форкнуто от main/is_dnn
Вы не можете выбрать более 25 тем
Темы должны начинаться с буквы или цифры, могут содержать дефисы(-) и должны содержать не более 35 символов.
976 строки
28 KiB
Markdown
976 строки
28 KiB
Markdown
# Отчёт по лабораторной работе №2
|
|
## по теме: "Обнаружение аномалий"
|
|
|
|
---
|
|
Выполнили: Бригада 2, Мачулина Д.В., Бирюкова А.С., А-02-22
|
|
|
|
Данные - WBC
|
|
|
|
---
|
|
|
|
## Задание 1
|
|
### 1. Создание блокнота и настройка среды
|
|
|
|
```python
|
|
from google.colab import drive
|
|
drive.mount('/content/drive')
|
|
import os
|
|
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab2')
|
|
import numpy as np
|
|
import lab02_lib as lib
|
|
```
|
|
|
|
```python
|
|
work_dir = '/content/drive/MyDrive/Colab Notebooks/is_lab2'
|
|
os.makedirs(work_dir, exist_ok=True)
|
|
os.chdir(work_dir)
|
|
os.makedirs('out', exist_ok=True)
|
|
dataset_name = 'WBC'
|
|
base_url = "http://uit.mpei.ru/git/main/is_dnn/raw/branch/main/labworks/LW2/"
|
|
!wget -N {base_url}lab02_lib.py
|
|
!wget -N {base_url}data/{dataset_name}_train.txt
|
|
!wget -N {base_url}data/{dataset_name}_test.txt
|
|
```
|
|
---
|
|
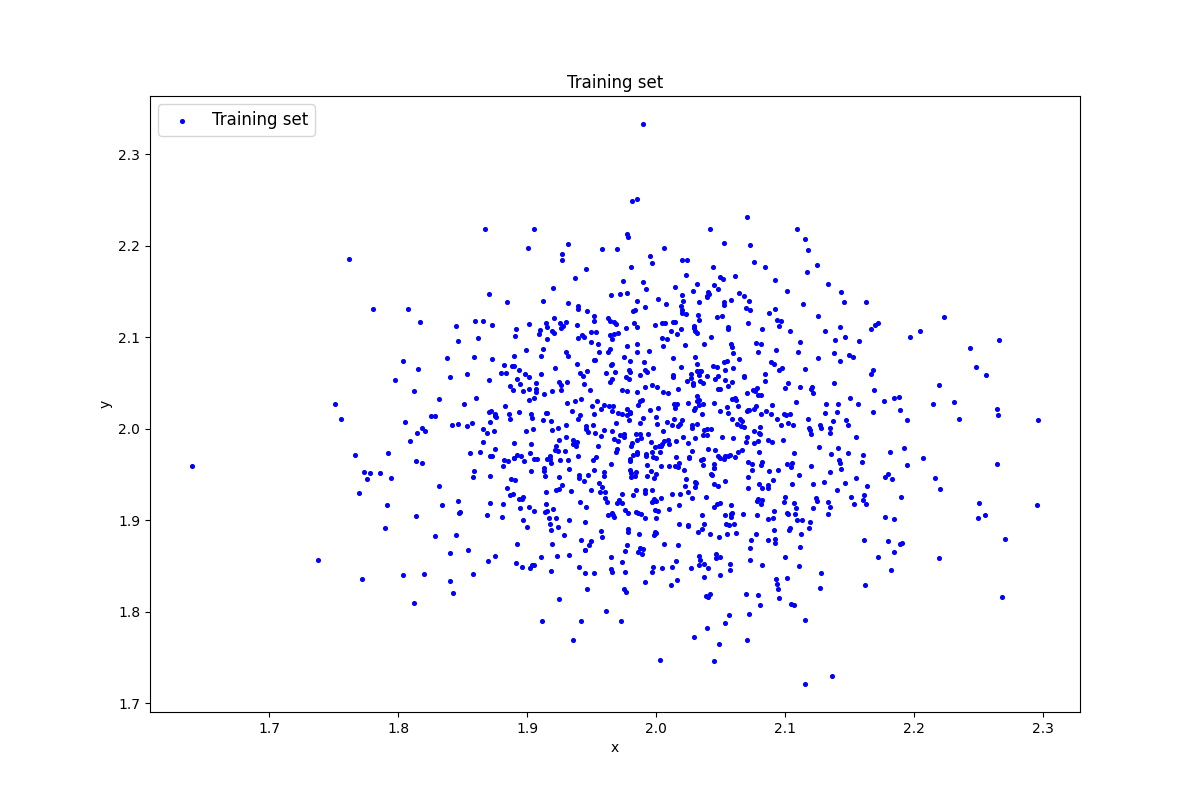
