, y_train), (X_test, y_test) = mnist.load_data()
|
|
||||||
```
|
|
||||||

|
|
||||||
|
|
||||||
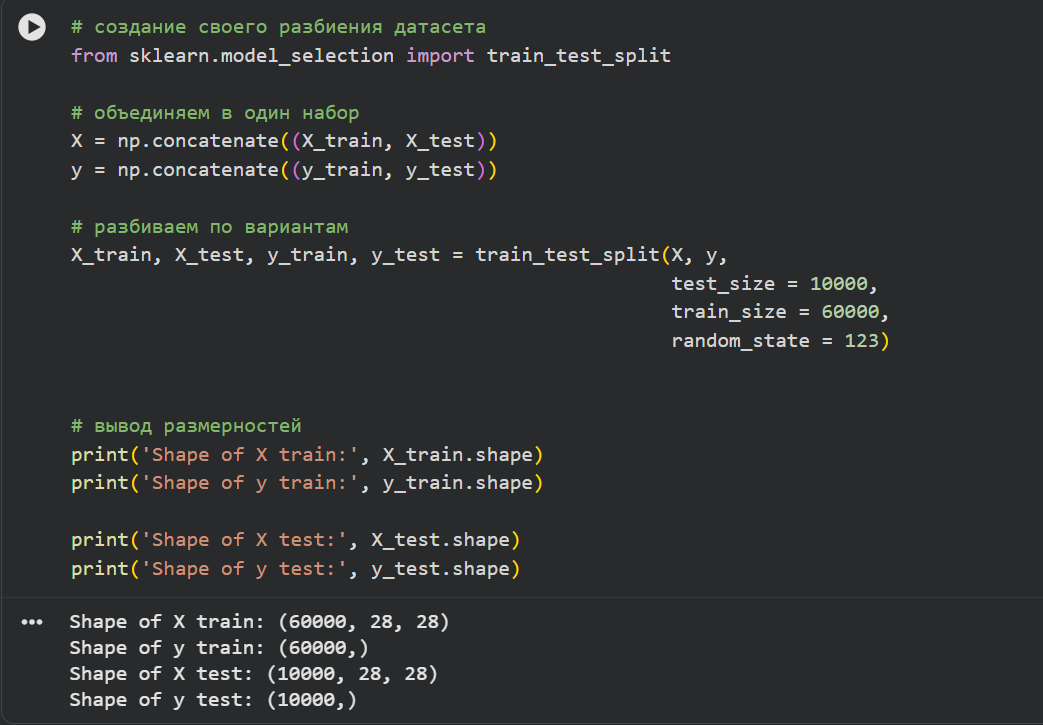
**3)Разбить набор данных на обучающие и тестовые данные в соотношении 60000:10000 элементов. При разбиении параметр random_state выбрать равным (4k–1), где k–номер бригады. Вывести размерности полученных обучающих и тестовых массивов данных.**
|
|
||||||
```py
|
|
||||||
from sklearn.model_selection import train_test_split
|
|
||||||
|
|
||||||
# объединяем в один набор
|
|
||||||
X = np.concatenate((X_train, X_test))
|
|
||||||
y = np.concatenate((y_train, y_test))
|
|
||||||
|
|
||||||
# разбиваем по вариантам
|
|
||||||
X_train, X_test, y_train, y_test = train_test_split(X, y,
|
|
||||||
test_size = 10000,
|
|
||||||
train_size = 60000,
|
|
||||||
random_state = 123)
|
|
||||||
|
|
||||||
|
|
||||||
# вывод размерностей
|
|
||||||
print('Shape of X train:', X_train.shape)
|
|
||||||
print('Shape of y train:', y_train.shape)
|
|
||||||
|
|
||||||
print('Shape of X test:', X_test.shape)
|
|
||||||
print('Shape of y test:', y_test.shape)
|
|
||||||
```
|
|
||||||
|
|
||||||
**4)Провести предобработку данных: привести обучающие и тестовые данные к формату, пригодному для обучения сверточной нейронной сети. Входные данные должны принимать значения от 0 до 1, метки цифр должны быть закодированы по принципу «one-hotencoding». Вывести размерности предобработанных обучающих и тестовых массивов данных.**
|
|
||||||
```py
|
|
||||||
# Зададим параметры данных и модели
|
|
||||||
num_classes = 10
|
|
||||||
input_shape = (28, 28, 1)
|
|
||||||
|
|
||||||
# Приведение входных данных к диапазону [0, 1]
|
|
||||||
X_train = X_train / 255
|
|
||||||
X_test = X_test / 255
|
|
||||||
|
|
||||||
# Расширяем размерность входных данных, чтобы каждое изображение имело
|
|
||||||
# размерность (высота, ширина, количество каналов)
|
|
||||||
X_train = np.expand_dims(X_train, -1)
|
|
||||||
X_test = np.expand_dims(X_test, -1)
|
|
||||||
print('Shape of transformed X train:', X_train.shape)
|
|
||||||
print('Shape of transformed X test:', X_test.shape)
|
|
||||||
|
|
||||||
# переведем метки в one-hot
|
|
||||||
y_train = keras.utils.to_categorical(y_train, num_classes)
|
|
||||||
y_test = keras.utils.to_categorical(y_test, num_classes)
|
|
||||||
print('Shape of transformed y train:', y_train.shape)
|
|
||||||
print('Shape of transformed y test:', y_test.shape)
|
|
||||||
```
|
|
||||||

|
|
||||||
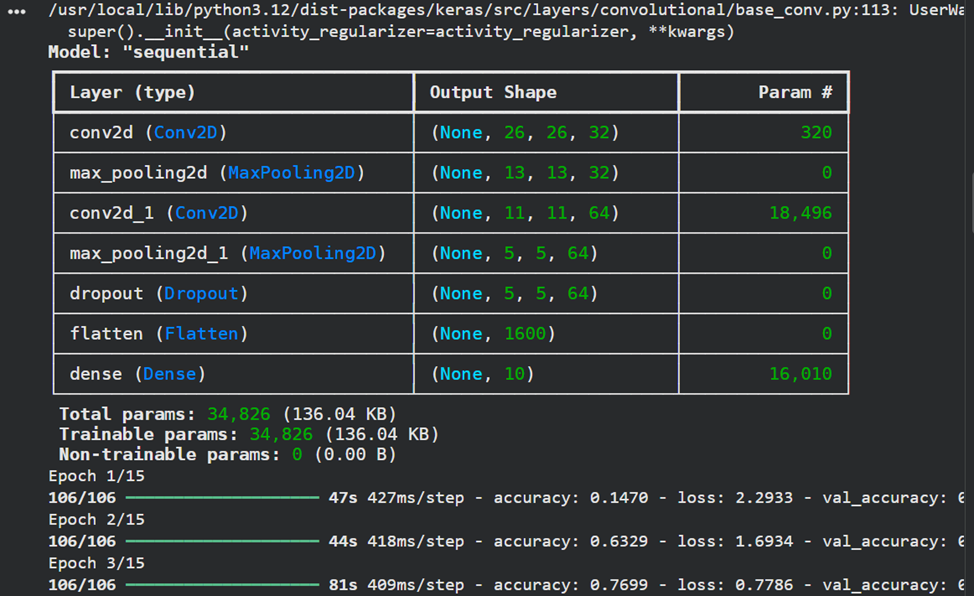
**5)Реализовать модель сверточной нейронной сети и обучить ее на обучающих данных с выделением части обучающих данных в качестве валидационных. Вывести информацию об архитектуре нейронной сети.**
|
|
||||||
```py
|
|
||||||
# создаем модель
|
|
||||||
model = Sequential()
|
|
||||||
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape))
|
|
||||||
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
|
||||||
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
|
|
||||||
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
|
||||||
model.add(layers.Dropout(0.5))
|
|
||||||
model.add(layers.Flatten())
|
|
||||||
model.add(layers.Dense(num_classes, activation="softmax"))
|
|
||||||
|
|
||||||
model.summary()
|
|
||||||
