28 KiB
Отчет по ЛР2
Коновалова Алёна, Ильинцева Любовь, А-01-22
Задание 1
1. Импорт необходимых библиотек и модулей
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab2')
# импорт модулей
import numpy as np
import lab02_lib as lib
2. Генерация индивидуального набора двумерных данных
Сгенерируем индивидуальный набор двумерных данных в пространстве признаков с координатами центра (k, k), где k – номер бригады, равный 8 в нашем случае.
data = lib.datagen(8, 8, 1000, 2)
Вывод:
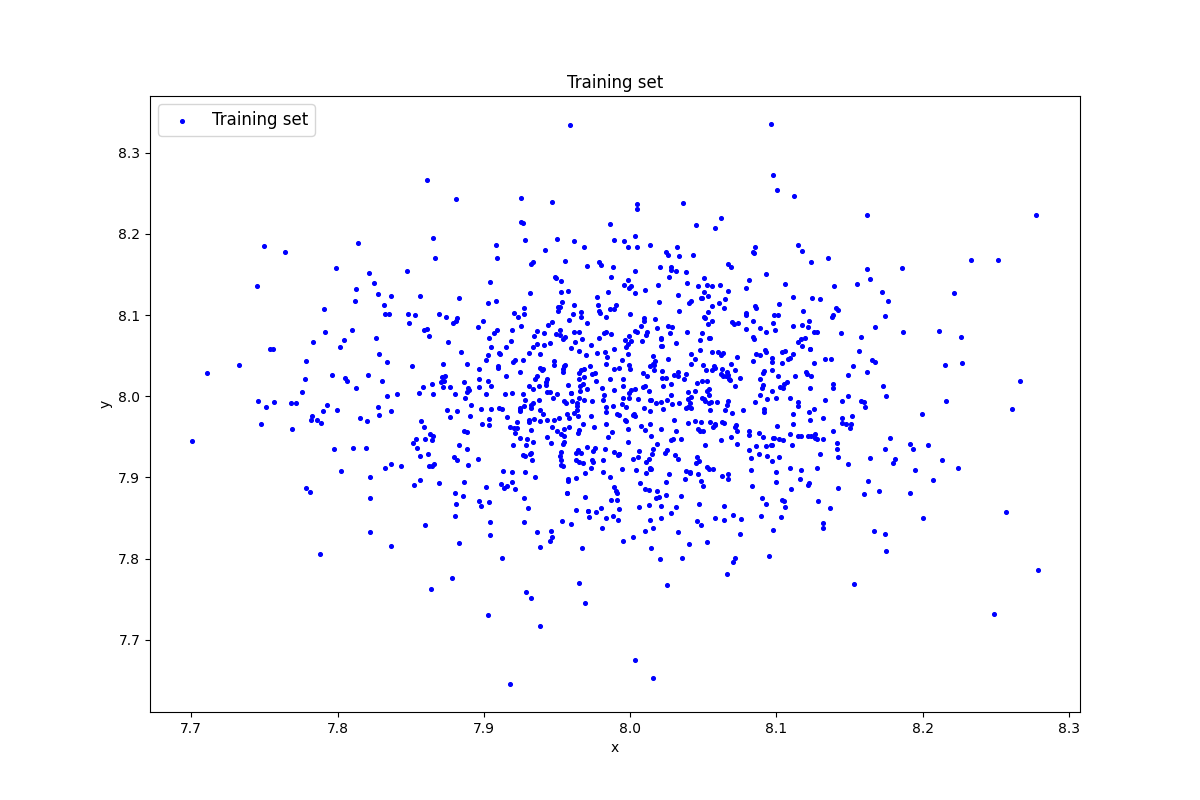
Выведем данные и размерность
print('Исходные данные:')
print(data)
print('Размерность данных:')
print(data.shape)
Вывод:
Исходные данные:
[[8.14457288 7.96648176]
[8.16064924 7.98620341]
[7.93127504 7.92863959]
...
