22 KiB
Отчёт по лабораторной работе №2
Ли Тэ Хо, Синявский Степан — А-02-22
Задание 1
1) В среде Google Colab создали новый блокнот (notebook). Импортировали необходимые для работы библиотеки и модули.
# импорт модулей
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab2')
import numpy as np
import lab02_lib as lib
2) Сгенерировали индивидуальный набор двумерных данных в пространстве признаков с координатами центра 3, 3), где 3 – номер бригады. Вывели полученные данные на рисунок и в консоль.
# генерация датасета
data = lib.datagen(3, 3, 1000, 2)
# вывод данных и размерности
print('Исходные данные:')
print(data)
print('Размерность данных:')
print(data.shape)

Исходные данные:
[[3.01497028 2.9872143 ]
[2.95216438 2.93247766]
[2.9281138 2.80160426]
...
[3.10976374 2.91251936]
[3.16677716 2.95397464]
[3.00503898 3.17135038]]
Размерность данных:
(1000, 2)
3) Создали и обучили автокодировщик AE1 простой архитектуры, выбрав небольшое количество эпох обучения. Зафиксировали в таблице вида табл.1 количество скрытых слоёв и нейронов в них
# обучение AE1
patience = 300
ae1_trained, IRE1, IREth1 = lib.create_fit_save_ae(data,'out/AE1.h5','out/AE1_ire_th.txt',
1000, True, patience)
4) Зафиксировали ошибку MSE, на которой обучение завершилось. Построили график ошибки реконструкции обучающей выборки. Зафиксировали порог ошибки реконструкции – порог обнаружения аномалий.
Ошибка MSE_AE1 = 1.4393
# Построение графика ошибки реконструкции
lib.ire_plot('training', IRE1, IREth1, 'AE1')

5) Создали и обучили второй автокодировщик AE2 с усложненной архитектурой, задав большее количество эпох обучения
# обучение AE2
ae2_trained, IRE2, IREth2 = lib.create_fit_save_ae(data,'out/AE2.h5','out/AE2_ire_th.txt',
3000, True, patience)
6) Зафиксировали ошибку MSE, на которой обучение завершилось. Построили график ошибки реконструкции обучающей выборки. Зафиксировали второй порог ошибки реконструкции – порог обнаружения аномалий.
Ошибка MSE_AE2 = 0.0102
# Построение графика ошибки реконструкции
lib.ire_plot('training', IRE2, IREth2, 'AE2')

7) Рассчитали характеристики качества обучения EDCA для AE1 и AE2. Визуализировали и сравнили области пространства признаков, распознаваемые автокодировщиками AE1 и AE2. Сделали вывод о пригодности AE1 и AE2 для качественного обнаружения аномалий.
# построение областей покрытия и границ классов
# расчет характеристик качества обучения
numb_square = 20
xx, yy, Z1 = lib.square_calc(numb_square, data, ae1_trained, IREth1, '1', True)

amount: 21
amount_ae: 226


Оценка качества AE1
IDEAL = 0. Excess: 9.761904761904763
IDEAL = 0. Deficit: 0.0
IDEAL = 1. Coating: 1.0
summa: 1.0
IDEAL = 1. Extrapolation precision (Approx): 0.09292035398230088
# построение областей покрытия и границ классов
# расчет характеристик качества обучения
numb_square = 20
xx, yy, Z2 = lib.square_calc(numb_square, data, ae2_trained, IREth2, '2', True)
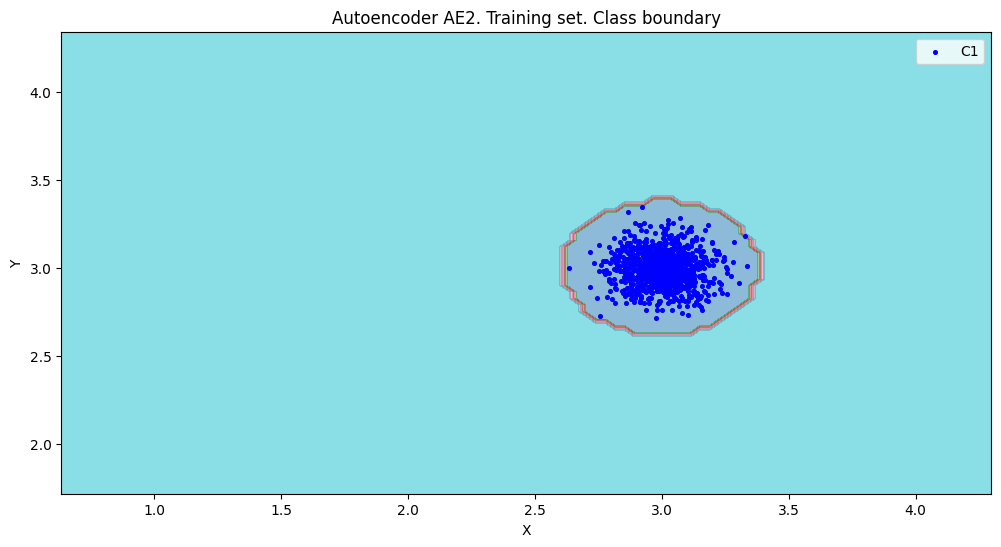
amount: 21
amount_ae: 26