# компилируем и обучаем модель
|
|
||||||
batch_size = 512
|
|
||||||
epochs = 15
|
|
||||||
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
|
|
||||||
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
**6)Оценить качество обучения на тестовых данных. Вывести значение функции ошибки и значение метрики качества классификации на тестовых данных.**
|
|
||||||
```py
|
|
||||||
# Оценка качества работы модели на тестовых данных
|
|
||||||
scores = model.evaluate(X_test, y_test)
|
|
||||||
print('Loss on test data:', scores[0])
|
|
||||||
print('Accuracy on test data:', scores[1])
|
|
||||||
```
|
|
||||||
**7)Подать на вход обученной модели два тестовых изображения. Вывести изображения, истинные метки и результаты распознавания.**
|
|
||||||
```py
|
|
||||||
# вывод тестового изображения и результата распознавания
|
|
||||||
n = 123
|
|
||||||
result = model.predict(X_test[n:n+1])
|
|
||||||
print('NN output:', result)
|
|
||||||
plt.show()
|
|
||||||
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
|
|
||||||
print('Real mark: ', np.argmax(y_test[n]))
|
|
||||||
print('NN answer: ', np.argmax(result))
|
|
||||||
```
|
|
||||||

|
|
||||||
|
|
||||||
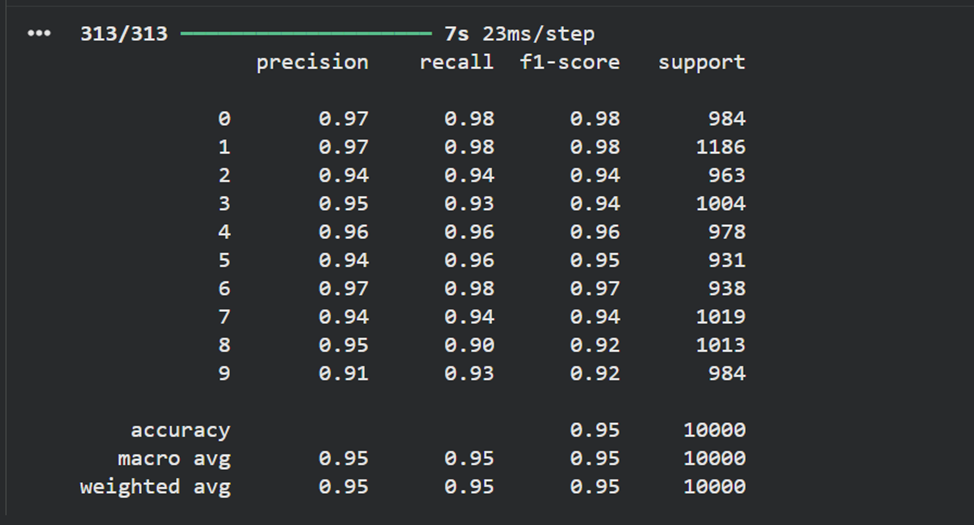
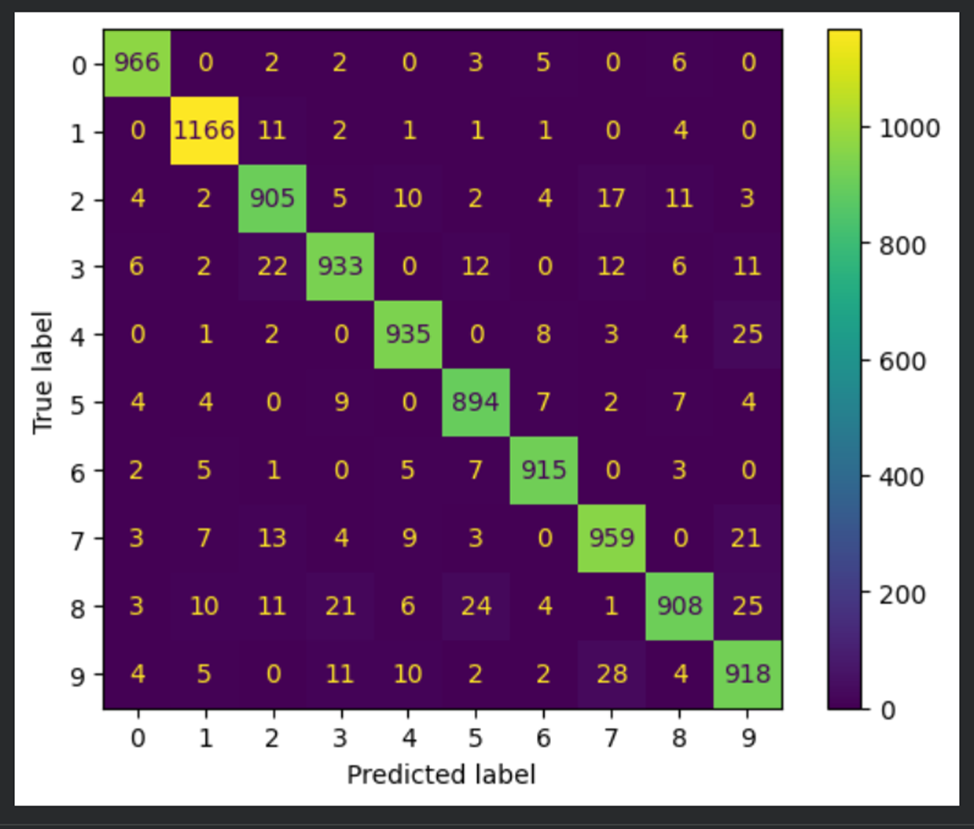
**8)Вывести отчет о качестве классификации тестовой выборки и матрицу ошибок для тестовой выборки.**
|
|
||||||
```py
|
|
||||||
# истинные метки классов
|
|
||||||
true_labels = np.argmax(y_test, axis=1)
|
|
||||||
# предсказанные метки классов
|
|
||||||
predicted_labels = np.argmax(model.predict(X_test), axis=1)
|
|
||||||
|
|
||||||
# отчет о качестве классификации
|
|
||||||
print(classification_report(true_labels, predicted_labels))
|
|
||||||
# вычисление матрицы ошибок
|
|
||||||
conf_matrix = confusion_matrix(true_labels, predicted_labels)
|
|
||||||
# отрисовка матрицы ошибок в виде "тепловой карты"
|
|
||||||
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix)
|
|
||||||
display.plot()
|
|
||||||
plt.show()
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
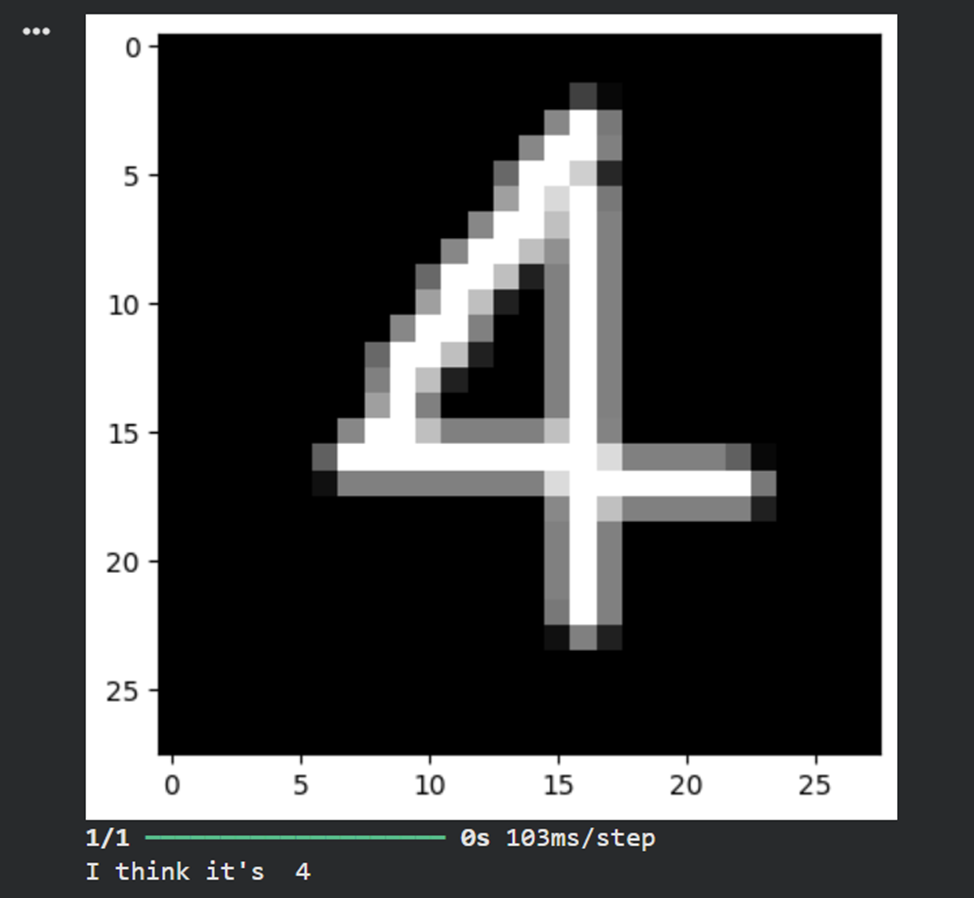
**9)Загрузить, предобработать и подать на вход обученной нейронной сети собственное изображение, созданное при выполнении лабораторной работы No1. Вывести изображение и результат распознавания.**
|
|
||||||
```py
|
|
||||||
# загрузка собственного изображения
|
|
||||||
from PIL import Image
|
|
||||||
file_data = Image.open('test.png')
|
|
||||||
file_data = file_data.convert('L') # перевод в градации серого
|
|
||||||
test_img = np.array(file_data)
|
|
||||||
|
|
||||||
# вывод собственного изображения
|
|
||||||
plt.imshow(test_img, cmap=plt.get_cmap('gray'))
|
|
||||||
plt.show()
|
|
||||||
|
|
||||||
# предобработка
|
|
||||||
test_img = test_img / 255
|
|
||||||
test_img = np.reshape(test_img, (1,28,28,1))
|
|
||||||
|
|
||||||
# распознавание
|
|
||||||
result = model.predict(test_img)
|
|
||||||
print('I think it\'s ', np.argmax(result))
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
**10)Сравнить обученную модель сверточной сети и наилучшую модель полносвязной сети из лабораторной работы No1**
|
|
||||||
· Количество параметров в CNN значительно меньше, чем в полносвязной сети, благодаря использованию сверток.