[7.95464881 7.94307035]
[8.01092703 7.90530753]
[7.81962108 7.93563874]]
Размерность данных:
(1000, 2)
3. Создание и обучение автокодировщика АЕ1
Создадим автокодировщик простой архитектуры. Обучим автокодировщик в течение 1000 эпох с параметром patience = 300. Добавим 1 скрытый слой с 5 нейронами, т.к. нам нужно добиться, чтобы MSE_stop была не меньше 1-10.
patience = 300
ae1_trained, IRE1, IREth1 = lib.create_fit_save_ae(data,'out/AE1.h5','out/AE1_ire_th.txt', 1000, True, patience)
Вывод:
...
Epoch 1000/1000 - loss: 3.7394
Ошибка MSE_stop равна 3.7394, что является удовлетворительным.
Пороговое значение ошибки реконструкции IREth1 - 3.07
4. Построение графика ошибки реконструкции для AE1
lib.ire_plot('training', IRE1, IREth1, 'AE1')
Вывод:
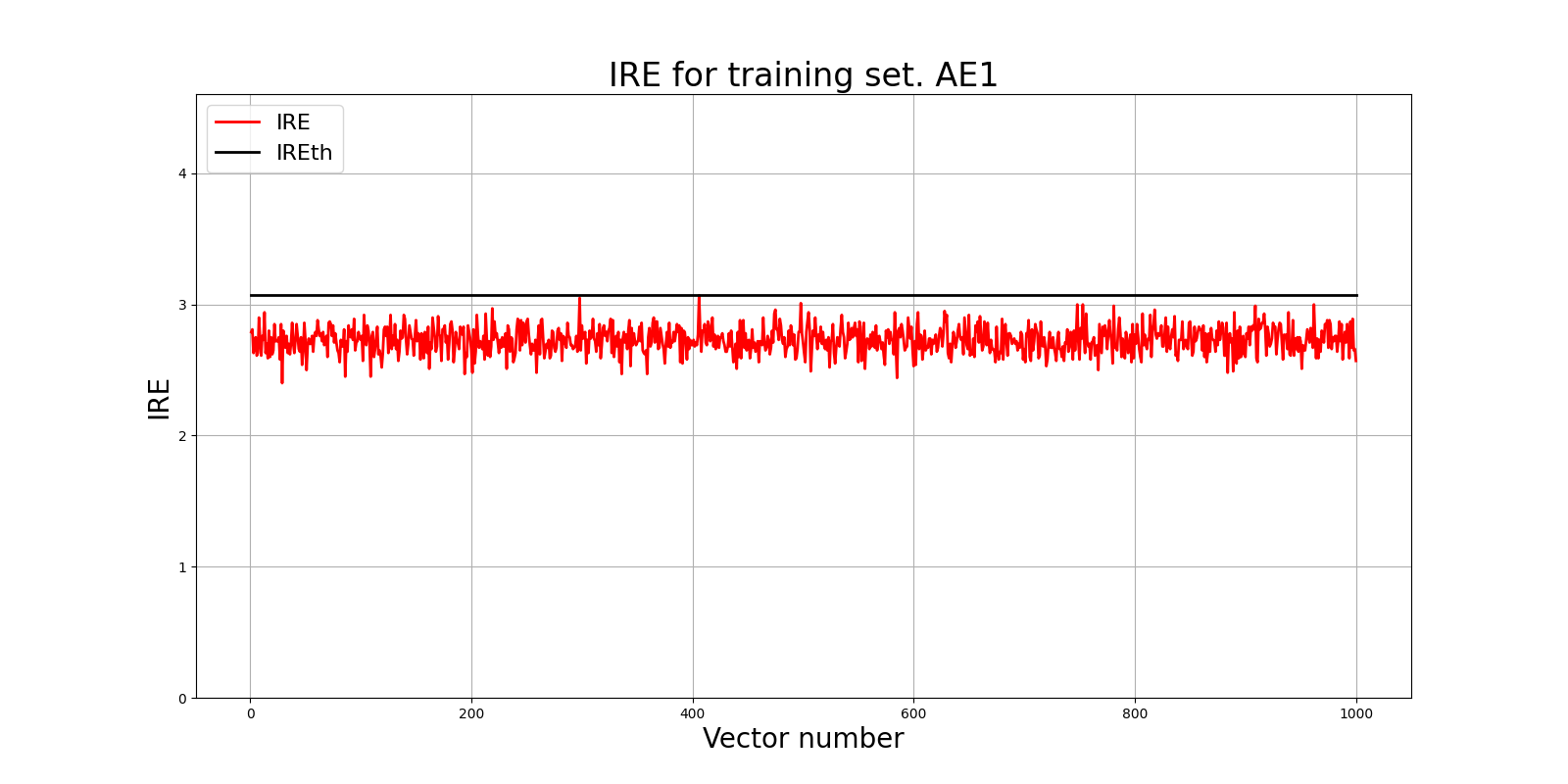
Из графика видим, что нейросеть обучена оптимально и порог обнаружения аномалий адекватно описывает границу области генеральной совокупности исследуемых данных.