Оценка качества AE2
IDEAL = 0. Excess: 0.23809523809523808
IDEAL = 0. Deficit: 0.0
IDEAL = 1. Coating: 1.0
summa: 1.0
IDEAL = 1. Extrapolation precision (Approx): 0.8076923076923076
# сравнение характеристик качества обучения и областей аппроксимации
lib.plot2in1(data, xx, yy, Z1, Z2)

8) Если автокодировщик AE2 недостаточно точно аппроксимирует область обучающих данных, то подобрать подходящие параметры автокодировщика и повторить шаги (6) – (8).
Полученные показатели EDCA для автокодировщика AE2 нас устраивают.
9) Изучили сохраненный набор данных и пространство признаков. Создали тестовую выборку, состоящую, как минимум, из 4ёх элементов, не входящих в обучающую выборку. Элементы должны быть такими, чтобы AE1 распознавал их как норму, а AE2 детектировал как аномалии.
# загрузка тестового набора
data_test = np.loadtxt('data_test.txt', dtype=float)
print(data_test)
[[2.72 2.72]
[3.28 2.71]
[2.7 3.29]
[3.3 3.27]]
10) Применили обученные автокодировщики AE1 и AE2 к тестовым данным и вывели значения ошибки реконструкции для каждого элемента тестовой выборки относительно порога на график и в консоль.
# тестирование АE1
predicted_labels1, ire1 = lib.predict_ae(ae1_trained, data_test, IREth1)
# тестирование АE1
lib.anomaly_detection_ae(predicted_labels1, ire1, IREth1)
lib.ire_plot('test', ire1, IREth1, 'AE1')
i Labels IRE IREth
0 [0.] [1.33] 2.0
1 [0.] [1.59] 2.0
2 [0.] [1.87] 2.0
3 [1.] [2.07] 2.0
Обнаружено 1.0 аномалий

# тестирование АE2
predicted_labels2, ire2 = lib.predict_ae(ae2_trained, data_test, IREth2)
# тестирование АE2
lib.anomaly_detection_ae(predicted_labels2, ire2, IREth2)
lib.ire_plot('test', ire2, IREth2, 'AE2')
i Labels IRE IREth
0 [1.] [0.39] 0.38
1 [1.] [0.4] 0.38
2 [1.] [0.42] 0.38
3 [1.] [0.41] 0.38
Обнаружено 4.0 аномалий