|
|
||||||
· CNN потребовала меньше эпох для достижения высокой точности.
|
|
||||||
· Качество классификации на тестовой выборке у CNN выше (99% против ~98% у полносвязной сети).
|
|
||||||
|
|
||||||
Итоговый вывод:
|
|
||||||
Сверточные нейронные сети показали высокую эффективность для задачи распознавания изображений благодаря способности выделять пространственные признаки, устойчивости к сдвигам и искажениям, а также меньшему количеству обучаемых параметров по сравнению с полносвязными сетями.
|
|
||||||
|
|
||||||
|
|
||||||
**Задание2**
|
|
||||||
|
|
||||||
**В новом блокноте выполнить п. 1–8 задания 1, изменив набор данных MNIST на CIFAR-10, содержащий размеченные цветные изображения объектов, разделенные на 10 классов. **
|
|
||||||
```py
|
|
||||||
# Пункт 1-2: Импорт библиотек и загрузка данных
|
|
||||||
from keras.datasets import cifar10
|
|
||||||
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
|
|
||||||
```
|
|
||||||
**При этом:
|
|
||||||
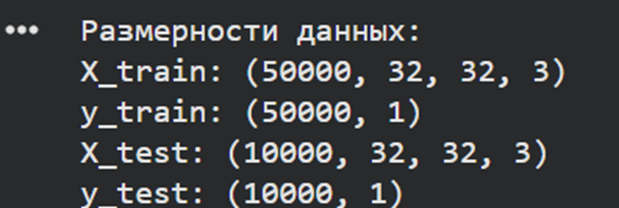
· в п.3 разбиение данных на обучающие и тестовые произвести в соотношении 50 000:10 000.**
|
|
||||||
```py
|
|
||||||
# Пункт 3: Разбиение данных
|
|
||||||
print("Размерности данных:")
|
|
||||||
print(f"X_train: {X_train.shape}")
|
|
||||||
print(f"y_train: {y_train.shape}")
|
|
||||||
print(f"X_test: {X_test.shape}")
|
|
||||||
print(f"y_test: {y_test.shape}")
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
```py
|
|
||||||
# Визуализация 25 изображений
|
|
||||||
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
|
|
||||||
'dog', 'frog', 'horse', 'ship', 'truck']
|
|
||||||
|
|
||||||
plt.figure(figsize=(10,10))
|
|
||||||
for i in range(25):
|
|
||||||
plt.subplot(5,5,i+1)
|
|
||||||
plt.xticks([])
|
|
||||||
plt.yticks([])
|
|
||||||
plt.grid(False)
|
|
||||||
plt.imshow(X_train[i])
|
|
||||||
plt.xlabel(class_names[y_train[i][0]])
|
|
||||||
plt.show()
|
|
||||||
```
|
|
||||||

|
|
||||||
|
|
||||||
**·после разбиения данных (между п. 3 и 4) вывести 25 изображений из обучающей выборки с подписями классов**
|
|
||||||
```py
|
|
||||||
# Пункт 4: Предобработка данных
|
|
||||||
num_classes = 10
|
|
||||||
input_shape = (32, 32, 3)
|
|
||||||
|
|
||||||
# Нормализация
|
|
||||||
X_train = X_train.astype('float32') / 255
|
|
||||||
X_test = X_test.astype('float32') / 255
|
|
||||||
|
|
||||||
# One-hot encoding
|
|
||||||
y_train_categorical = keras.utils.to_categorical(y_train, num_classes)
|
|
||||||
y_test_categorical = keras.utils.to_categorical(y_test, num_classes)
|
|
||||||
```
|
|
||||||
|
|
||||||
```py
|
|
||||||
# Пункт 5: Создание и обучение модели
|
|
||||||
model = Sequential()
|
|
||||||
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape))
|
|
||||||
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu"))
|
|
||||||
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
|
||||||
model.add(layers.Dropout(0.25))
|
|
||||||
|
|
||||||
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
|
|
||||||
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
|
|
||||||
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
|
||||||
model.add(layers.Dropout(0.25))
|
|
||||||
|
|
||||||
model.add(layers.Conv2D(128, kernel_size=(3, 3), activation="relu"))
|
|
||||||
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
|
|
||||||
model.add(layers.Dropout(0.25))
|
|
||||||
|
|
||||||
model.add(layers.Flatten())
|
|
||||||
model.add(layers.Dense(512, activation='relu'))
|
|
||||||
model.add(layers.Dropout(0.5))
|
|
||||||
model.add(layers.Dense(256, activation='relu'))
|
|
||||||
model.add(layers.Dropout(0.5))
|
|
||||||
