27 KiB
Отчёт по лабораторной работе №3
по теме: "Распознавание изображений"
Выполнили: Бригада 2, Мачулина Д.В., Бирюкова А.С., А-02-22
Задание 1
1. Создание блокнота и настройка среды
from google.colab import drive
drive.mount('/content/drive')
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab3')
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
2. Загрузка набора данных MNIST
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
3. Разбиение набора данных на общучающие и тестовые (номер бригады - 2)
from sklearn.model_selection import train_test_split
# объединяем в один набор
X = np.concatenate((X_train, X_test))
y = np.concatenate((y_train, y_test))
# разбиваем по вариантам
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 10000,
train_size = 60000,
random_state = 7)
# вывод размерностей
print('Shape of X train:', X_train.shape)
print('Shape of y train:', y_train.shape)
print('Shape of X test:', X_test.shape)
print('Shape of y test:', y_test.shape)
Shape of X train: (60000, 28, 28)
Shape of y train: (60000,)
Shape of X test: (10000, 28, 28)
Shape of y test: (10000,)
4. Предобработка данных
# Зададим параметры данных и модели
num_classes = 10
input_shape = (28, 28, 1)
# Приведение входных данных к диапазону [0, 1]
X_train = X_train / 255
X_test = X_test / 255
# Расширяем размерность входных данных, чтобы каждое изображение имело размерность (высота, ширина, количество каналов)
X_train = np.expand_dims(X_train, -1)
X_test = np.expand_dims(X_test, -1)
print('Shape of transformed X train:', X_train.shape)
print('Shape of transformed X test:', X_test.shape)
# переведем метки в one-hot
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('Shape of transformed y train:', y_train.shape)
print('Shape of transformed y test:', y_test.shape)
Shape of transformed X train: (60000, 28, 28, 1)
hape of transformed X test: (10000, 28, 28, 1)
Shape of transformed y train: (60000, 10)
Shape of transformed y test: (10000, 10)
5. Реализация и обучение модели свёрточной нейронной сети
# создаем модель
model = Sequential()
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Dropout(0.5))
model.add(layers.Flatten())
model.add(layers.Dense(num_classes, activation="softmax"))
model.summary()
| Layer (type) | Output Shape | Param # |
|---|---|---|
| conv2d (Conv2D) | (None, 26, 26, 32) | 320 |
| max_pooling2d (MaxPooling2D) | (None, 13, 13, 32) | 0 |
| conv2d_1 (Conv2D) | (None, 11, 11, 64) | 18,496 |
| max_pooling2d_1 (MaxPooling2D) | (None, 5, 5, 64) | 0 |
| dropout (Dropout) | (None, 5, 5, 64) | 0 |
| flatten (Flatten) | (None, 1600) | 0 |
| dense (Dense) | (None, 10) | 16,010 |
Total params: 34,826 (136.04 KB)
Trainable params: 34,826 (136.04 KB)
Non-trainable params: 0 (0.00 B)
# компилируем и обучаем модель
batch_size = 512
epochs = 15
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