### 2. Генерация индивидуального набора двумерных данных
|
|
|
|
```python
|
|
data = lib.datagen(2, 2, 1000, 2)
|
|
|
|
print('Исходные данные:')
|
|
print(data)
|
|
print('Размерность данных:')
|
|
print(data.shape)
|
|
```
|
|
|
|
|
|
|
|
<table>
|
|
<thead>
|
|
<tr>
|
|
<th colspan=2 align="center">Исходные данные</th></tr>
|
|
</thead>
|
|
<tbody>
|
|
<tr>
|
|
<td>1.9863081 </td>
|
|
<td>1.86491133</td>
|
|
</tr>
|
|
<tr>
|
|
<td>2.04641244 </td>
|
|
<td>1.8589354</td>
|
|
</tr>
|
|
<tr>
|
|
<td>1.89688572</td>
|
|
<td>1.89978633</td>
|
|
</tr>
|
|
<tr>
|
|
<td colspan =2 align="center">...</td>
|
|
</tr>
|
|
<tr>
|
|
<td>1.99310837</td>
|
|
<td>2.06214288</td>
|
|
</tr>
|
|
<tr>
|
|
<td>1.94695115</td>
|
|
<td>1.99630611</td>
|
|
</tr>
|
|
<tr>
|
|
<td>1.79129354</td>
|
|
<td>1.91688919</td>
|
|
</tr>
|
|
</tbody>
|
|
</table>
|
|
|
|
Размерность данных: (1000, 2)
|
|
|
|
---
|
|
### 3. Создание и обучение автокодировщика АЕ1 простой архитектуры
|
|
```python
|
|
patience = 300
|
|
ae1_trained, IRE1, IREth1 = lib.create_fit_save_ae(data,'out/AE1.h5','out/AE1_ire_th.txt',
|
|
1000, True, patience)
|
|
```
|
|