model.add(layers.Dense(num_classes, activation="softmax"))
|
|
||||||
|
|
||||||
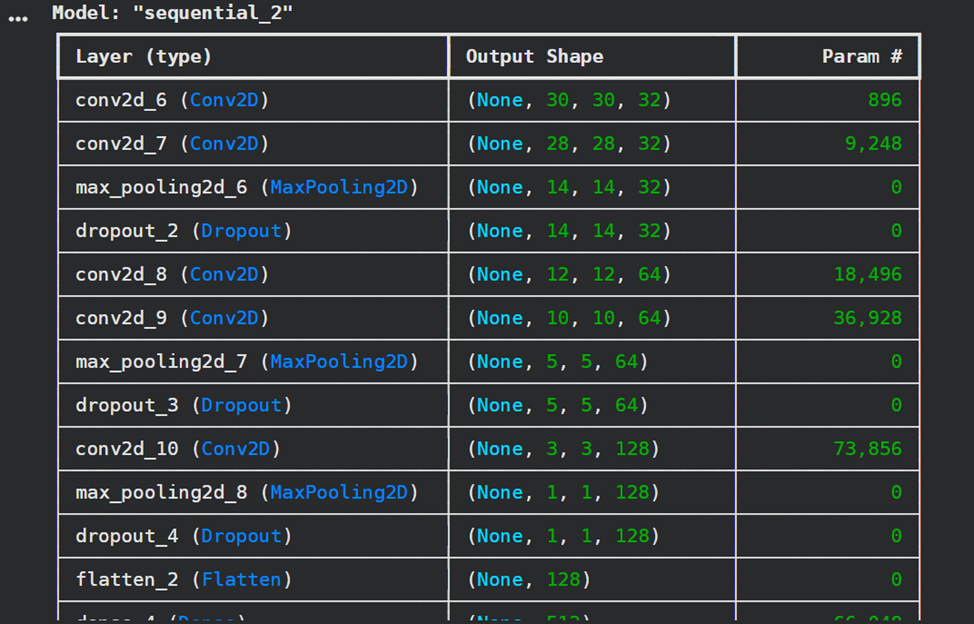
model.summary()
|
|
||||||
|
|
||||||
# Компиляция и обучение модели с более медленным learning rate
|
|
||||||
model.compile(loss="categorical_crossentropy",
|
|
||||||
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
|
|
||||||
metrics=["accuracy"])
|
|
||||||
|
|
||||||
batch_size = 64
|
|
||||||
epochs = 40
|
|
||||||
|
|
||||||
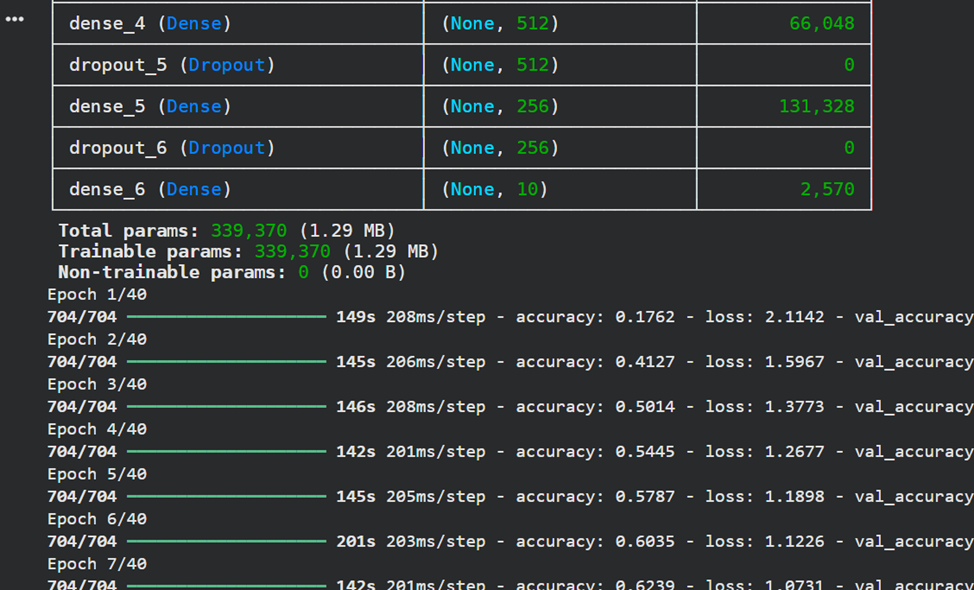
history = model.fit(X_train, y_train_categorical,
|
|
||||||
batch_size=batch_size,
|
|
||||||
epochs=epochs,
|
|
||||||
validation_split=0.1,
|
|
||||||
verbose=1)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
```py
|
|
||||||
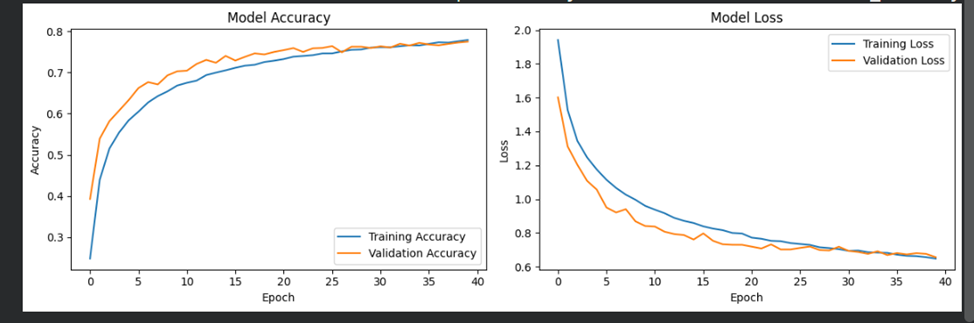
# Визуализация процесса обучения
|
|
||||||
plt.figure(figsize=(12, 4))
|
|
||||||
plt.subplot(1, 2, 1)
|
|
||||||
plt.plot(history.history['accuracy'], label='Training Accuracy')
|
|
||||||
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
|
|
||||||
plt.title('Model Accuracy')
|
|
||||||
plt.xlabel('Epoch')
|
|
||||||
plt.ylabel('Accuracy')
|
|
||||||
plt.legend()
|
|
||||||
|
|
||||||
plt.subplot(1, 2, 2)
|
|
||||||
plt.plot(history.history['loss'], label='Training Loss')
|
|
||||||
plt.plot(history.history['val_loss'], label='Validation Loss')
|
|
||||||
plt.title('Model Loss')
|
|
||||||
plt.xlabel('Epoch')
|
|
||||||
plt.ylabel('Loss')
|
|
||||||
plt.legend()
|
|
||||||
plt.tight_layout()
|
|
||||||
plt.show()
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
```py
|
|
||||||
# Пункт 6: Оценка качества
|
|
||||||
test_loss, test_accuracy = model.evaluate(X_test, y_test_categorical, verbose=0)
|
|
||||||
print(f"Test loss: {test_loss:.4f}")
|
|
||||||
print(f"Test accuracy: {test_accuracy:.4f}")
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
**· в п. 7 одно из тестовых изображений должно распознаваться корректно, а другое – ошибочно**
|
|
||||||
```py
|
|
||||||
# Пункт 7: Распознавание двух тестовых изображений
|
|
||||||
print("РАСПОЗНАВАНИЕ ТЕСТОВЫХ ИЗОБРАЖЕНИЙ:")
|
|
||||||
|
|
||||||
# Функция для распознавания одного изображения из тестовой выборки
|
|
||||||
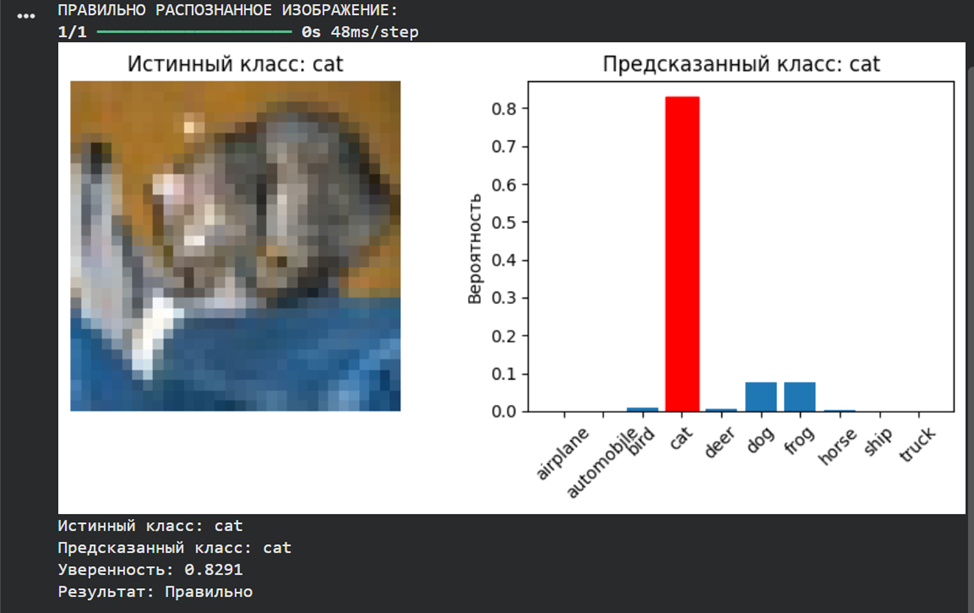
def predict_single_image(model, X, y, index, class_names):
|
|
||||||
prediction = model.predict(X[index:index+1])
|
|
||||||
predicted_class = np.argmax(prediction[0])
|
|
||||||
true_class = y[index][0]
|
|
||||||
|
|
||||||
plt.figure(figsize=(8, 4))
|
|
||||||
|
|
||||||
plt.subplot(1, 2, 1)
|
|
||||||
plt.imshow(X[index])
|
|
||||||
plt.title(f'Истинный класс: {class_names[true_class]}')
|
|
||||||
plt.axis('off')
|
|
||||||
|
|
||||||
plt.subplot(1, 2, 2)
|
|
||||||
bars = plt.bar(range(10), prediction[0])
|
|
||||||
# Подсветим предсказанный класс
|
|
||||||
bars[predicted_class].set_color('red')
|
|
||||||
plt.xticks(range(10), class_names, rotation=45)
|
|
||||||
plt.title(f'Предсказанный класс: {class_names[predicted_class]}')
|
|
||||||
plt.ylabel('Вероятность')
|
|
||||||
plt.tight_layout()
|
|
||||||
plt.show()
|
|
||||||
|
|
||||||
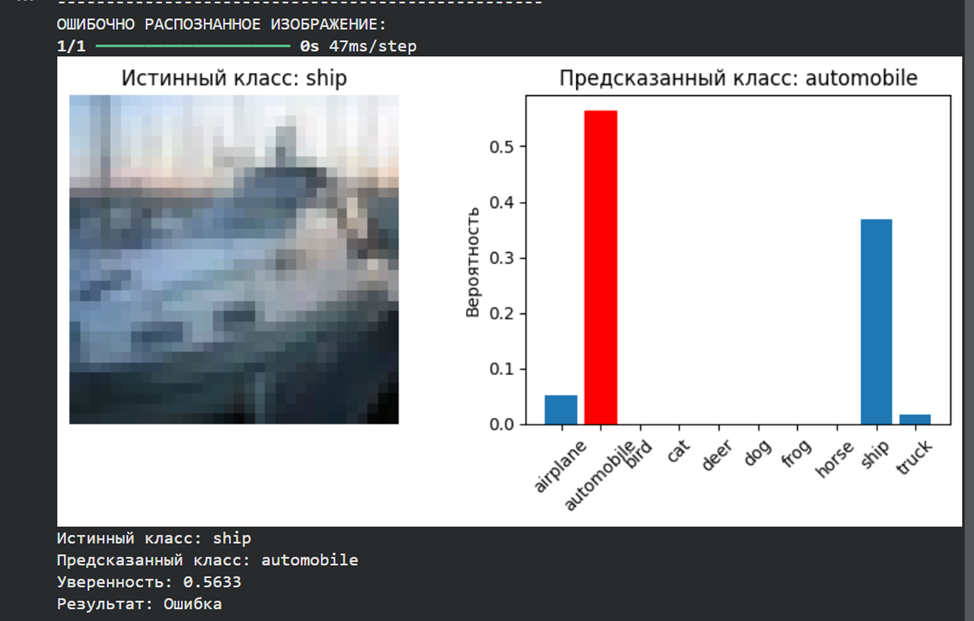
print(f"Истинный класс: {class_names[true_class]}")
|
|
||||||
print(f"Предсказанный класс: {class_names[predicted_class]}")
|
|
||||||
print(f"Уверенность: {np.max(prediction[0]):.4f}")
|
|
||||||
print(f"Результат: {'Правильно' if predicted_class == true_class else 'Ошибка'}")
|
|
||||||
print("-" * 50)
|
|
||||||
|
|
||||||
return predicted_class == true_class
|
|
||||||
|
|
||||||
# Найдем одно правильное и одно неправильное предсказание
|
|
||||||
print("Поиск правильного и неправильного предсказания...")