6. Оценка качества обучения на тестовых данных
scores = model.evaluate(X_test, y_test)
print('Loss on test data:', scores[0])
print('Accuracy on test data:', scores[1])
Loss on test data: 0.04353996366262436
Accuracy on test data: 0.9876000285148621
7. Подача на вход обученной модели тестовых изображений
# вывод тестового изображения и результата распознавания
n = 333
result = model.predict(X_test[n:n+1])
print('NN output:', result)
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
plt.show()
print('Real mark: ', np.argmax(y_test[n]))
print('NN answer: ', np.argmax(result))

Real mark: 3
NN answer: 3
# вывод тестового изображения и результата распознавания
n = 222
result = model.predict(X_test[n:n+1])
print('NN output:', result)
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
plt.show()
print('Real mark: ', np.argmax(y_test[n]))
print('NN answer: ', np.argmax(result))
Real mark: 2
NN answer: 2
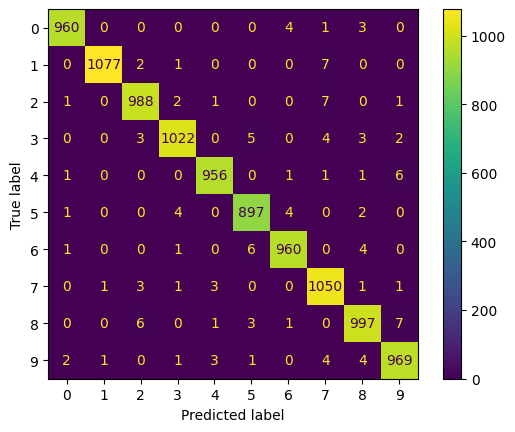
8. Вывод отчёта о качестве классификации тестовой выборки и матрицы ошибок для тестовой выборки
# истинные метки классов
true_labels = np.argmax(y_test, axis=1)
# предсказанные метки классов
predicted_labels = np.argmax(model.predict(X_test), axis=1)
# отчет о качестве классификации
print(classification_report(true_labels, predicted_labels))
# вычисление матрицы ошибок
conf_matrix = confusion_matrix(true_labels, predicted_labels)
# отрисовка матрицы ошибок в виде "тепловой карты"
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix)
display.plot()
plt.show()
| №(type) | precision | recall | f1-score | support |
|---|---|---|---|---|
| 0 | 0.99 | 0.99 | 0.99 | 968 |
| 1 | 1.00 | 0.99 | 0.99 | 1087 |
| 2 | 0.99 | 0.99 | 0.99 | 1000 |
| 3 | 0.99 | 0.98 | 0.99 | 1039 |
| 4 | 0.99 | 0.99 | 0.99 | 966 |
| 5 | 0.98 | 0.99 | 0.99 | 908 |
| 6 | 0.99 | 0.99 | 0.99 | 972 |
| 7 | 0.98 | 0.99 | 0.98 | 1060 |
| 8 | 0.98 | 0.98 | 0.98 | 1015 |
| 9 | 0.98 | 0.98 | 0.98 | 985 |
| accuracy | 0.99 | 10000 | ||
| macro avg | 0.99 | 0.99 | 0.99 | 10000 |
| weighted avg | 0.99 | 0.99 | 0.99 | 10000 |
9. Загрузка, предобработка и подача собственных изображения
# загрузка собственного изображения
from PIL import Image
file_data = Image.open('7.png')
file_data = file_data.convert('L') # перевод в градации серого
test_img = np.array(file_data)
# вывод собственного изображения
plt.imshow(test_img, cmap=plt.get_cmap('gray'))
plt.show()
# предобработка
test_img = test_img / 255
test_img = np.reshape(test_img, (1,28,28,1))
# распознавание
result = model.predict(test_img)
print('I think it\'s ', np.argmax(result))
I think it's 7
# загрузка собственного изображения
from PIL import Image
file_data = Image.open('5.png')
file_data = file_data.convert('L') # перевод в градации серого
test_img = np.array(file_data)