Параметры: (1 скрытый слой, 1 нейрон)
|
|
|
|
---
|
|
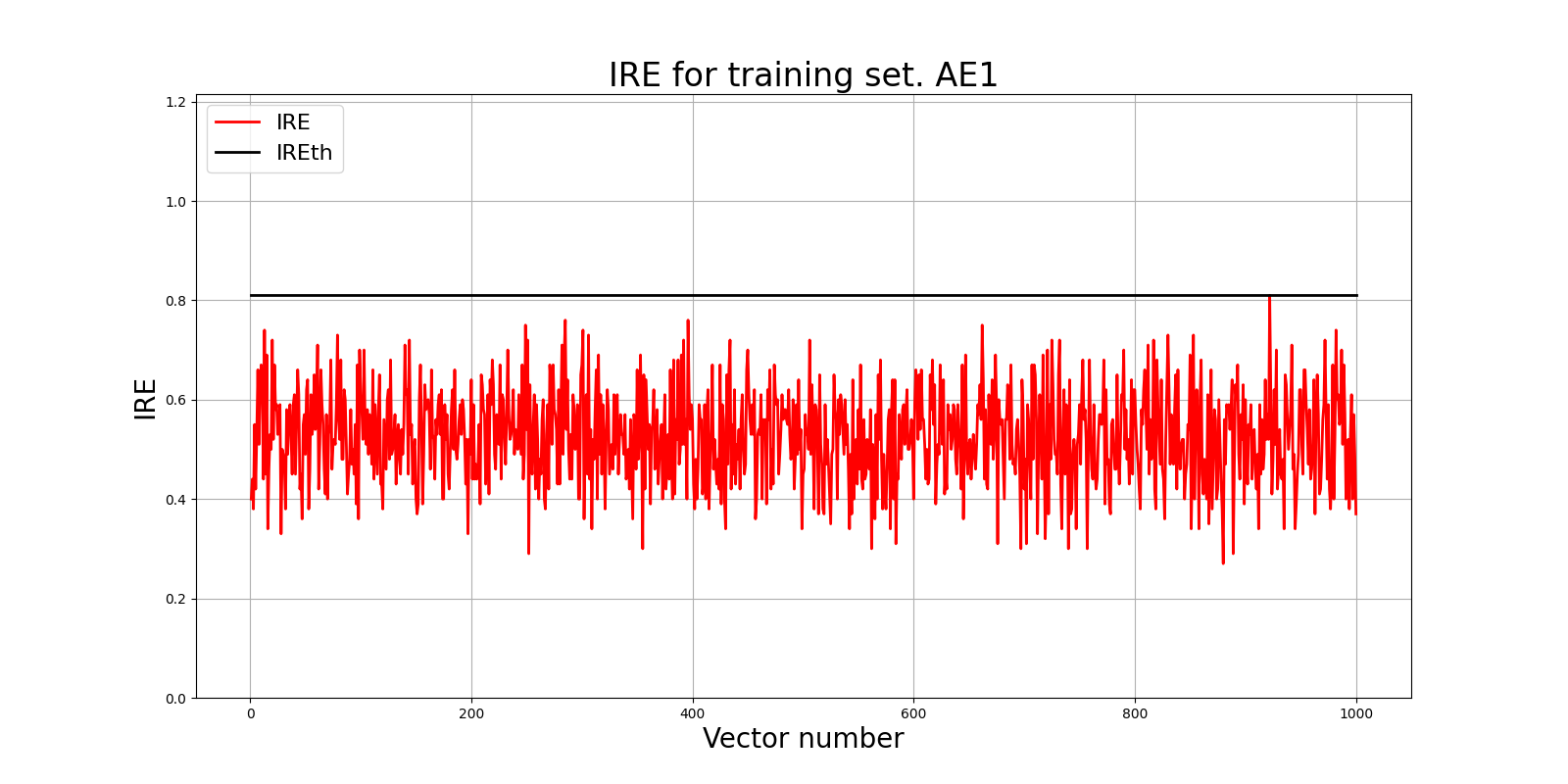
### 4. Построение графика ошибки реконструкции
|
|
Ошибка MSE_AE1 = 0.1370
|
|
```python
|
|
lib.ire_plot('training', IRE1, IREth1, 'AE1')
|
|
```
|
|
|
|
|
|
|
|
|
|
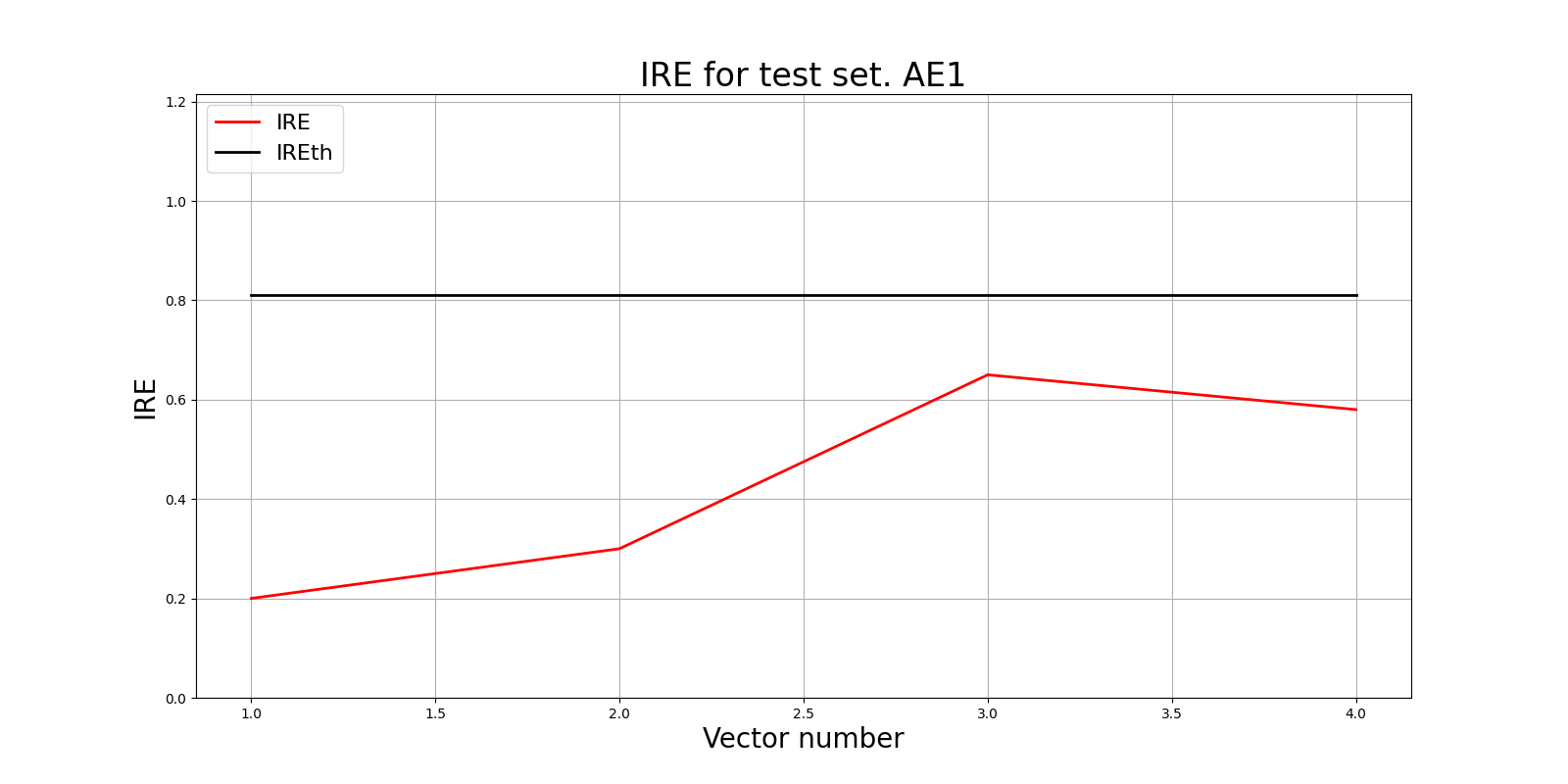
Порог ошибки реконструкции = 0.81
|
|
|
|
---
|
|
### 5. Создание и обучение автокодировщика АЕ2 усложнённой архитектуры
|
|
```python
|
|
ae2_trained, IRE2, IREth2 = lib.create_fit_save_ae(data,'out/AE2.h5','out/AE2_ire_th.txt',
|
|
3000, True, patience)
|
|
```
|
|
Параметры: (5 скрытых слоёв; 3 2 1 2 3)
|
|
|
|
---
|
|
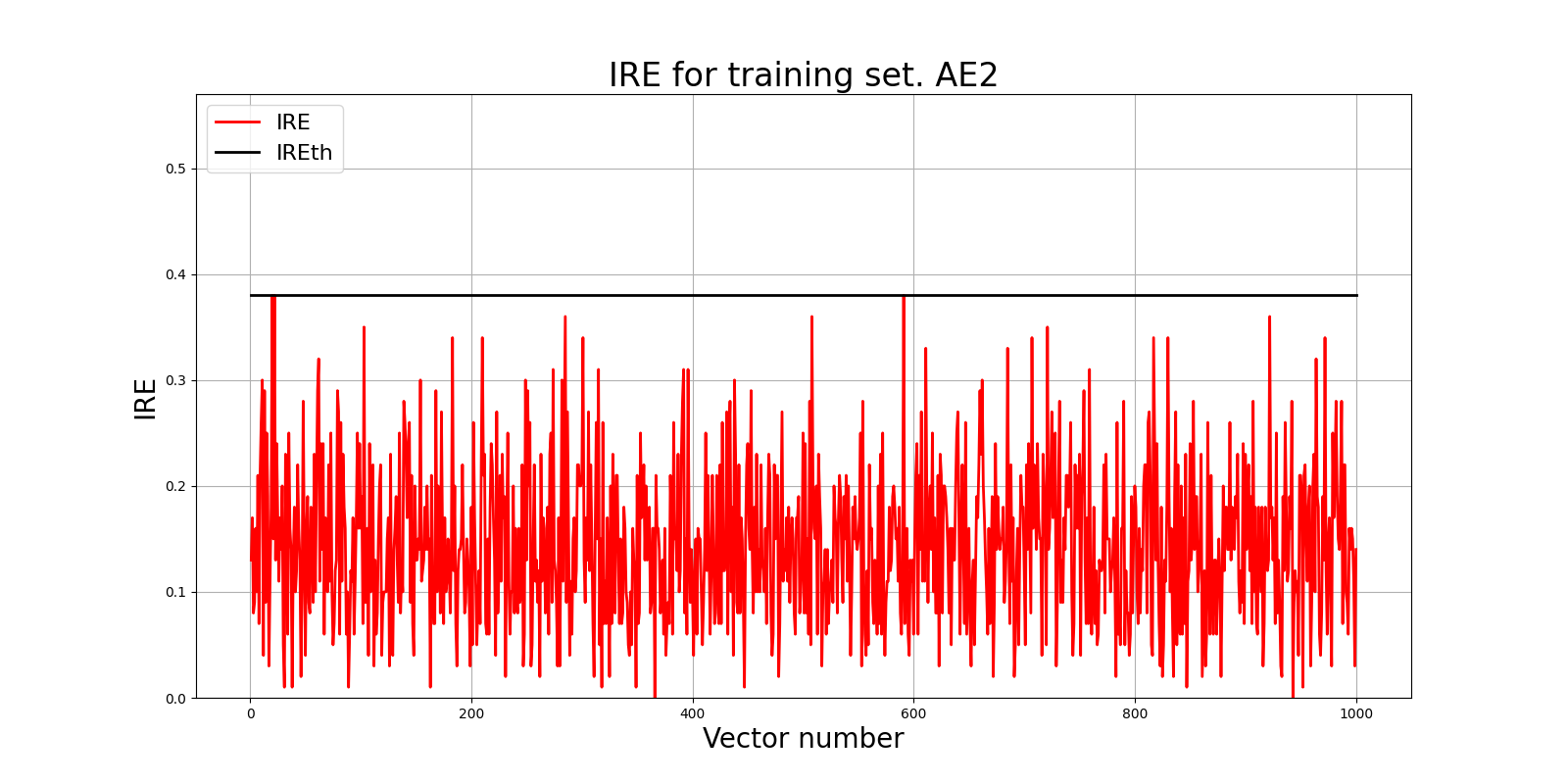
### 6. Построение графика ошибки реконструкции
|
|
Ошибка MSE_AE2 = 0.0094
|
|
```python
|
|
lib.ire_plot('training', IRE2, IREth2, 'AE2')
|
|
```
|
|
|
|
|
|
|
|
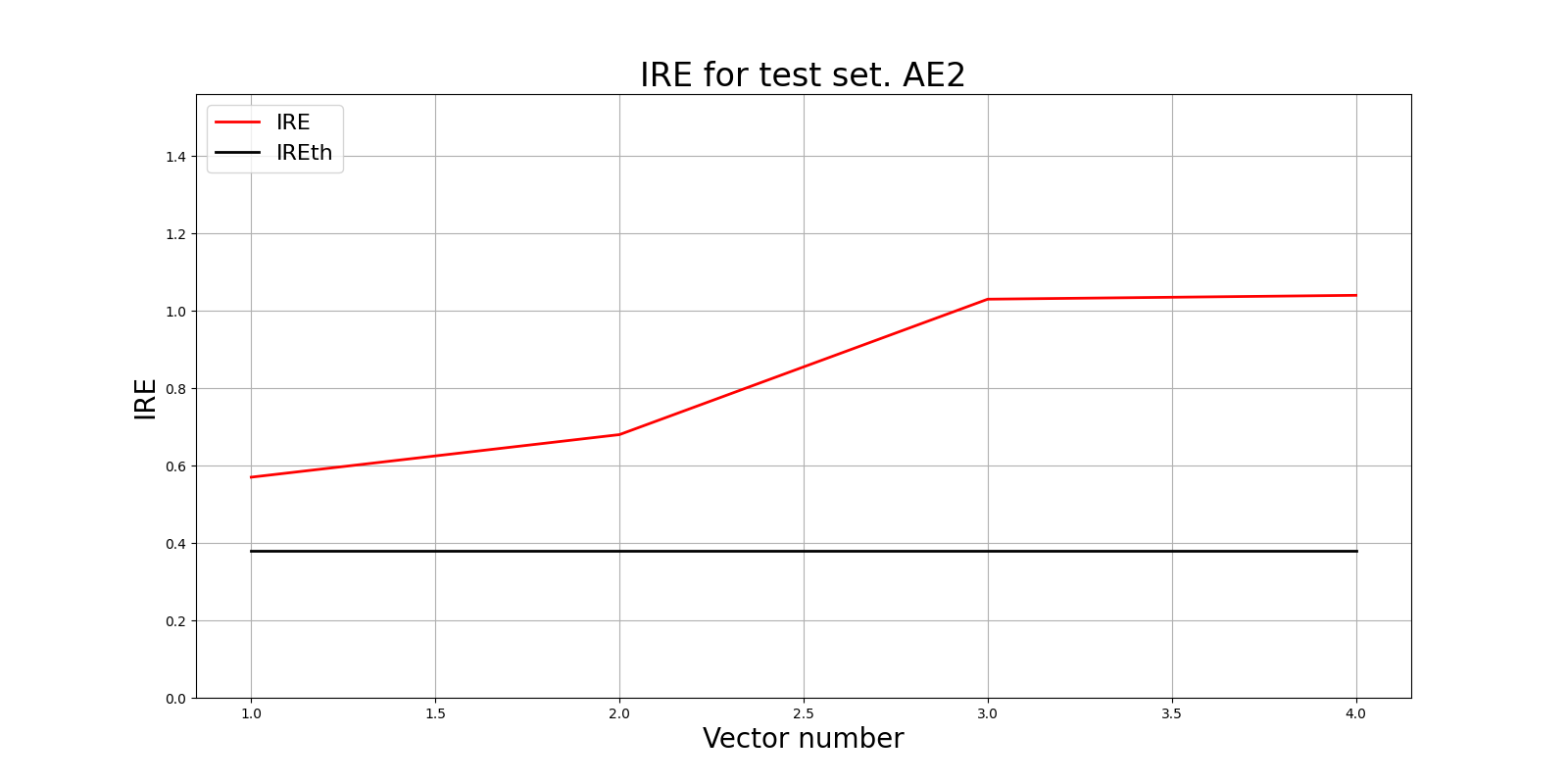
Порог ошибки реконструкции = 0.38
|
|
|
|
---
|
|
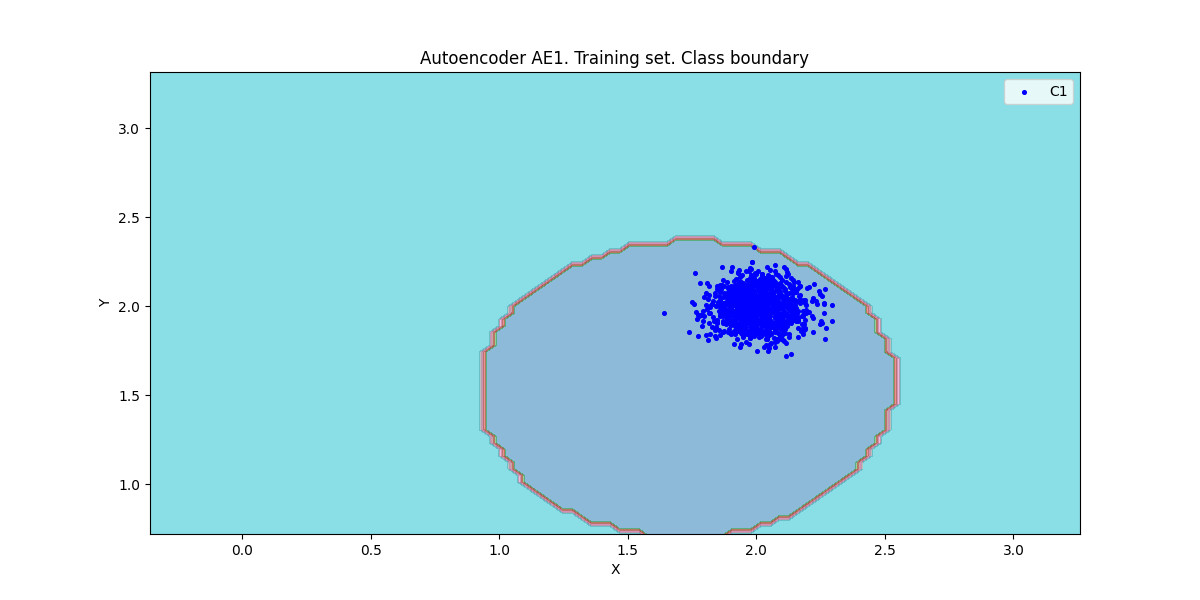
### 7. Расчёт характеристик качества обучения EDCA. Визуализация и сравнение
|
|
**АЕ1**
|
|
```python
|
|
numb_square = 20
|
|
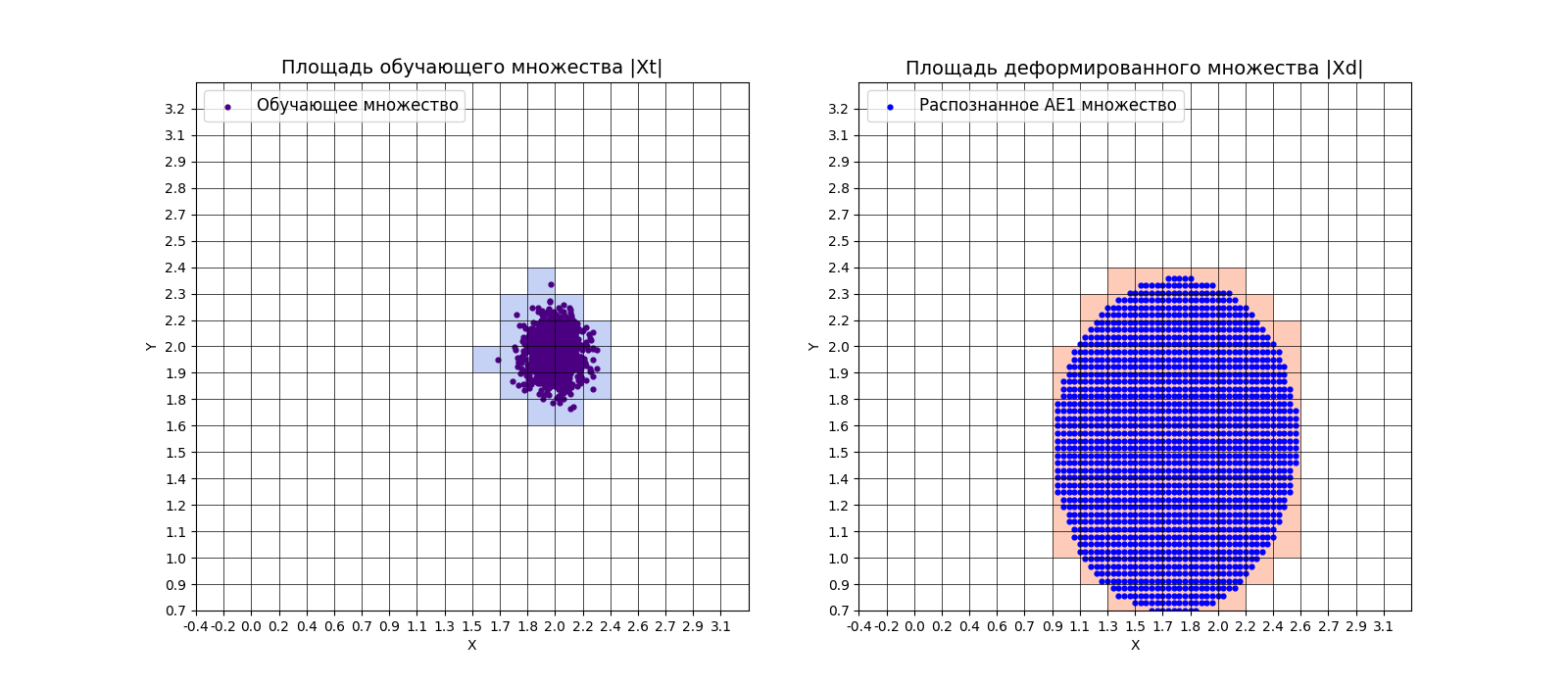
xx, yy, Z1 = lib.square_calc(numb_square, data, ae1_trained, IREth1, '1', True)