|
|
||||||
all_predictions = model.predict(X_test)
|
|
||||||
all_predicted_classes = np.argmax(all_predictions, axis=1)
|
|
||||||
true_classes = y_test.flatten()
|
|
||||||
|
|
||||||
correct_indices = []
|
|
||||||
wrong_indices = []
|
|
||||||
|
|
||||||
for i in range(len(true_classes)):
|
|
||||||
if all_predicted_classes[i] == true_classes[i]:
|
|
||||||
correct_indices.append(i)
|
|
||||||
else:
|
|
||||||
wrong_indices.append(i)
|
|
||||||
|
|
||||||
if len(correct_indices) > 0 and len(wrong_indices) > 0:
|
|
||||||
break
|
|
||||||
|
|
||||||
if correct_indices:
|
|
||||||
print("ПРАВИЛЬНО РАСПОЗНАННОЕ ИЗОБРАЖЕНИЕ:")
|
|
||||||
predict_single_image(model, X_test, y_test, correct_indices[0], class_names)
|
|
||||||
|
|
||||||
if wrong_indices:
|
|
||||||
print("ОШИБОЧНО РАСПОЗНАННОЕ ИЗОБРАЖЕНИЕ:")
|
|
||||||
predict_single_image(model, X_test, y_test, wrong_indices[0], class_names)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
```py
|
|
||||||
# Пункт 8: Отчет о качестве классификации и матрица ошибок
|
|
||||||
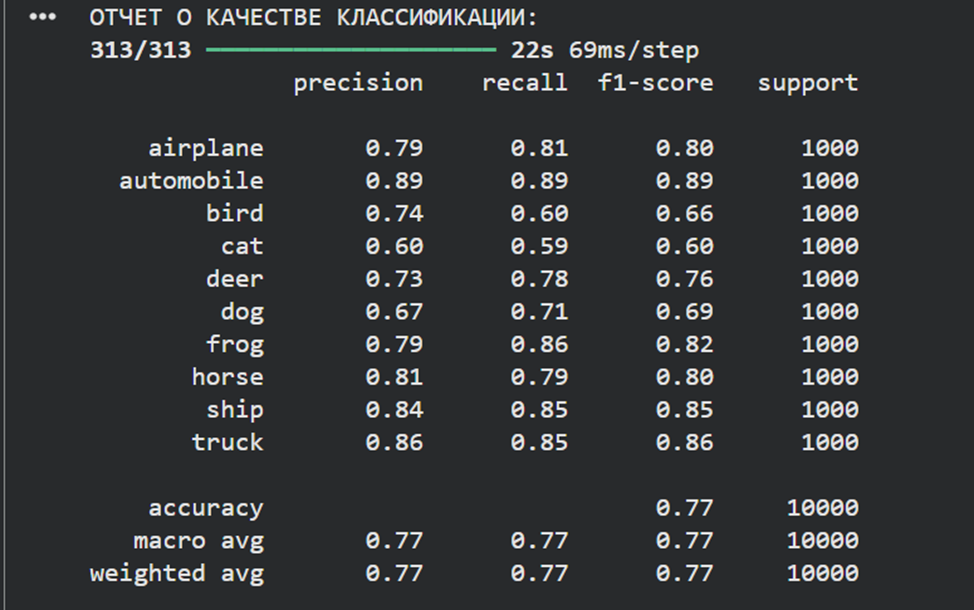
print("ОТЧЕТ О КАЧЕСТВЕ КЛАССИФИКАЦИИ:")
|
|
||||||
true_labels = np.argmax(y_test_categorical, axis=1)
|
|
||||||
predicted_labels = np.argmax(model.predict(X_test), axis=1)
|
|
||||||
|
|
||||||
print(classification_report(true_labels, predicted_labels, target_names=class_names))
|
|
||||||
|
|
||||||
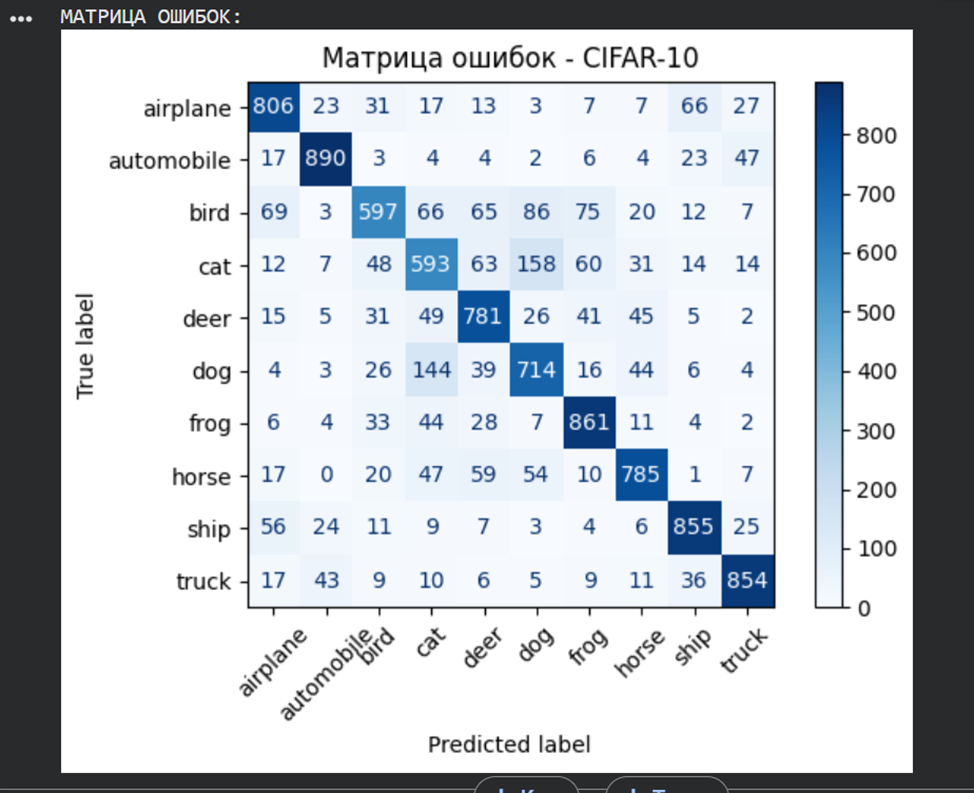
print("МАТРИЦА ОШИБОК:")
|
|
||||||
conf_matrix = confusion_matrix(true_labels, predicted_labels)
|
|
||||||
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix, display_labels=class_names)
|
|
||||||
display.plot(cmap=plt.cm.Blues, xticks_rotation=45)
|
|
||||||
plt.title('Матрица ошибок - CIFAR-10')
|
|
||||||
plt.tight_layout()
|
|
||||||
plt.show()
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Итоговый вывод:
|
|
||||||
CNN способна решать задачи классификации цветных изображений, однако её точность снижается при увеличении сложности данных. Для улучшения результатов требуются более глубокие архитектуры, аугментация данных и тонкая настройка гиперпараметров.