# вывод собственного изображения
plt.imshow(test_img, cmap=plt.get_cmap('gray'))
plt.show()
# предобработка
test_img = test_img / 255
test_img = np.reshape(test_img, (1,28,28,1))
# распознавание
result = model.predict(test_img)
print('I think it\'s ', np.argmax(result))
I think it's 5
10. Загрузка модели из ЛР1. Оценка качества
model = keras.models.load_model("best_model.keras")
model.summary()
| Layer (type) | Output Shape | Param # |
|---|---|---|
| dense_4 (Dense) | (None, 300) | 235,500 |
| dense_5 (Dense) | (None, 10) | 3,010 |
Total params: 238,512 (931.69 KB) Trainable params: 238,510 (931.68 KB) Non-trainable params: 0 (0.00 B) Optimizer params: 2 (12.00 B)
# развернем каждое изображение 28*28 в вектор 784
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 10000,
train_size = 60000,
random_state = 7)
num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape(X_train.shape[0], num_pixels) / 255
X_test = X_test.reshape(X_test.shape[0], num_pixels) / 255
print('Shape of transformed X train:', X_train.shape)
print('Shape of transformed X train:', X_test.shape)
# переведем метки в one-hot
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('Shape of transformed y train:', y_train.shape)
print('Shape of transformed y test:', y_test.shape)
Shape of transformed X train: (60000, 784) Shape of transformed X train: (10000, 784) Shape of transformed y train: (60000, 10) Shape of transformed y test: (10000, 10)
# Оценка качества работы модели на тестовых данных
scores = model.evaluate(X_test, y_test)
print('Loss on test data:', scores[0])
print('Accuracy on test data:', scores[1])
Loss on test data: 0.37091827392578125
Accuracy on test data: 0.9013000130653381
11. Сравнение обученной модели сверточной сети и наилучшей модели полносвязной сети
| Модель | Количество настраиваемых параметров сети | Количество эпох обучения | Качество классификации тестовой выборки |
|---|---|---|---|
| Сверточная | 34,826 | 15 | 0.9876 |
| Полносвязная | 238,512 | 100 | 0.9013 |
Вывод: В ходе лабораторной работы были получены результаты, представленные в таблице. Исходя из них можно сделать вывод, что свёрточная нейронная сеть подходит для задачи распознавания изображений гораздо лучше, чем полносвязная. Для качества классификации 0,9876 понадобилось всего 15 эпох обучения и 35 настраиваемых параметров сети против качества в 0,9013, 100 эпох и 239 параметров для полносвязной сети.
Задание 2
В новом блокноте выполнили п.1-8 задания 1, изменив набор данных MNIST на CIFAR-10
1. Создание блокнота и настройка среды
from google.colab import drive
drive.mount('/content/drive')
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab3')
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
2.Загрузка набора данных и его разбиение на ообучащие и тестовые
# загрузка датасета
from keras.datasets import cifar10