|
|
```
|
|
|
|
|
|
|
|
amount: 19
|
|
|
|
amount_ae: 104
|
|
|
|
|
|
|
|
|
|
|
|
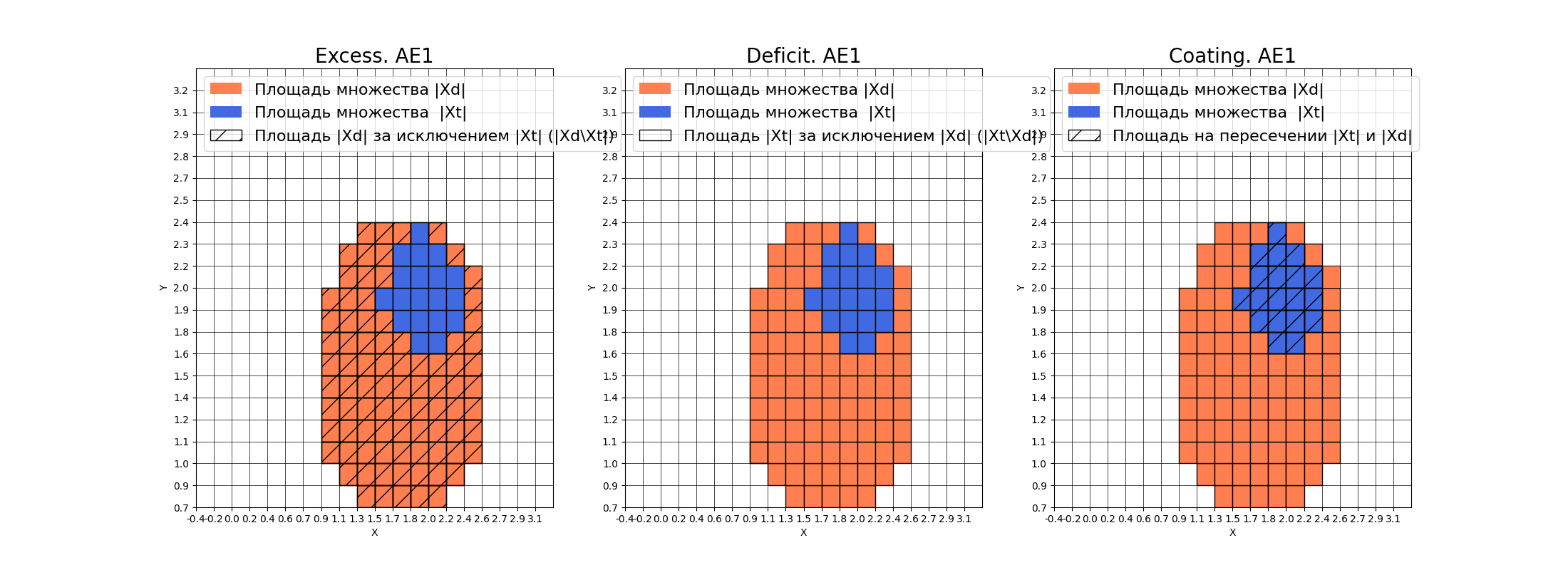
**Оценка качества AE1**
|
|
|
|
* IDEAL = 0. Excess: 4.473684210526316
|
|
|
|
* IDEAL = 0. Deficit: 0.0
|
|
|
|
* IDEAL = 1. Coating: 1.0
|
|
|
|
* summa: 1.0
|
|
|
|
* IDEAL = 1. Extrapolation precision (Approx): 0.18269230769230768
|
|
|
|
|
|
**АЕ2**
|
|
```python
|
|
numb_square = 20
|
|
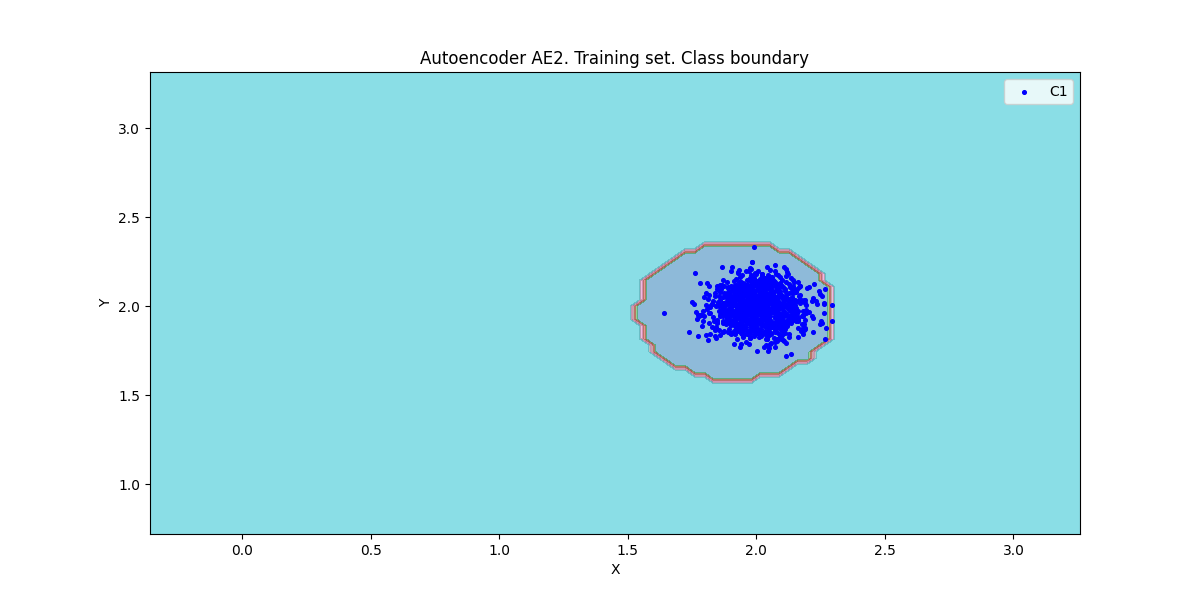
xx, yy, Z2 = lib.square_calc(numb_square, data, ae2_trained, IREth2, '2', True)
|
|
```
|
|
|
|
|
|
amount: 19
|
|
|
|
amount_ae: 31
|
|
|
|

|
|
|
|
|
|
|
|
|
|
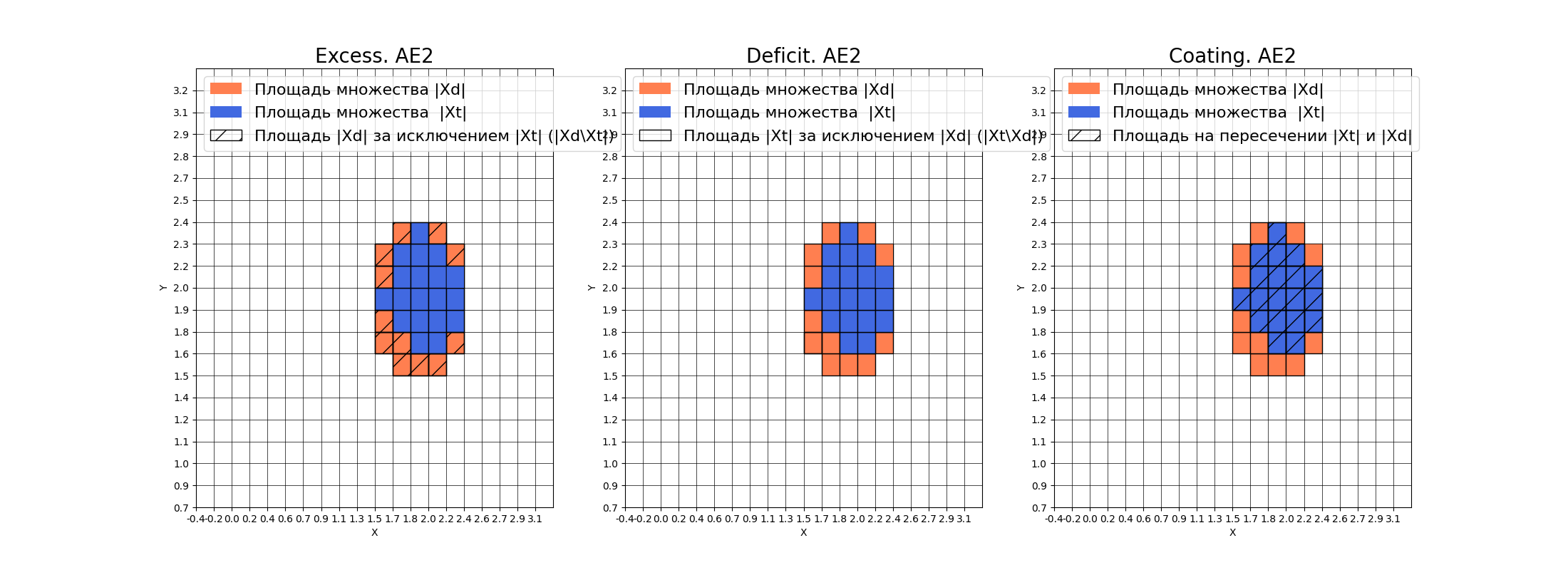
**Оценка качества АЕ2**
|
|
* IDEAL = 0. Excess: 0.631578947368421
|
|
* IDEAL = 0. Deficit: 0.0
|
|
* IDEAL = 1. Coating: 1.0
|
|
* summa: 1.0
|
|
* IDEAL = 1. Extrapolation precision (Approx): 0.612903225806
|
|
|
|
|
|
**Сравнение**
|
|
```python
|
|
lib.plot2in1(data, xx, yy, Z1, Z2)
|
|
```
|
|
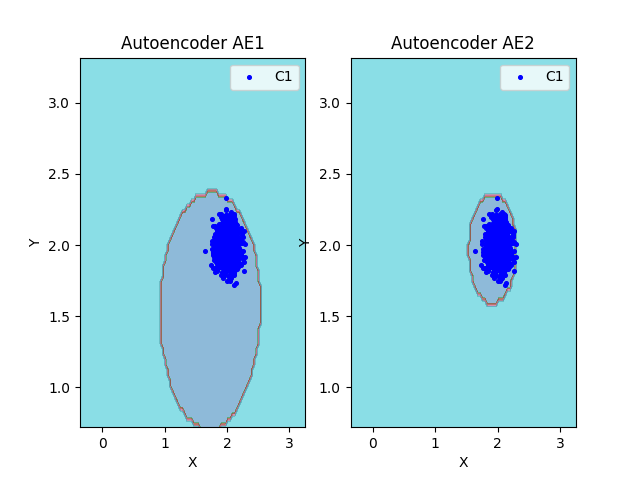
|
|
|
|
|
|
---
|
|
### 8. Редактирование автокодировщика АЕ2
|
|
Полученная аппроксимация автокодировщиком АЕ2 - удовлетворительна.