11) Визуализировали элементы обучающей и тестовой выборки в областях пространства признаков, распознаваемых автокодировщиками AE1 и AE2.
# построение областей аппроксимации и точек тестового набора
lib.plot2in1_anomaly(data, xx, yy, Z1, Z2, data_test)
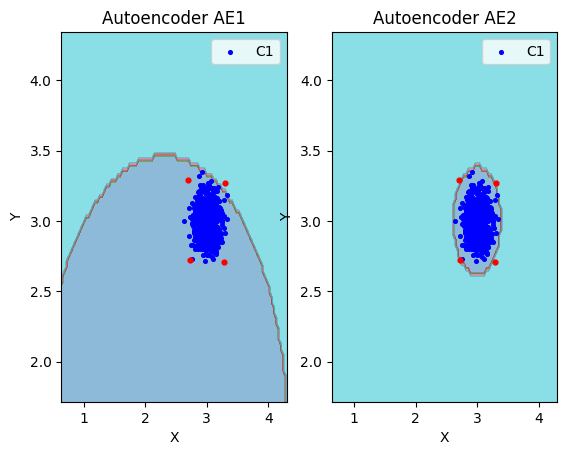
12) Результаты исследования занесли в таблицу:
Табл. 1 Результаты задания №1
| Количество скрытых слоев |
Количество нейронов в скрытых слоях |
Количество эпох обучения |
Ошибка MSE_stop |
Порог ошибки реконструкции |
Значение показателя Excess |
Значение показателя Approx |
Количество обнаруженных аномалий |
|
|---|---|---|---|---|---|---|---|---|
| AE1 | 1 | 1 | 1000 | 1.4393 | 2 | 9.76 | 0.0929 | 1 |
| AE2 | 5 | 3,2,1,2,3 | 3000 | 0.0108 | 0.38 | 0.238 | 0.80 | 4 |
13) Сделаем выводы о требованиях к:
- данным для обучения,
- архитектуре автокодировщика,
- количеству эпох обучения,
- ошибке MSE_stop, приемлемой для останова обучения,
- ошибке реконструкции обучающей выборки (порогу обнаружения аномалий),
- характеристикам качества обучения EDCA одноклассового классификатора для качественного обнаружения аномалий в данных.
- Для качественного обнаружения аномалий обучающая выборка должна содержать только нормальные данные и быть однородной.
- Архитектура должна быть достаточно сложной, чтобы адекватно аппроксимировать форму области нормальных данных. Слишком простые сети (как AE1) даже на тех же данных дают огромное превышение области и практически не описывают реальную структуру выборки.
- Количество эпох для качественного обучения сети должно быть около 3000, это обеспечит более качественную реконструкцию.
- Значение MSE_stop должно быть умеренным — не слишком большим, чтобы избежать недообучения, и не слишком маленьким, чтобы избежать переобучения. AE2 с MSE_stop ≈ 0.01 показывает оптимальное качество.
- Порог должен быть максимально низким и стабильным, чтобы корректно отделять нормальные объекты от аномальных. Значение порога в районе 0.38.
- Значение Excess не больше 0.4, значение Deficit равное 0, значение Coating равное 1, значение Approx не меньше 0.75
Задание 2
1) Изучить описание своего набора реальных данных, что он из себя представляет
Бригада 3 => набор данных Cardio. Это реальный набор данных, который состоит из измерений частоты сердечных сокращений плода и сокращений матки на кардиотокограммах, классифицированных экспертами акушерами. Исходный набор данных предназначен для классификации. В нем представлено 3 класса: «норма», «подозрение» и «патология». Для обнаружения аномалий класс «норма» принимается за норму, класс «патология» принимается за аномалии, а класс «подозрение» был отброшен.
| Количество признаков |
Количество примеров |
Количество нормальных примеров |
Количество аномальных примеров |
|---|---|---|---|
| 21 | 1764 | 1655 | 109 |
2) Загрузить многомерную обучающую выборку реальных данных Cardio.txt.
# загрузка обчуающей выборки
train = np.loadtxt('cardio_train.txt', dtype=float)
3) Вывести полученные данные и их размерность в консоли.
print('train:\n', train)
print('train.shape:', np.shape(train))
train:
[[ 0.00491231 0.69319077 -0.20364049 ... 0.23149795 -0.28978574
-0.49329397]
[ 0.11072935 -0.07990259 -0.20364049 ... 0.09356344 -0.25638541
-0.49329397]
[ 0.21654639 -0.27244466 -0.20364049 ... 0.02459619 -0.25638541
1.1400175 ]
...
[ 0.85144861 -0.91998844 -0.20364049 ... 0.57633422 -0.65718941
1.1400175 ]
[ 0.85144861 -0.91998844 -0.20364049 ... 0.57633422 -0.62378908
-0.49329397]
[ 1.0630827 -0.51148142 -0.16958144 ... 0.57633422 -0.65718941
-0.49329397]]
train.shape: (1654, 21)
4) Создать и обучить автокодировщик с подходящей для данных архитектурой. Выбрать необходимое количество эпох обучения.
# **kwargs
# verbose_every_n_epochs - отображать прогресс каждые N эпох (по умолчанию - 1000)
# early_stopping_delta - дельта для ранней остановки (по умолчанию - 0.01)
# early_stopping_value = значение для ранней остановки (по умолчанию - 0.0001)
from time import time
patience = 4000
start = time()
ae3_v1_trained, IRE3_v1, IREth3_v1 = lib.create_fit_save_ae(train,'out/AE3_V1.h5','out/AE3_v1_ire_th.txt',
100000, False, patience, verbose_every_n_epochs = 1000, early_stopping_delta = 0.001)
print("Время на обучение: ", time() - start)
5) Зафиксировать ошибку MSE, на которой обучение завершилось. Построить график ошибки реконструкции обучающей выборки. Зафиксировать порог ошибки реконструкции – порог обнаружения аномалий.
Скрытых слоев 7, нейроны: 48->36->24->12->24->36->48
Ошибка MSE_AE3_v1 = 0.0073
# Построение графика ошибки реконструкции
lib.ire_plot('training', IRE3_v1, IREth3_v1, 'AE3_v1')