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# создание своего разбиения датасета
from sklearn.model_selection import train_test_split
# объединяем в один набор
X = np.concatenate((X_train, X_test))
y = np.concatenate((y_train, y_test))
# разбиваем по вариантам
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 10000,
train_size = 50000,
random_state = 7)
# вывод размерностей
print('Shape of X train:', X_train.shape)
print('Shape of y train:', y_train.shape)
print('Shape of X test:', X_test.shape)
print('Shape of y test:', y_test.shape)
Shape of X train: (50000, 32, 32, 3)
Shape of y train: (50000, 1)
Shape of X test: (10000, 32, 32, 3)
Shape of y test: (10000, 1)
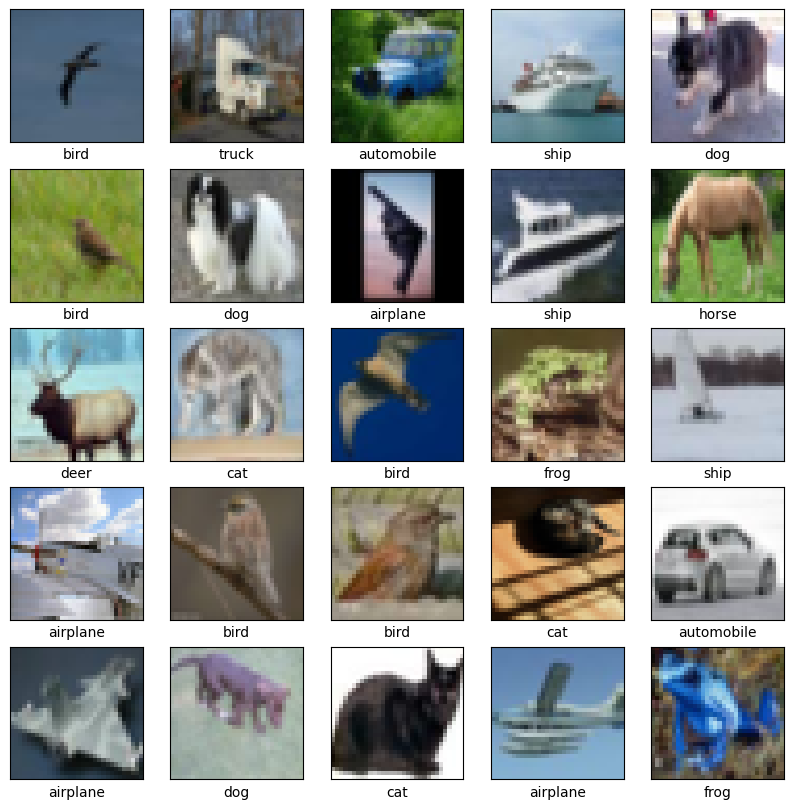
3. Вывод изображений с подписями классов
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(X_train[i])
plt.xlabel(class_names[y_train[i][0]])
plt.show()
4. Предобработка данных
# Зададим параметры данных и модели
num_classes = 10
input_shape = (32, 32, 3)
# Приведение входных данных к диапазону [0, 1]
X_train = X_train / 255
X_test = X_test / 255
print('Shape of transformed X train:', X_train.shape)
print('Shape of transformed X test:', X_test.shape)
# переведем метки в one-hot
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('Shape of transformed y train:', y_train.shape)
print('Shape of transformed y test:', y_test.shape)
Shape of transformed X train: (50000, 32, 32, 3) Shape of transformed X test: (10000, 32, 32, 3) Shape of transformed y train: (50000, 10) Shape of transformed y test: (10000, 10)
5. Реализация и обучение модели свёрточной нейронной сети
# создаем модель
model = Sequential()
# Блок 1
model.add(layers.Conv2D(32, (3, 3), padding="same",
activation="relu", input_shape=input_shape))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(32, (3, 3), padding="same", activation="relu"))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.25))
# Блок 2
model.add(layers.Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.25))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(num_classes, activation="softmax"))
model.summary()
| Layer (type) | Output Shape | Param # |
|---|---|---|
| conv2d (Conv2D) | (None, 32, 32, 32) | 896 |
| batch_normalization_6 (BatchNormalization) | (None, 32, 32, 32) | 128 |
| conv2d_13 (Conv2D) | (None, 32, 32, 32) | 9,248 |
| batch_normalization_7 (BatchNormalization) | (None, 32, 32, 32) | 128 |
| max_pooling2d_9 (MaxPooling2D) | (None, 16, 16, 32) | 0 |
| dropout_6 (Dropout) | (None, 16, 16, 32) | 0 |
| conv2d_14 (Conv2D) | (None, 16, 16, 64) | 18,496 |
| batch_normalization_8 (BatchNormalization) | (None, 16, 16, 64) | 256 |
| conv2d_15 (Conv2D) | (None, 16, 16, 64) | 32,928 |
| batch_normalization_9 (BatchNormalization) | (None, 16, 16, 64) | 256 |
| max_pooling2d_10 (MaxPooling2D) | (None, 8, 8, 64) | 0 |