|
|
|
|
---
|
|
### 9. Создание тестовой выборки и применение к ней автокодировщиков
|
|
```python
|
|
with open('data_test.txt', 'w') as file:
|
|
file.write("1.5327 1.5591\n")
|
|
file.write("1.4373 1.4932\n")
|
|
file.write("1.1231 1.3212\n")
|
|
file.write("1.3211 1.1231\n")
|
|
data_test = np.loadtxt('data_test.txt', dtype=float)
|
|
print(data_test)
|
|
```
|
|
|
|
**АЕ1**
|
|
```python
|
|
predicted_labels1, ire1 = lib.predict_ae(ae1_trained, data_test, IREth1)
|
|
```
|
|
|
|
```python
|
|
lib.anomaly_detection_ae(predicted_labels1, ire1, IREth1)
|
|
lib.ire_plot('test', ire1, IREth1, 'AE1')
|
|
```
|
|
|
|
Аномалий не обнаружено
|
|
|
|
|
|
|
|
|
|
**АЕ2**
|
|
```python
|
|
predicted_labels2, ire2 = lib.predict_ae(ae2_trained, data_test, IREth2)
|
|
```
|
|
|
|
```python
|
|
lib.anomaly_detection_ae(predicted_labels2, ire2, IREth2)
|
|
lib.ire_plot('test', ire2, IREth2, 'AE2')
|
|
```
|
|
|
|
<table>
|
|
<thead>
|
|
<tr>
|
|
<th>i</th>
|
|
<th>labels</th>
|
|
<th>IRE</th>
|
|
<th>IREth</th>
|
|
</tr>
|
|
</thead>
|
|
<tbody>
|
|
<tr>
|
|
<td>0</td>
|
|
<td>[1.]</td>
|
|
<td>[0.57]</td>
|
|
<td>0.38</td>
|
|
</tr>
|
|
<tr>
|
|
<td>1</td>
|
|
<td>[1.]</td>
|
|
<td>[0.68]</td>
|
|
<td>0.38</td>
|
|
</tr>
|
|
<tr>
|
|
<td>2</td>
|
|
<td>[1.]</td>
|
|
<td>[1.03]</td>
|
|
<td>0.38</td>
|
|
</tr>
|
|
<tr>
|
|
<td>3</td>
|
|
<td>[1.]</td>
|
|
<td>[1.04]</td>
|
|
<td>0.38</td>
|
|
</tr>
|
|
</tbody>
|
|
</table>
|
|
|
|
Обнаружено 4.0 аномалий
|
|
|
|
|
|
|
|
|
|
### 10. Визуализация элементов обучающей и тестовой выборки в областях пространства признаков
|
|
```python
|
|
lib.plot2in1_anomaly(data, xx, yy, Z1, Z2, data_test)
|
|
```
|
|
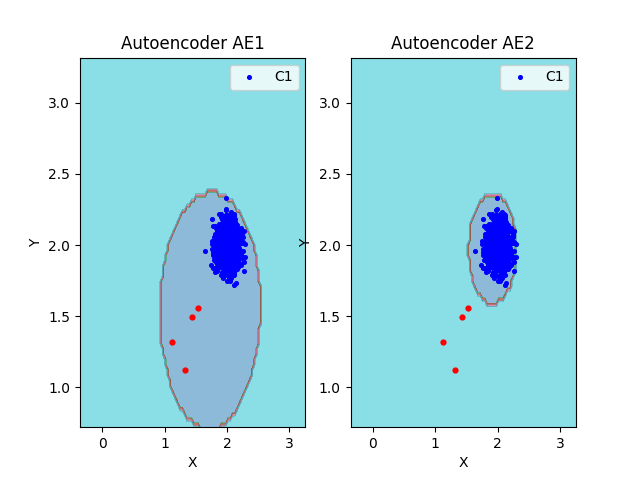
|
|
|
|
|
|
### 11. Результаты
|
|
<table>
|
|
<thead>
|
|
<tr>
|
|
<th> </th>
|
|
<th>Количество скрытых слоёв</th>
|
|
<th>Количество нейронов в скрытых слоях</th>
|
|
<th>Количество эпох обучения</th>
|
|
<th>Ошибка MSE_stop</th>
|
|
<th>Порог ошибки реконструкции</th>
|
|
<th>Значение показателя Excess</th>
|
|
<th>Значение показателя Approx</th>
|
|
<th>Количество обнаруженных аномалий</th>
|
|
</tr>
|
|
</thead>
|
|
<tbody>
|
|
<tr>
|
|
<td>АЕ1</td>
|
|
<td align="center">1</td>
|
|
<td align="center">1</td>
|
|
<td align="center">1000</td>
|
|
<td align="center">0.1370</td>
|
|
<td align="center">0.81</td>
|
|
<td align="center">4.473</td>
|
|
<td align="center">0.182</td>
|
|
<td align="center">0</td>
|
|
</tr>
|
|
<tr>
|
|
<td>АЕ2</td>
|
|
<td align="center">5</td>
|
|
<td align="center">3 2 1 2 3</td>
|
|
<td align="center">3000</td>
|
|
<td align="center">0.0094</td>
|
|
<td align="center">0.38</td>
|
|
<td align="center">0.631</td>
|
|
<td align="center">0.612</td>
|
|
<td align="center">4</td>
|
|
</tr>
|
|
</tbody>
|
|
</table>
|
|
|
|
|
|
## Задание 2
|
|
### 1. Изучение набора реальных данных
|
|
Исходный набор данных Breast Cancer Wisconsin представляет собой набор данных для
|
|
классификации, в котором записываются измерения для случаев рака молочной железы.
|
|
Есть два класса, доброкачественные и злокачественные. Злокачественный класс этого
|
|
набора данных уменьшен до 21 точки, которые считаются аномалиями, в то время как
|
|
точки в доброкачественном классе считаются нормой
|
|
|
|
<table>
|
|
<thead>
|
|
<tr>
|
|
<th> </th>
|
|
<th>Количество признаков</th>
|
|
<th>Количество примеров</th>
|
|
<th>Количество нормальных примеров</th>
|
|
<th>Количество аномальных примеров</th>
|
|
</tr>
|
|
</thead>
|
|
<tbody>
|
|
<tr>
|
|
<td>АЕ1</td>
|
|
<td align="center">30</td>
|
|
<td align="center">378</td>
|
|
<td align="center">357</td>
|
|
<td align="center">21</td>
|
|
</tr>
|
|
</tbody>
|
|
</table>
|
|
|
|
|
|
### 2. Загрузка обучающей и тестовой выборок
|
|
```python
|
|
train = np.loadtxt('WBC_train.txt', dtype=float)
|
|
print('train:\n', train)
|
|
print('train.shape:', np.shape(train))
|
|
```
|
|
train:
|
|
|
|
[[3.1042643e-01 1.5725397e-01 3.0177597e-01 ... 4.4261168e-01
|
|
2.7833629e-01 1.1511216e-01]
|
|
|
|
[2.8865540e-01 2.0290835e-01 2.8912998e-01 ... 2.5027491e-01
|
|
3.1914055e-01 1.7571822e-01]
|
|
|
|
[1.1940934e-01 9.2323301e-02 1.1436666e-01 ... 2.1398625e-01
|
|
1.7445299e-01 1.4882592e-01]
|
|
|
|
...