|
|
||||||
|
|
||||||
**Общий вывод по лр 3:
|
|
||||||
Сверточные нейронные сети являются мощным инструментом для задач компьютерного зрения. CNN эффективно обрабатывают пространственные иерархии признаков, что делает их предпочтительными для работы с изображениями по сравнению с полносвязными сетями. Качество классификации зависит от сложности данных, архитектуры сети и корректности предобработки. Использование методов регуляризации (Dropout) и аугментации данных может улучшить обобщающую способность модели. Интерпретация матрицы ошибок и метрик качества позволяет анализировать слабые места модели и направлять её доработку.**
|
|
||||||
@ -0,0 +1,7 @@
|
|||||||
|
## Лабораторныа работа №4
|
||||||
|
|
||||||
|
## Распознавание последовательностей
|
||||||
|
|
||||||
|
* [Задание](IS_Lab04_2023.pdf)
|
||||||
|
|
||||||
|
* [Методические указания](IS_Lab04_Metod_2023.pdf)
|
||||||
@ -1,159 +0,0 @@
|
|||||||
{
|
|
||||||
"cells": [
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import tensorflow as tf\n",
|
|
||||||
"#device_name=tf.test.gpu_device_name()\n",
|
|
||||||
"#if device_name != '/device:GPU:0':\n",
|
|
||||||
" #raise SystemError('GPUdevicenotfound')\n",
|
|
||||||
"#print('FoundGPUat:{}'.format(device_name))\n",
|
|
||||||
"#загрузкадатасета\n",
|
|
||||||
"from keras.datasets import imdb\n",
|
|
||||||
"vocabulary_size=5000\n",
|
|
||||||
"index_from=3\n",
|
|
||||||
"(X_train,y_train),(X_test,y_test)=imdb.load_data(path=\"imdb.npz\",\n",
|
|
||||||
" num_words=vocabulary_size,\n",
|
|
||||||
" skip_top=0,\n",
|
|
||||||
" maxlen=None,\n",
|
|
||||||
" seed=4*8 - 1,\n",
|
|
||||||
" start_char=1,\n",
|
|
||||||
" oov_char=2,\n",
|
|
||||||
" index_from=index_from)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"print(X_train.shape)\n",
|
|
||||||
"print(y_train.shape)\n",
|
|
||||||
"print(X_test.shape)\n",
|
|
||||||
"print(y_test.shape)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"word_to_id=imdb.get_word_index()\n",
|
|
||||||
"#уточнениесловаря\n",
|
|
||||||
"word_to_id={key:(value + index_from) for key,value in word_to_id.items()}\n",
|
|
||||||
"word_to_id[\"<PAD>\"]=0\n",
|
|
||||||
"word_to_id[\"<START>\"]=1\n",
|
|
||||||
"word_to_id[\"<UNK>\"]=2\n",
|
|
||||||
"word_to_id[\"<UNUSED>\"]=3\n",
|
|
||||||
"#созданиеобратногословаря\"индекс:слово\"\n",
|
|
||||||
"id_to_word={value:key for key,value in word_to_id.items()}\n",
|
|
||||||
"some_number=4*8-1\n",
|
|
||||||
"review_as_text=''.join(id_to_word[id] for id in X_train[some_number])\n",
|
|
||||||
"print(X_train[some_number])\n",
|
|
||||||
"print(review_as_text)\n",
|
|
||||||
"print(len(X_train[some_number]))\n",
|
|
||||||
"if y_train[some_number] == 1:\n",
|
|
||||||
" class_label='Positive'\n",
|
|
||||||
"else:\n",
|
|
||||||
" class_label='Negative'\n",
|
|
||||||
"print('Review class:', y_train[some_number], f'({class_label})')\n",
|
|
||||||
"print(len(max(X_train, key=len)))\n",
|
|
||||||
"print(len(min(X_train, key=len)))"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"from keras.preprocessing import sequence\n",
|
|
||||||
"max_words=500\n",
|
|
||||||
"X_train=sequence.pad_sequences(X_train, maxlen=max_words, value=0, padding='pre', truncating='post')\n",
|
|
||||||
"X_test=sequence.pad_sequences(X_test, maxlen=max_words, value=0, padding='pre', truncating='post')"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from keras.preprocessing import sequence\n",
|
|
||||||
"max_words=500\n",
|
|
||||||
"X_train=sequence.pad_sequences(X_train, maxlen=max_words, value=0, padding='pre', truncating='post')\n",
|
|
||||||
"X_test=sequence.pad_sequences(X_test, maxlen=max_words, value=0, padding='pre', truncating='post')"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"word_to_id=imdb.get_word_index()\n",
|
|
||||||
"#уточнениесловаря\n",
|
|
||||||
"word_to_id={key:(value + index_from) for key,value in word_to_id.items()}\n",
|
|
||||||
"word_to_id[\"<PAD>\"]=0\n",
|
|
||||||
"word_to_id[\"<START>\"]=1\n",
|
|
||||||
"word_to_id[\"<UNK>\"]=2\n",
|
|
||||||
"word_to_id[\"<UNUSED>\"]=3\n",
|
|
||||||
"#созданиеобратногословаря\"индекс:слово\"\n",
|
|
||||||
"id_to_word={value:key for key,value in word_to_id.items()}\n",
|
|
||||||
"some_number=4*8-1\n",
|
|
||||||
"review_as_text=''.join(id_to_word[id] for id in X_train[some_number])\n",
|
|
||||||
"print(X_train[some_number])\n",
|
|
||||||
"print(review_as_text)\n",
|
|
||||||
"print(len(X_train[some_number]))\n",
|
|
||||||
"if y_train[some_number] == 1:\n",
|
|
||||||
" class_label='Positive'\n",
|
|
||||||
"else:\n",
|
|
||||||
" class_label='Negative'\n",
|
|
||||||
"print('Review class:', y_train[some_number], f'({class_label})')\n",
|
|
||||||
"print(len(max(X_train, key=len)))\n",
|
|
||||||
"print(len(min(X_train, key=len)))\n",
|
|
||||||
"\n",
|
|
||||||
"print(\"x_train: \", X_train)\n",
|
|
||||||
"print(X_train.shape)\n",
|
|
||||||
"print(\"x_test: \", X_test)\n",
|
|
||||||
"print(X_test.shape)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from keras.models import Sequential\n",
|
|
||||||
"from keras.layers import Embedding, LSTM, Dropout, Dense\n",
|
|
||||||
"\n",
|
|
||||||
"model=Sequential()\n",
|
|
||||||
"model.add(Embedding(input_dim=len(word_to_id), output_dim=32, input_length=500))\n",
|
|
||||||
"model.add(LSTM(units=90))\n",
|
|
||||||
"model.add(Dropout(rate=0.4))\n",
|
|
||||||
"model.add(Dense(units=1, activation='sigmoid'))\n",
|
|
||||||
"model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])\n",
|
|
||||||
"H=model.fit(X_train, y_train, validation_split=0.1, epochs=5, batch_size=32)\n",
|
|
||||||
"print(model.summary())\n",
|
|
||||||
"scores=model.evaluate(X_test, y_test)\n",
|
|
||||||
"print(\"LOss: \", scores[0])\n",
|
|
||||||
"print(\"Accuracy: \", scores[1])\n",
|
|
||||||
"test_result=model.predict(X_test)\n",
|
|
||||||
"predicted_labels=[1 if test_result[i,0]>=0.5 else 0 for i in range(len(test_result))]\n",
|
|
||||||
"from sklearn.metrics import classification_report\n",
|
|
||||||
"print(classification_report(y_test, predicted_labels, labels=[0,1], target_names=[\"Negative\", \"Positive\"]))"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"metadata": {
|
|
||||||
"language_info": {
|
|
||||||
"name": "python"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"nbformat": 4,
|
|
||||||
"nbformat_minor": 2
|
|
||||||
}
|
|
||||||
@ -1,244 +0,0 @@
|
|||||||
**ЛАБОРАТОРНАЯ РАБОТА №4 «Распознавание последовательностей»**
|
|
||||||
А-02-22 бригада №8 Левшенко Д.И., Новиков Д. М., Шестов Д.Н
|
|
||||||
|
|
||||||
**2)Загрузить набор данных IMDb, содержащий оцифрованные отзывы на фильмы, размеченные на два класса: позитивные и негативные. При загрузке набора данных параметр seed выбрать равным (4k – 1), где k – номер бригады. Вывести размеры полученных обучающих и тестовых массивов данных.**
|
|
||||||
```py
|
|
||||||
import tensorflow as tf
|
|
||||||
from keras.datasets import imdb
|
|
||||||
vocabulary_size=5000
|
|
||||||
index_from=3
|
|
||||||
(X_train,y_train),(X_test,y_test)=imdb.load_data(path="imdb.npz",
|
|
||||||
num_words=vocabulary_size,
|
|
||||||