| dropout_7 (Dropout) | (None, 8, 8, 64) | 0 |
| flatten_3 (Flatten) | (None, 4096) | 0 |
| dense_6 (Dense) | (None, 128) | 524,416 |
| dropout_8 (Dropout) | (None, 128) | 0 |
| dense_7 (Dense) | (None, 10) | 1,290 |
batch_size = 64
epochs = 50
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
6. Оценка качества обучения на тестовых данных
scores = model.evaluate(X_test, y_test)
print('Loss on test data:', scores[0])
print('Accuracy on test data:', scores[1])
7. Подача на вход обученной модели тестовых изображений
for n in [5,17]:
result = model.predict(X_test[n:n+1])
print('NN output:', result)
plt.imshow(X_test[n].reshape(32,32,3), cmap=plt.get_cmap('gray'))
plt.show()
print('Real mark: ', np.argmax(y_test[n]))
print('NN answer: ', np.argmax(result))
Real mark: 0
NN answer: 2

Real mark: 5
NN answer: 5
8. Вывод отчёта о качестве классификации тестовой выборки и матрицы ошибок для тестовой выборки
# истинные метки классов
true_labels = np.argmax(y_test, axis=1)
# предсказанные метки классов
predicted_labels = np.argmax(model.predict(X_test), axis=1)
# отчет о качестве классификации
print(classification_report(true_labels, predicted_labels, target_names=class_names))
# вычисление матрицы ошибок
conf_matrix = confusion_matrix(true_labels, predicted_labels)
# отрисовка матрицы ошибок в виде "тепловой карты"
fig, ax = plt.subplots(figsize=(6, 6))
disp = ConfusionMatrixDisplay(confusion_matrix=conf_matrix,display_labels=class_names)
disp.plot(ax=ax, xticks_rotation=45) # поворот подписей по X и приятная палитра
plt.tight_layout() # чтобы всё влезло
plt.show()
| class | precision | recall | f1-score | support |
|---|---|---|---|---|
| airplane | 0.85 | 0.86 | 0.86 | 1013 |
| automobile | 0.93 | 0.91 | 0.92 | 989 |
| bird | 0.75 | 0.75 | 0.75 | 1018 |
| cat | 0.69 | 0.66 | 0.67 | 1049 |
| deer | 0.79 | 0.78 | 0.78 | 1009 |
| dog | 0.73 | 0.68 | 0.71 | 978 |
| frog | 0.79 | 0.90 | 0.84 | 981 |
| horse | 0.88 | 0.84 | 0.86 | 986 |
| ship | 0.89 | 0.92 | 0.91 | 1029 |
| truck | 0.88 | 0.91 | 0.89 | 948 |
| accuracy | 0.82 | 10000 | ||
| macro avg | 0.82 | 0.82 | 0.82 | 10000 |
| weighted avg | 0.82 | 0.82 | 0.82 | 10000 |
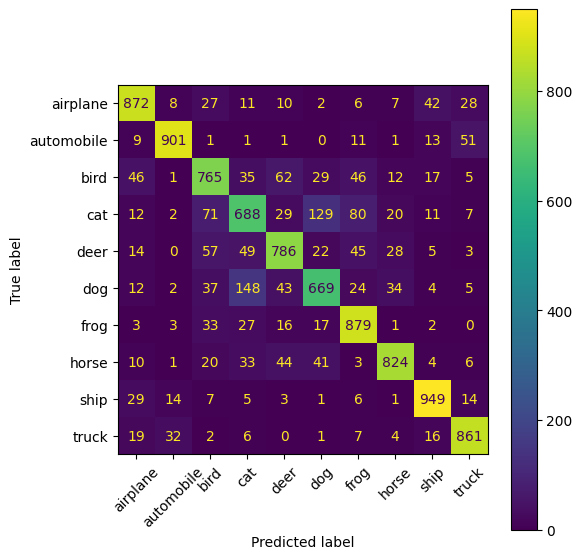
Вывод: Заметим, что модель НС, предназначенная для датасета CIFAR-10 неплохо справилась со своей задачей - точность распознавания составила 81%. Однако, несмотря на более сложную структуру модели, точность распознавания оказалась ниже, чем у модели, предназначенной для набора данных MNIST. Это может быть связано с типом классифицируемых данных - распознавать цветные изображения гораздо сложнее, чем чёрно-белые цифры. Для того, чтобы повысить точность распознавания картинок можно и нужно усложнить структуру НС, а именно увеличить количество слоёв и эпох, а также количество примеров (в нашем случае их было 50000)