|
|
[3.3456387e-01 5.8978695e-01 3.2886463e-01 ... 3.6013746e-01
|
|
1.3502858e-01 1.8476978e-01]
|
|
|
|
[1.9967817e-01 6.6486304e-01 1.8575081e-01 ... 0.0000000e+00
|
|
1.9712202e-04 2.6301981e-02]
|
|
|
|
[3.6868759e-02 5.0152181e-01 2.8539838e-02 ... 0.0000000e+00
|
|
2.5744136e-01 1.0068215e-01]]
|
|
|
|
train.shape: (357, 30)
|
|
|
|
```python
|
|
test = np.loadtxt('WBC_test.txt', dtype=float)
|
|
print('\n test:\n', test)
|
|
print('test.shape:', np.shape(test))
|
|
```
|
|
|
|
test:
|
|
|
|
[[0.18784609 0.3936422 0.19425057 0.09654295 0.632572 0.31415251
|
|
0.24461106 0.28175944 0.42171717 0.3946925 0.04530147 0.23598833
|
|
0.05018141 0.01899148 0.21589557 0.11557064 0.0655303 0.19643872
|
|
0.08003602 0.07411246 0.17467094 0.62153518 0.18332586 0.08081007
|
|
0.79066235 0.23528442 0.32132588 0.48934708 0.2757737 0.26905418]
|
|
|
|
[0.71129727 0.41224214 0.71460162 0.56776246 0.48451747 0.53990553
|
|
0.57357076 0.74602386 0.38585859 0.24094356 0.3246424 0.07507514
|
|
0.32059558 0.23047901 0.0769963 0.19495599 0.09030303 0.27865126
|
|
0.10269038 0.10023078 0.70188545 0.36727079 0.72010558 0.50181872
|
|
0.38453411 0.35044775 0.3798722 0.83573883 0.23181549 0.20136429]
|
|
|
|
...
|
|
|
|
[0.52103744 0.0226581 0.54598853 0.36373277 0.59375282 0.7920373
|
|
0.70313964 0.73111332 0.68636364 0.60551811 0.35614702 0.12046941
|
|
0.3690336 0.27381126 0.15929565 0.35139844 0.13568182 0.30062512
|
|
0.31164518 0.18304244 0.62077552 0.14152452 0.66831017 0.45069799
|
|
0.60113584 0.61929156 0.56861022 0.91202749 0.59846245 0.41886396]
|
|
|
|
[0.32367836 0.49983091 0.33542948 0.1918982 0.57389185 0.45616833
|
|
0.31794752 0.33593439 0.61363636 0.47198821 0.13166757 0.25808876
|
|
0.10446214 0.06023183 0.27082979 0.27268904 0.08777778 0.30611858
|
|
0.23158102 0.21074997 0.28744219 0.5575693 0.27685642 0.14815179
|
|
0.71471967 0.35830641 0.27004792 0.52268041 0.41119653 0.41492851]]
|
|
|
|
test.shape: (21, 30)
|
|
|
|
|
|
---
|
|
### 3. Создание и обучение автокодировщика
|
|
**V1**
|
|
```python
|
|
from time import time
|
|
|
|
patience = 6500
|
|
start = time()
|
|
ae3_v1_trained, IRE3_v1, IREth3_v1 = lib.create_fit_save_ae(train,'out/AE3_V1.h5','out/AE3_v1_ire_th.txt',
|
|
60000, False, patience, early_stopping_delta = 0.001)
|
|
print("Время на обучение: ", time() - start)
|
|
```
|
|
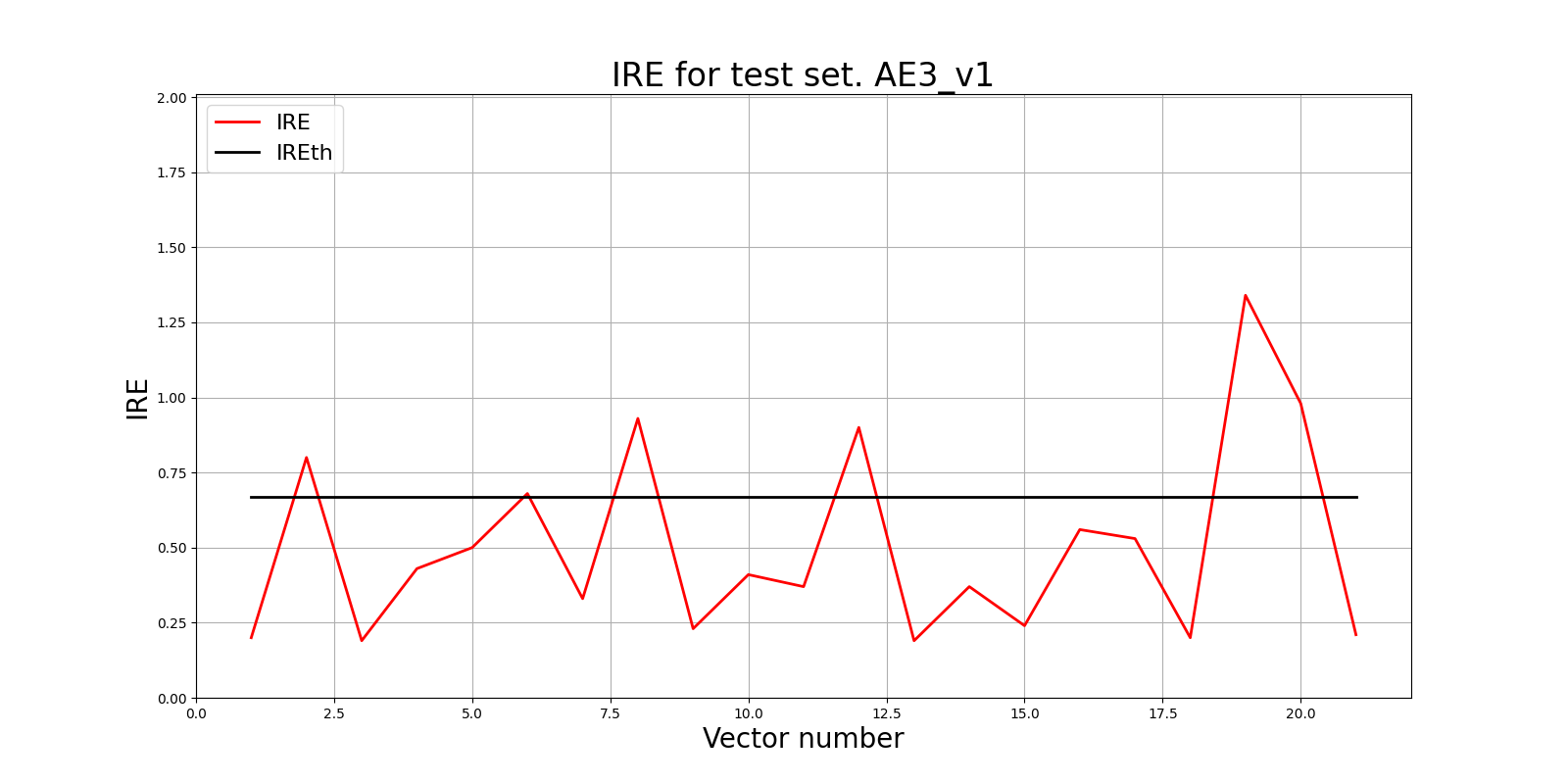
Параметры: 11 скрытых слоёв; 53 47 43 35 27 13 27 35 43 47 53)
|
|
```python
|
|
predicted_labels3_v1, ire3_v1 = lib.predict_ae(ae3_v1_trained, test, IREth3_v1)
|
|
```
|
|
```python
|
|
lib.ire_plot('test', ire3_v1, IREth3_v1, 'AE3_v1')
|
|
```
|
|
|
|
|
|
|
|
|
|
```python
|
|
lib.anomaly_detection_ae(predicted_labels3_v1, IRE3_v1, IREth3_v1)
|
|
```
|
|
<table>
|
|
<thead>
|
|
<tr>
|
|
<th>i</th>
|
|
<th>labels</th>
|
|
<th>IRE</th>
|
|
<th>IREth</th>
|
|
</tr>
|
|
</thead>
|
|
<tbody>
|
|
<tr>
|
|
<td>0</td>
|
|
<td>[0.]</td>
|
|
<td>[0.09]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>1</td>
|
|
<td>[1.]</td>
|
|
<td>[0.14]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>2</td>
|
|
<td>[0.]</td>
|
|
<td>[0.14]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>3</td>
|
|
<td>[0.]</td>
|
|
<td>[0.21]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>4</td>
|
|
<td>[1.]</td>
|
|
<td>[0.11]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>5</td>
|
|
<td>[1.]</td>
|
|
<td>[0.18]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>6</td>
|
|
<td>[1.]</td>
|
|
<td>[0.13]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>7</td>
|
|
<td>[1.]</td>
|
|
<td>[0.14]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>8</td>
|
|
<td>[1.]</td>
|
|
<td>[0.11]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>9</td>
|
|
<td>[1.]</td>
|
|
<td>[0.1]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>10</td>
|
|
<td>[1.]</td>
|
|
<td>[0.14]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>11</td>
|
|
<td>[1.]</td>
|
|
<td>[0.15]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>12</td>
|
|
<td>[1.]</td>
|
|
<td>[0.19]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>13</td>
|
|
<td>[1.]</td>
|
|
<td>[0.15]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>14</td>
|
|
<td>[1.]</td>
|
|
<td>[0.19]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>15</td>
|
|
<td>[1.]</td>
|
|
<td>[0.21]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>16</td>
|
|
<td>[1.]</td>
|
|
<td>[0.09]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>17</td>
|
|
<td>[1.]</td>
|
|
<td>[0.13]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>18</td>