6) Сделать вывод о пригодности обученного автокодировщика для качественного обнаружения аномалий. Если порог ошибки реконструкции слишком велик, то подобрать подходящие параметры автокодировщика и повторить шаги (4) – (6).
# **kwargs
# verbose_every_n_epochs - отображать прогресс каждые N эпох (по умолчанию - 1000)
# early_stopping_delta - дельта для ранней остановки (по умолчанию - 0.01)
# early_stopping_value = значение для ранней остановки (по умолчанию - 0.0001)
from time import time
patience = 4000
start = time()
ae3_v2_trained, IRE3_v2, IREth3_v2 = lib.create_fit_save_ae(train,'out/AE3_V2.h5','out/AE3_v2_ire_th.txt',
100000, False, patience, early_stopping_delta = 0.001, verbose_every_n_epochs = 1000)
print("Время на обучение: ", time() - start)
Скрытых слоев 11, нейроны: 48->40->36->30->24->12->24->30->36->40->48
Ошибка MSE_AE3_v1 = 0.0065
# Построение графика ошибки реконструкции
lib.ire_plot('training', IRE3_v2, IREth3_v2, 'AE3_v2')

7) Изучить и загрузить тестовую выборку Cardio.txt.
#загрузка тестовой выборки
test = np.loadtxt('cardio_test.txt', dtype=float)
print('\n test:\n', test)
print('test.shape:', np.shape(test))
test:
[[ 0.21654639 -0.65465178 -0.20364049 ... -2.0444214 4.987467
-0.49329397]
[ 0.21654639 -0.5653379 -0.20364049 ... -2.1133887 6.490482
-0.49329397]
[-0.3125388 -0.91998844 6.9653692 ... -1.1478471 3.9186563
-0.49329397]
...
[-0.41835583 -0.91998844 -0.16463485 ... -1.4926834 0.24461959
-0.49329397]
[-0.41835583 -0.91998844 -0.15093411 ... -1.4237162 0.14441859
-0.49329397]
[-0.41835583 -0.91998844 -0.20364049 ... -1.2857816 3.5846529
-0.49329397]]
test.shape: (109, 21)
8) Подать тестовую выборку на вход обученного автокодировщика для обнаружения аномалий. Вывести график ошибки реконструкции элементов тестовой выборки относительно порога.
# тестирование АE3
predicted_labels3_v1, ire3_v1 = lib.predict_ae(ae3_v1_trained, test, IREth3_v1)
# Построение графика ошибки реконструкции
lib.ire_plot('test', ire3_v1, IREth3_v1, 'AE3_v1')

# тестирование АE3
predicted_labels3_v2, ire3_v2 = lib.predict_ae(ae3_v2_trained, test, IREth3_v2)
# Построение графика ошибки реконструкции
lib.ire_plot('test', ire3_v2, IREth3_v2, 'AE3_v2')

# тестирование АE2
lib.anomaly_detection_ae(predicted_labels3_v1, IRE3_v1, IREth3_v1)
Для AE3_v1 точность составляет 63%
# тестирование АE2
lib.anomaly_detection_ae(predicted_labels3_v2, IRE3_v2, IREth3_v2)
Для AE3_v2 точность составляет 82%
9) Если результаты обнаружения аномалий не удовлетворительные (обнаружено менее 70% аномалий), то подобрать подходящие параметры автокодировщика и повторить шаги (4) – (9).
Результаты обнаружения аномалий удовлетворены.
10) Параметры наилучшего автокодировщика и результаты обнаружения аномалий занести в таблицу:
Табл. 2 Результаты задания №2
| Dataset name | Количество скрытых слоев |
Количество нейронов в скрытых слоях |
Количество эпох обучения |
Ошибка MSE_stop |
Порог ошибки реконструкции |
% обнаруженных аномалий |
|---|---|---|---|---|---|---|
| Cardio | 11 | 48, 40, 36, 30, 24, 12, 24, 30, 36, 40, 48 | 100000 | 0.0065 | 1.4 | 82% |
11) Сделать выводы о требованиях к:
- данным для обучения,
- архитектуре автокодировщика,
- количеству эпох обучения,
- ошибке MSE_stop, приемлемой для останова обучения,
- ошибке реконструкции обучающей выборки (порогу обнаружения аномалий) для качественного обнаружения аномалий в случае, когда размерность пространства признаков высока.
- Данные для обучения должны быть без аномалий, чтобы автокодировщик смог рассчитать верное пороговое значение.
- Большая размерность датасета требует более сложной архитектуры. Оптимальный размер 9-11 скрытых слоев.
- В рамках данного набора данных оптимальное кол-во эпох 100000 с patience 4000 эпох.
- Оптимальная ошибка MSE-stop лежит в районе 0.001, желательно не меньше для предотвращения переобучения
- Значение порога не больше 1.4, он является достаточным, чтобы отделять норму от аномалий.