skip_top=0,
|
|
||||||
maxlen=None,
|
|
||||||
seed=4*8 - 1,
|
|
||||||
start_char=1,
|
|
||||||
oov_char=2,
|
|
||||||
index_from=index_from)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
```py
|
|
||||||
print(X_train.shape)
|
|
||||||
print(y_train.shape)
|
|
||||||
print(X_test.shape)
|
|
||||||
print(y_test.shape)
|
|
||||||
|
|
||||||
(25000,)
|
|
||||||
(25000,)
|
|
||||||
(25000,)
|
|
||||||
(25000,)
|
|
||||||
```
|
|
||||||
|
|
||||||
**3)Вывести один отзыв из обучающего множества в виде списка индексов слов. Преобразовать список индексов в текст и вывести отзыв в виде текста. Вывести длину отзыва. Вывести метку класса данного отзыва и название класса (1 – Positive, 0 – Negative).**
|
|
||||||
```py
|
|
||||||
word_to_id=imdb.get_word_index()
|
|
||||||
word_to_id={key:(value + index_from) for key,value in word_to_id.items()}
|
|
||||||
word_to_id["<PAD>"]=0
|
|
||||||
word_to_id["<START>"]=1
|
|
||||||
word_to_id["<UNK>"]=2
|
|
||||||
word_to_id["<UNUSED>"]=3
|
|
||||||
|
|
||||||
id_to_word={value:key for key,value in word_to_id.items()}
|
|
||||||
some_number=4*8-1
|
|
||||||
review_as_text=''.join(id_to_word[id] for id in X_train[some_number])
|
|
||||||
print(X_train[some_number])
|
|
||||||
print(review_as_text)
|
|
||||||
print(len(X_train[some_number]))
|
|
||||||
if y_train[some_number] == 1:
|
|
||||||
class_label='Positive'
|
|
||||||
else:
|
|
||||||
class_label='Negative'
|
|
||||||
|
|
||||||
|
|
||||||
[1, 4, 2112, 512, 9, 150, 6, 4737, 875, 31, 15, 9, 99, 400, 2, 8, 2111, 11, 2, 4, 201, 9, 6, 2, 7, 960, 1807, 15, 28, 77, 2, 11, 45, 512, 2670, 4, 927, 28, 4677, 725, 14, 3279, 34, 1855, 6, 1882, 63, 47, 77, 2, 8, 12, 4, 2, 9, 35, 1711, 823, 4296, 15, 2, 45, 1500, 19, 1987, 1137, 15, 9, 2, 19, 1302, 2, 486, 5, 2, 567, 4, 1317, 2311, 1223, 2, 9, 2, 17, 6, 2, 831, 2, 7, 1092, 5, 1515, 1234, 34, 27, 1051, 190, 1223, 9, 7, 107, 2, 31, 63, 9, 2, 137, 4, 85, 9, 2, 19, 3237, 5, 2, 19, 46, 101, 2, 42, 2, 13, 131, 2, 264, 15, 4, 2, 47, 4, 1885, 3137, 177, 7, 1136, 1757, 32, 183, 1192, 13, 100, 97, 35, 3761, 2590, 23, 4, 201, 21, 13, 528, 48, 126, 50, 9, 6, 1114, 2, 11, 4564, 2, 1787, 18, 134, 2, 2, 2, 2, 1711, 2, 5, 4, 2, 2, 2, 80, 30, 4783, 208, 145, 33, 25]
|
|
||||||
<START>thegangstergenreisnowawornsubjectonethatistoooften<UNK>toparodyin<UNK>theseriesisa<UNK>ofpreviousclichésthathavebeen<UNK>init'sgenrethankfullythewritershaveadvanceduponthisflawbycreatingarealismwhichhasbeen<UNK>toitthe<UNK>isanepiccrimesagathat<UNK>it'scontentwithpsychologicaldepththatis<UNK>withsubtle<UNK>humorand<UNK>violencethekeyprotagonisttony<UNK>is<UNK>asa<UNK>general<UNK>offearandmoralvaluesbyhiscrewhowevertonyisoftwo<UNK>onewhichis<UNK>whiletheotheris<UNK>withguiltand<UNK>withoutany<UNK>or<UNK>istill<UNK>believethatthe<UNK>hasthefinestensemblecastofrecentmemoryallthingsconsideredicouldmakeanelaboratestatementontheseriesbutiwon'tifeverthereisavisual<UNK>inglobal<UNK>searchforthese<UNK><UNK><UNK><UNK>epic<UNK>andthe<UNK><UNK><UNK>willbesmilingrightbackatyou
|
|
||||||
182
|
|
||||||
```
|
|
||||||
|
|
||||||
**4)Вывести максимальную и минимальную длину отзыва в обучающем множестве.**
|
|
||||||
```py
|
|
||||||
print('Review class:', y_train[some_number], f'({class_label})')
|
|
||||||
print(len(max(X_train, key=len)))
|
|
||||||
print(len(min(X_train, key=len)))
|
|
||||||
|
|
||||||
Review class: 1 (Positive)
|
|
||||||
2494
|
|
||||||
11
|
|
||||||
```
|
|
||||||
|
|
||||||
**5)Провести предобработку данных. Выбрать единую длину, к которой будут приведены все отзывы. Короткие отзывы дополнить спецсимволами, а длинные обрезать до выбранной длины.**
|
|
||||||
```py
|
|
||||||
from keras.preprocessing import sequence
|
|
||||||
max_words=500
|
|
||||||
X_train=sequence.pad_sequences(X_train, maxlen=max_words, value=0, padding='pre', truncating='post')
|
|
||||||
X_test=sequence.pad_sequences(X_test, maxlen=max_words, value=0, padding='pre', truncating='post')
|
|
||||||
```
|
|
||||||
|
|
||||||
**6-7)Повторить п. 3,4.**
|
|
||||||
```py
|
|
||||||
word_to_id=imdb.get_word_index()
|
|
||||||
|
|
||||||
word_to_id={key:(value + index_from) for key,value in word_to_id.items()}
|
|
||||||
word_to_id["<PAD>"]=0
|
|
||||||
word_to_id["<START>"]=1
|
|
||||||
word_to_id["<UNK>"]=2
|
|
||||||
word_to_id["<UNUSED>"]=3
|
|
||||||
|
|
||||||
id_to_word={value:key for key,value in word_to_id.items()}
|
|
||||||
some_number=4*8-1
|
|
||||||
review_as_text=''.join(id_to_word[id] for id in X_train[some_number])
|
|
||||||
print(X_train[some_number])
|
|
||||||
print(review_as_text)
|
|
||||||
print(len(X_train[some_number]))
|
|
||||||
if y_train[some_number] == 1:
|
|
||||||
class_label='Positive'
|
|
||||||
else:
|
|
||||||
class_label='Negative'
|
|
||||||
print('Review class:', y_train[some_number], f'({class_label})')
|
|
||||||
print(len(max(X_train, key=len)))
|
|
||||||
print(len(min(X_train, key=len)))
|
|
||||||
|
|
||||||
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
|
||||||
0 0 0 0 0 0 0 0 0 0 1 4 2112 512
|
|
||||||
9 150 6 4737 875 31 15 9 99 400 2 8 2111 11
|
|
||||||
2 4 201 9 6 2 7 960 1807 15 28 77 2 11
|
|
||||||
45 512 2670 4 927 28 4677 725 14 3279 34 1855 6 1882
|
|
||||||
63 47 77 2 8 12 4 2 9 35 1711 823 4296 15
|
|
||||||
2 45 1500 19 1987 1137 15 9 2 19 1302 2 486 5
|
|
||||||
2 567 4 1317 2311 1223 2 9 2 17 6 2 831 2
|
|
||||||
7 1092 5 1515 1234 34 27 1051 190 1223 9 7 107 2
|
|
||||||
31 63 9 2 137 4 85 9 2 19 3237 5 2 19
|
|
||||||
46 101 2 42 2 13 131 2 264 15 4 2 47 4
|
|
||||||
1885 3137 177 7 1136 1757 32 183 1192 13 100 97 35 3761
|
|
||||||
2590 23 4 201 21 13 528 48 126 50 9 6 1114 2
|
|
||||||
11 4564 2 1787 18 134 2 2 2 2 1711 2 5 4
|
|
||||||
2 2 2 80 30 4783 208 145 33 25]
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
<PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><PAD><START>thegangstergenreisnowawornsubjectonethatistoooften<UNK>toparodyin<UNK>theseriesisa<UNK>ofpreviousclichésthathavebeen<UNK>init'sgenrethankfullythewritershaveadvanceduponthisflawbycreatingarealismwhichhasbeen<UNK>toitthe<UNK>isanepiccrimesagathat<UNK>it'scontentwithpsychologicaldepththatis<UNK>withsubtle<UNK>humorand<UNK>violencethekeyprotagonisttony<UNK>is<UNK>asa<UNK>general<UNK>offearandmoralvaluesbyhiscrewhowevertonyisoftwo<UNK>onewhichis<UNK>whiletheotheris<UNK>withguiltand<UNK>withoutany<UNK>or<UNK>istill<UNK>believethatthe<UNK>hasthefinestensemblecastofrecentmemoryallthingsconsideredicouldmakeanelaboratestatementontheseriesbutiwon'tifeverthereisavisual<UNK>inglobal<UNK>searchforthese<UNK><UNK><UNK><UNK>epic<UNK>andthe<UNK><UNK><UNK>willbesmilingrightbackatyou
|
|
||||||
500
|
|
||||||
Review class: 1 (Positive)
|
|
||||||
500
|
|
||||||
500
|
|
||||||
```
|
|
||||||
|
|
||||||
```py
|
|
||||||
**8)Вывести предобработанные массивы обучающих и тестовых данных и их размерности.**
|
|
||||||
print("x_train: ", X_train)
|
|
||||||
print(X_train.shape)
|
|
||||||
print("x_test: ", X_test)
|
|
||||||
print(X_test.shape)
|
|
||||||
|
|
||||||
|
|
||||||
x_train: [[ 0 0 0 ... 2 4050 2]
|
|
||||||
[ 0 0 0 ... 721 90 180]
|
|
||||||
[ 0 0 0 ... 1114 2 174]
|
|
||||||
...