|
|
<td>[1.]</td>
|
|
<td>[0.55]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>19</td>
|
|
<td>[1.]</td>
|
|
<td>[0.16]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
<tr>
|
|
<td>20</td>
|
|
<td>[1.]</td>
|
|
<td>[1.38]</td>
|
|
<td>0.67</td>
|
|
</tr>
|
|
</tbody>
|
|
</table>
|
|
|
|
Обнаружено 6.0 аномалий
|
|
|
|
|
|
**V2**
|
|
```python
|
|
from time import time
|
|
patience = 5000
|
|
start = time()
|
|
ae3_v2_trained, IRE3_v2, IREth3_v2 = lib.create_fit_save_ae(train,'out/AE3_V2.h5','out/AE3_v2_ire_th.txt',
|
|
50000, False, patience, early_stopping_delta = 0.001)
|
|
print("Время на обучение: ", time() - start)
|
|
```
|
|
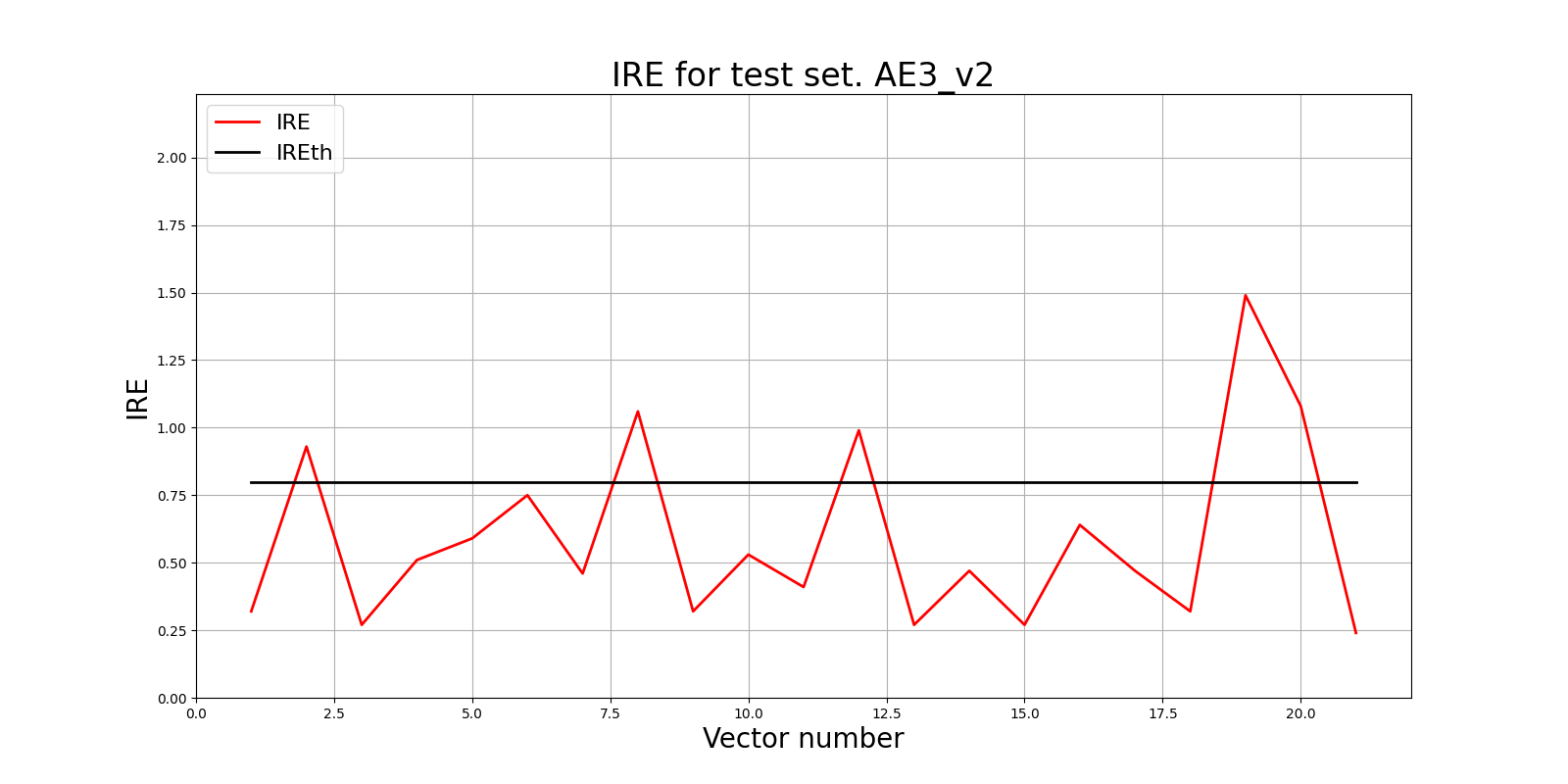
Параметры: 9 скрытых слоёв; 37 29 21 15 7 15 21 29 37)
|
|
```python
|
|
predicted_labels3_v2, ire3_v2 = lib.predict_ae(ae3_v2_trained, test, IREth3_v2)
|
|
```
|
|
```python
|
|
lib.ire_plot('test', ire3_v2, IREth3_v2, 'AE3_v2')
|
|
```
|
|
|
|
|
|
|
|
|
|
```python
|
|
lib.anomaly_detection_ae(predicted_labels3_v2, IRE3_v2, IREth3_v2)
|
|
```
|
|
<table>
|
|
<thead>
|
|
<tr>
|
|
<th>i</th>
|
|
<th>labels</th>
|
|
<th>IRE</th>
|
|
<th>IREth</th>
|
|
</tr>
|
|
</thead>
|
|
<tbody>
|
|
<tr>
|
|
<td>0</td>
|
|
<td>[0.]</td>
|
|
<td>[0.2]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>1</td>
|
|
<td>[1.]</td>
|
|
<td>[0.22]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>2</td>
|
|
<td>[0.]</td>
|
|
<td>[0.16]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>3</td>
|
|
<td>[0.]</td>
|
|
<td>[0.3]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>4</td>
|
|
<td>[0.]</td>
|
|
<td>[0.13]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>5</td>
|
|
<td>[0.]</td>
|
|
<td>[0.2]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>6</td>
|
|
<td>[0.]</td>
|
|
<td>[0.17]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>7</td>
|
|
<td>[1.]</td>
|
|
<td>[0.15]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>8</td>
|
|
<td>[0.]</td>
|
|
<td>[0.14]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>9</td>
|
|
<td>[0.]</td>
|
|
<td>[0.15]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>10</td>
|
|
<td>[0.]</td>
|
|
<td>[0.17]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>11</td>
|
|
<td>[1.]</td>
|
|
<td>[0.14]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>12</td>
|
|
<td>[0.]</td>
|
|
<td>[0.22]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>13</td>
|
|
<td>[0.]</td>
|
|
<td>[0.25]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>14</td>
|
|
<td>[0.]</td>
|
|
<td>[0.24]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>15</td>
|
|
<td>[0.]</td>
|
|
<td>[0.29]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>16</td>
|
|
<td>[0.]</td>
|
|
<td>[0.09]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>17</td>
|
|
<td>[0.]</td>
|
|
<td>[0.21]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>18</td>
|
|
<td>[1.]</td>
|
|
<td>[0.69]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>19</td>
|
|
<td>[1.]</td>
|
|
<td>[0.16]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td>20</td>
|
|
<td>[0.]</td>
|
|
<td>[0.56]</td>
|
|
<td>0.8</td>
|
|
</tr>
|
|
</tbody>
|
|
</table>
|
|
|
|
Обнаружено 5.0 аномалий
|
|
|
|
|
|
**V3**
|
|
```python
|
|
from time import time
|
|
patience = 5500
|
|
start = time()
|
|
ae3_v3_trained, IRE3_v3, IREth3_v3 = lib.create_fit_save_ae(train,'out/AE3_V3.h5','out/AE3_v3_ire_th.txt',
|
|
50000, False, patience, early_stopping_delta = 0.0001)
|
|
print("Время на обучение: ", time() - start)
|
|
```
|
|
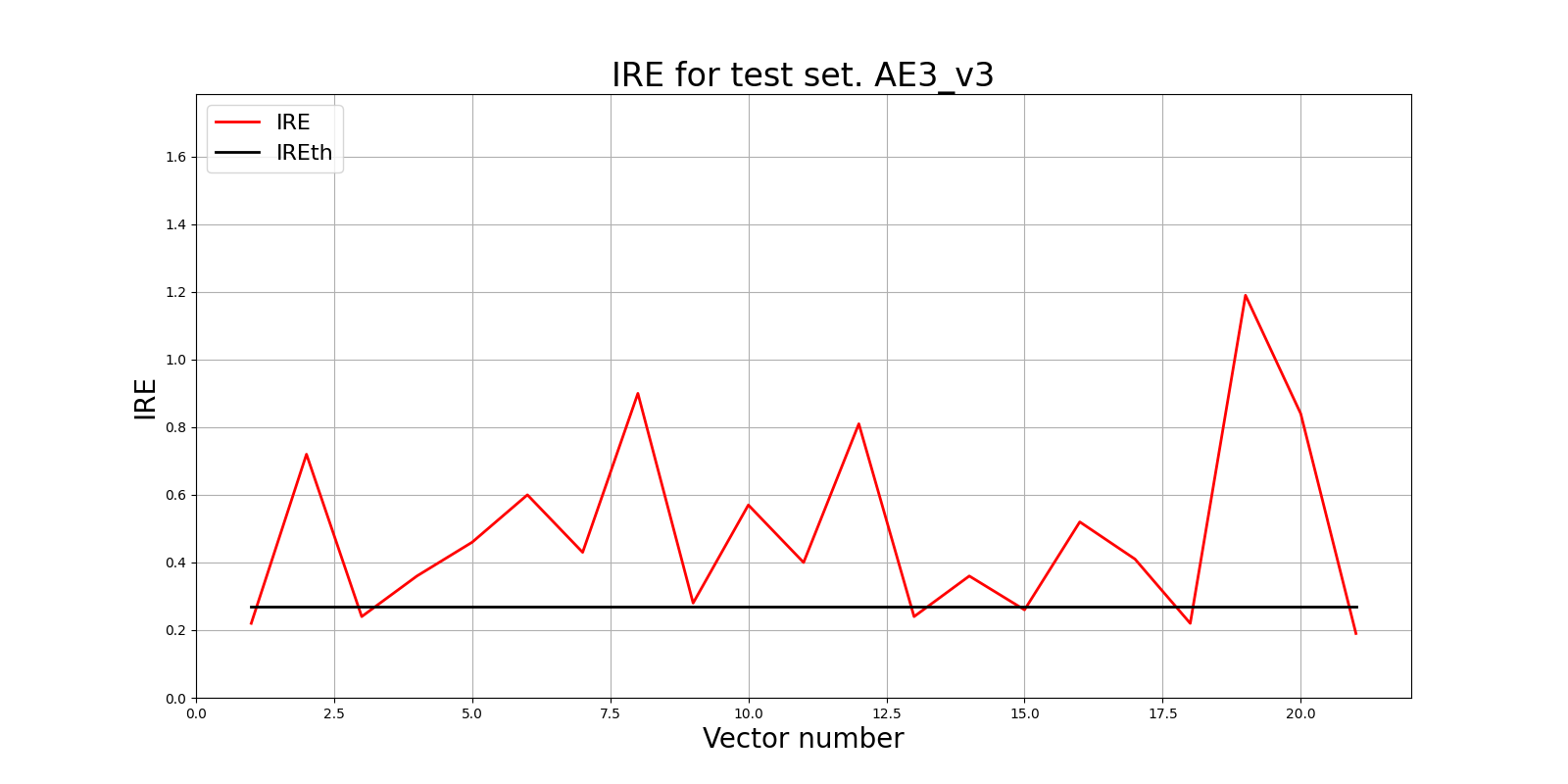
Параметры: 9 скрытых слоёв; 30 25 20 15 7 15 20 25 30)
|
|
|
|
```python
|
|
predicted_labels3_v3, ire3_v3 = lib.predict_ae(ae3_v3_trained, test, IREth3_v3)
|
|
```
|
|
|
|
```python
|
|
lib.ire_plot('test', ire3_v3, IREth3_v3, 'AE3_v3')
|
|
```
|
|
|
|
|
|
|
|
```python
|
|
lib.anomaly_detection_ae(predicted_labels3_v3, IRE3_v3, IREth3_v3)
|
|
```
|
|
|
|
<table>
|
|
<thead>
|
|
<tr>
|
|
<th>i</th>
|
|
<th>labels</th>
|
|
<th>IRE</th>
|
|
<th>IREth</th>
|
|
</tr>
|
|
</thead>
|
|
<tbody>
|
|
<tr>
|
|
<td>0</td>
|
|
<td>[0.]</td>
|
|
<td>[0.08]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>1</td>
|
|
<td>[1.]</td>
|
|
<td>[0.11]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>2</td>
|
|
<td>[0.]</td>
|
|
<td>[0.13]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>3</td>
|
|
<td>[1.]</td>
|
|
<td>[0.17]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>4</td>
|
|
<td>[.]</td>
|
|
<td>[0.13]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>5</td>
|
|
<td>[1.]</td>
|
|
<td>[0.18]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>6</td>
|
|
<td>[1.]</td>
|
|
<td>[0.11]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>7</td>
|
|
<td>[1.]</td>
|
|
<td>[0.12]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>8</td>
|
|
<td>[1.]</td>
|
|
<td>[0.11]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>9</td>
|
|
<td>[1.]</td>
|
|
<td>[0.14]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>10</td>
|
|
<td>[1.]</td>
|
|
<td>[0.17]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>11</td>
|
|
<td>[1.]</td>
|
|
<td>[0.12]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>12</td>
|
|
<td>[0.]</td>
|
|
<td>[0.11]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>13</td>
|
|
<td>[1.]</td>
|
|
<td>[0.09]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>14</td>
|
|
<td>[0.]</td>
|
|
<td>[0.23]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>15</td>
|
|
<td>[1.]</td>
|
|
<td>[0.12]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>16</td>
|
|
<td>[1.]</td>
|
|
<td>[0.1]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>17</td>
|
|
<td>[0.]</td>
|
|
<td>[0.14]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>18</td>
|
|
<td>[1.]</td>
|
|
<td>[0.05]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>19</td>
|
|
<td>[1.]</td>
|
|
<td>[0.12]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
<tr>
|
|
<td>20</td>
|
|
<td>[0.]</td>
|
|
<td>[0.1]</td>
|
|
<td>0.27</td>
|
|
</tr>
|
|
</tbody>
|
|
</table>
|
|
|
|
Обнаружено 15.0 аномалий
|
|
|
|
### 4. Результаты
|
|
Лучшим автокодировщиком среди представленных, является AE3_V3, т.к. у него точность обнаружения аномалий наиболее высокая - 71.43%
|
|
<table>
|
|
<thead>
|
|
<tr>
|
|
<th>Dataset Name</th>
|
|
<th>Количество скрытых слоёв</th>
|
|
<th>Количество нейронов в скрытых слоях</th>
|
|
<th>Количество эпох обучения</th>
|
|
<th>Ошибка MSE_stop</th>
|
|
<th>Порог ошибки реконструкции</th>
|
|
<th>Процент обнаруженных аномалий</th>
|
|
</tr>
|
|
</thead>
|
|
<tbody>
|
|
<tr>
|
|
<td align="center">WBC</td>
|
|
<td align="center">11</td>
|
|
<td align="center">53 47 43 35 27 13 27 35 43 47 53</td>
|
|
<td align="center">60 000</td>
|
|
<td align="center">0.001</td>
|
|
<td align="center">0.67</td>
|
|
<td align="center">28.57</td>
|
|
</tr>
|
|
<tr>
|
|
<td align="center">WBC</td>
|
|
<td align="center">9</td>
|
|
<td align="center">37 29 21 15 7 15 21 29 37</td>
|
|
<td align="center">50 000</td>
|
|
<td align="center">0.0007</td>
|
|
<td align="center">0.8</td>
|
|
<td align="center">23.8</td>
|
|
</tr>
|
|
<tr>
|
|
<td align="center">WBC</td>
|
|
<td align="center">9</td>
|
|
<td align="center">30 25 20 15 7 15 20 25 30</td>
|
|
<td align="center">50 000</td>
|
|
<td align="center">0.0005</td>
|
|
<td align="center">0.27</td>
|
|
<td align="center">71.43</td>
|
|
</tr>
|
|
</tbody>
|
|
</table>
|
|
|
|
|
|
### ВЫВОДЫ
|
|
1) Так как мы работаем с автокодировщиком, данные для его обучения должны быть без аномалий: автокодировщик должен суметь рассчитать верное пороговое значение.
|
|
2) Архитектура автокодировщика представляет из себя многослойную архитектуру с сужением в середине, а также совпадающее количество входов и выходов
|
|
|
|
В первой части работы:
|
|
|
|
Оптимальным количеством скрытых слоев для нашего автокодировщика будет 5. Лучшие результаты показываются при количестве эпох - 3000 с patience в 100 эпох
|
|
1) Оптимальная ошибка MSE-stop должна быть в районе 0.01, в идеале не меньше - для предотвращения переобучения. В этой работе она равна 0.0094
|
|
2) Значение порога ошибки реконструкции приблизительно равно 0.38
|
|
3) Значение Excess равно 0.631 (стремится к 0), значение Approx равно 0.612 (стремится к 1), количество определенных аномалий - 4, - эти результаты лучше, чем при более простой архитектуре
|
|
|
|
Во второй части работы:
|
|
Сравнив разные архитектуры при работе с выборкой WBC, делаем выводы,что при неизменном количестве эпох наилучший результат показывает автокодировщик с наименьшими ошибкой MSE, порогом ошибки реконструкции и колчиеством нейронов в скрытом слое. Причинами таких результатов являются:
|
|
1) При слишком высоком пороге ошибки реконструкции часть ошибок "ускользает" от автокодировщика, он не распознаёт аномалии с малой ошибкой - модель стала "консервативной"
|
|
2) При большой ошибке MSE - модель недостаточно хорошо выучила нормальные данные
|
|
3) При слишком большом количестве нейронов модель становится слишком сложной, она "зазубривает" данные, а не учится распознавать закономерности |