|
|
||||||
[ 1 1065 2022 ... 7 1514 2]
|
|
||||||
[ 0 0 0 ... 6 879 132]
|
|
||||||
[ 0 0 0 ... 12 152 157]]
|
|
||||||
(25000, 500)
|
|
||||||
x_test: [[ 0 0 0 ... 10 342 158]
|
|
||||||
[ 0 0 0 ... 2 67 12]
|
|
||||||
[ 0 0 0 ... 1242 1095 1095]
|
|
||||||
...
|
|
||||||
[ 0 0 0 ... 4 2 136]
|
|
||||||
[ 0 0 0 ... 14 31 591]
|
|
||||||
[ 0 0 0 ... 7 3923 212]]
|
|
||||||
(25000, 500)
|
|
||||||
```
|
|
||||||
|
|
||||||
**9) Реализовать модель рекуррентной нейронной сети, состоящей из слоев Embedding, LSTM, Dropout, Dense, и обучить ее на обучающих данных с выделением части обучающих данных в качестве валидационных. Вывести информацию об архитектуре нейронной сети. Добиться качества обучения по метрике accuracy не менее 0.8.**
|
|
||||||
```py
|
|
||||||
from keras.models import Sequential
|
|
||||||
from keras.layers import Embedding, LSTM, Dropout, Dense
|
|
||||||
|
|
||||||
model=Sequential()
|
|
||||||
model.add(Embedding(input_dim=len(word_to_id), output_dim=32, input_length=500))
|
|
||||||
model.add(LSTM(units=90))
|
|
||||||
model.add(Dropout(rate=0.4))
|
|
||||||
model.add(Dense(units=1, activation='sigmoid'))
|
|
||||||
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
|
|
||||||
H=model.fit(X_train, y_train, validation_split=0.1, epochs=5, batch_size=32)
|
|
||||||
print(model.summary())
|
|
||||||
|
|
||||||
Epoch 1/5
|
|
||||||
704/704 ━━━━━━━━━━━━━━━━━━━━ 232s 326ms/step - accuracy: 0.6650 - loss: 0.5766 - val_accuracy: 0.8552 - val_loss: 0.3558
|
|
||||||
Epoch 2/5
|
|
||||||
704/704 ━━━━━━━━━━━━━━━━━━━━ 253s 313ms/step - accuracy: 0.8611 - loss: 0.3344 - val_accuracy: 0.7944 - val_loss: 0.4277
|
|
||||||
Epoch 3/5
|
|
||||||
704/704 ━━━━━━━━━━━━━━━━━━━━ 264s 316ms/step - accuracy: 0.8672 - loss: 0.3235 - val_accuracy: 0.8584 - val_loss: 0.3852
|
|
||||||
Epoch 4/5
|
|
||||||
704/704 ━━━━━━━━━━━━━━━━━━━━ 263s 317ms/step - accuracy: 0.9013 - loss: 0.2555 - val_accuracy: 0.8688 - val_loss: 0.3254
|
|
||||||
Epoch 5/5
|
|
||||||
704/704 ━━━━━━━━━━━━━━━━━━━━ 225s 319ms/step - accuracy: 0.9245 - loss: 0.2050 - val_accuracy: 0.8752 - val_loss: 0.3455
|
|
||||||
Model: "sequential"
|
|
||||||
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
|
|
||||||
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
|
|
||||||
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
|
|
||||||
│ embedding (Embedding) │ (None, 500, 32) │ 2,834,816 │
|
|
||||||
├─────────────────────────────────┼────────────────────────┼───────────────┤
|
|
||||||
│ lstm (LSTM) │ (None, 90) │ 44,280 │
|
|
||||||
├─────────────────────────────────┼────────────────────────┼───────────────┤
|
|
||||||
│ dropout (Dropout) │ (None, 90) │ 0 │
|
|
||||||
├─────────────────────────────────┼────────────────────────┼───────────────┤
|
|
||||||
│ dense (Dense) │ (None, 1) │ 91 │
|
|
||||||
└─────────────────────────────────┴────────────────────────┴───────────────┘
|
|
||||||
Total params: 8,637,563 (32.95 MB)
|
|
||||||
Trainable params: 2,879,187 (10.98 MB)
|
|
||||||
Non-trainable params: 0 (0.00 B)
|
|
||||||
Optimizer params: 5,758,376 (21.97 MB)
|
|
||||||
```
|
|
||||||
|
|
||||||
**10)Оценить качество обучения на тестовых данных**
|
|
||||||
```py
|
|
||||||
scores=model.evaluate(X_test, y_test)
|
|
||||||
print("LOss: ", scores[0])
|
|
||||||
print("Accuracy: ", scores[1])
|
|
||||||
test_result=model.predict(X_test)
|
|
||||||
predicted_labels=[1 if test_result[i,0]>=0.5 else 0 for i in range(len(test_result))]
|
|
||||||
from sklearn.metrics import classification_report
|
|
||||||
print(classification_report(y_test, predicted_labels, labels=[0,1], target_names=["Negative", "Positive"]
|
|
||||||
|
|
||||||
|
|
||||||
782/782 ━━━━━━━━━━━━━━━━━━━━ 68s 87ms/step - accuracy: 0.8673 - loss: 0.3494
|
|
||||||
LOss: 0.35319784283638
|
|
||||||
Accuracy: 0.8662400245666504
|
|
||||||
782/782 ━━━━━━━━━━━━━━━━━━━━ 66s 84ms/step
|
|
||||||
precision recall f1-score support
|
|
||||||
|
|
||||||
Negative 0.87 0.86 0.87 12500
|
|
||||||
Positive 0.86 0.87 0.87 12500
|
|
||||||
|
|
||||||
accuracy 0.87 25000
|
|
||||||
macro avg 0.87 0.87 0.87 25000
|
|
||||||
weighted avg 0.87 0.87 0.87 25000
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
**Вывод:**
|
|
||||||
В ходе работы данные об отзывах на фильмы были загружены, обработаны и разбиты на тренировочную и тестовую выборки. Была создана и обучена рекуррентная нейронная сеть на основе ячеек LSTM. Точность обученной модели составила 0,86924.
|
|
||||||