5. Создание и обучение автокодировщика АЕ1
Создадим автокодировщик с более сложной архитектурой. Будем обучать в течение 2700 эпох с параметром patience = 500. Добавим 5 скрытых слоев с архитектурой 4-3-2-3-4 нейронов на каждом слое. В случае с автокодировщиком АЕ2 нам нужно добиться ошибки MSE_stop не меньше 0.01.
patience = 500
ae2_trained, IRE2, IREth2 = lib.create_fit_save_ae(data,'out/AE2.h5','out/AE2_ire_th.txt', 2700, True, patience)
Вывод:
...
Epoch 2700/2700 - loss: 0.0114
Ошибка MSE_stop равна 0.0114, мы сумели достичь результата, близкого к идеалу.
Пороговое значение ошибки реконструкции IREth2 - 0.4
6. Построение графика ошибки реконструкции для AE2
lib.ire_plot('training', IRE2, IREth2, 'AE2')
Вывод:
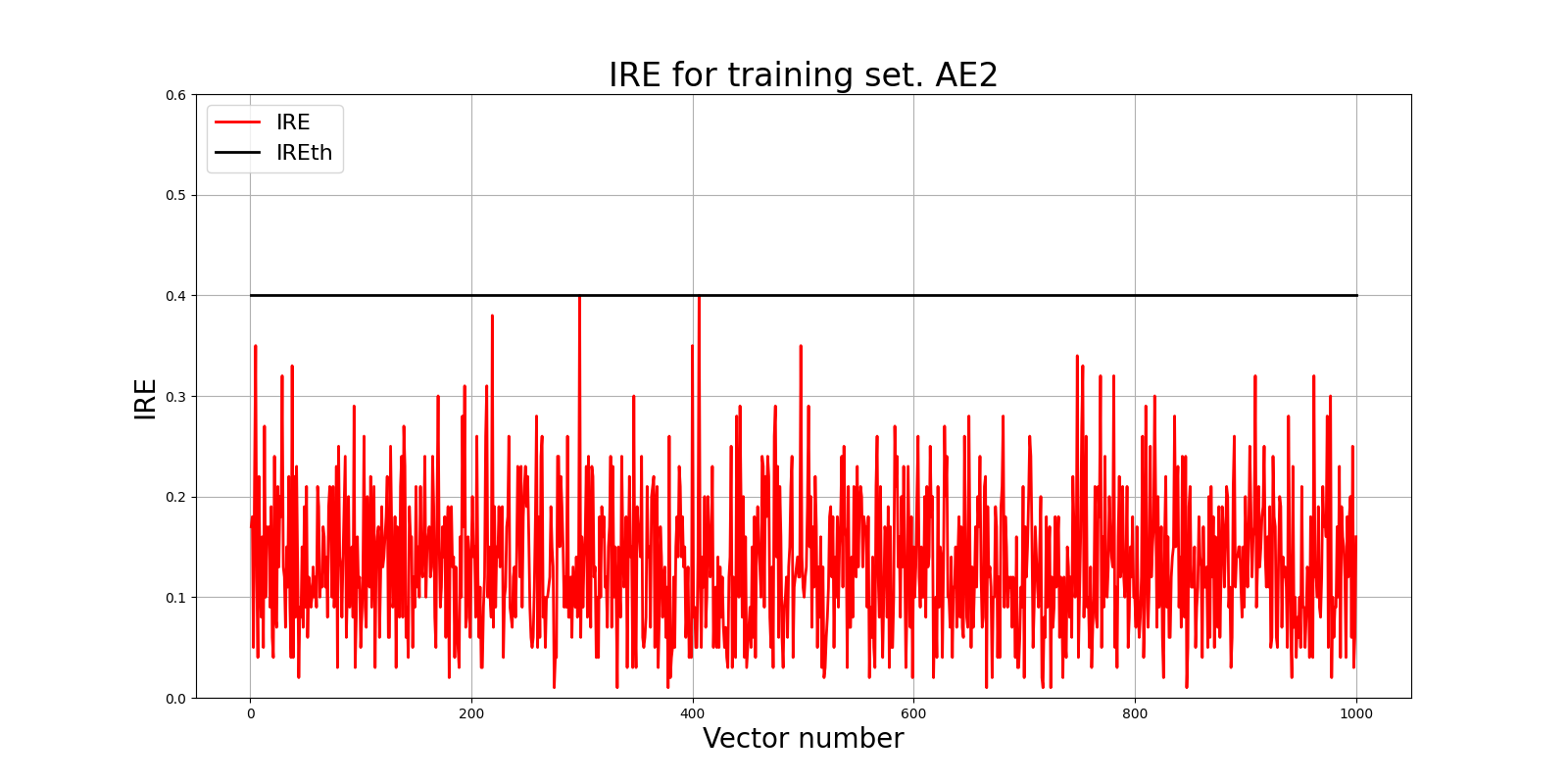
Из графика также видим, что нейросеть обучена хорошо и порог обнаружения аномалий не завышен относительно средних значений ошибки.
7. Расчет характеристик качества обучения EDCA
Рассчитаем характеристики для АЕ1 и АЕ2. Визуализируем области пространства признаков, распознаваемые автокодировщиками АЕ1 и АЕ2.
7.1. AE1
numb_square = 20
xx, yy, Z1 = lib.square_calc(numb_square, data, ae1_trained, IREth1, '1', True)
Вывод:
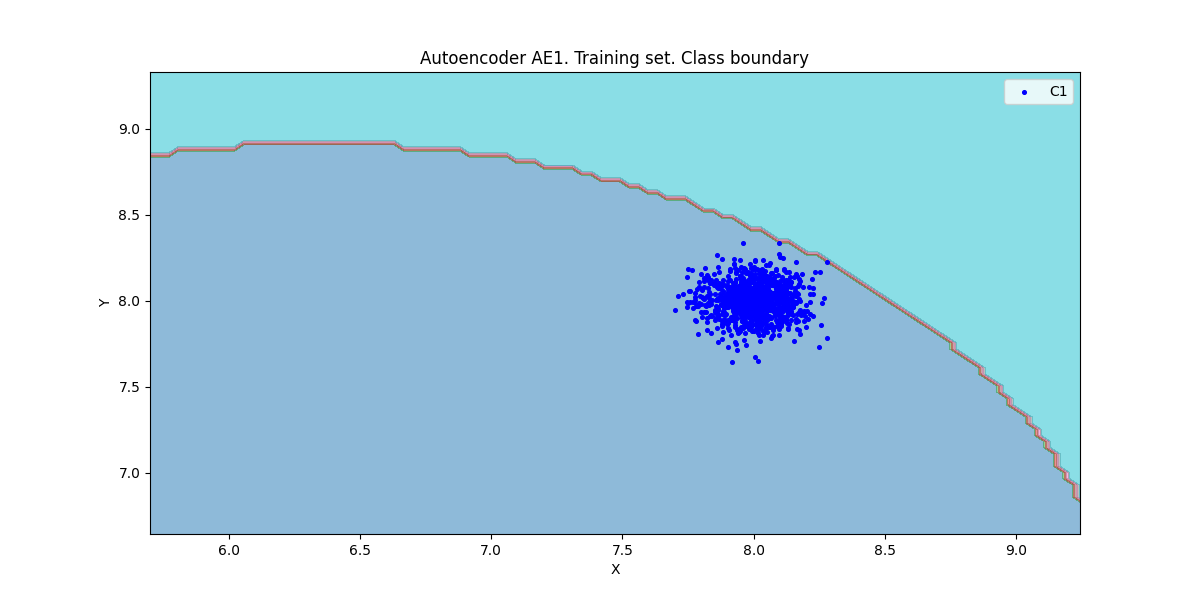
amount: 19
amount_ae: 280

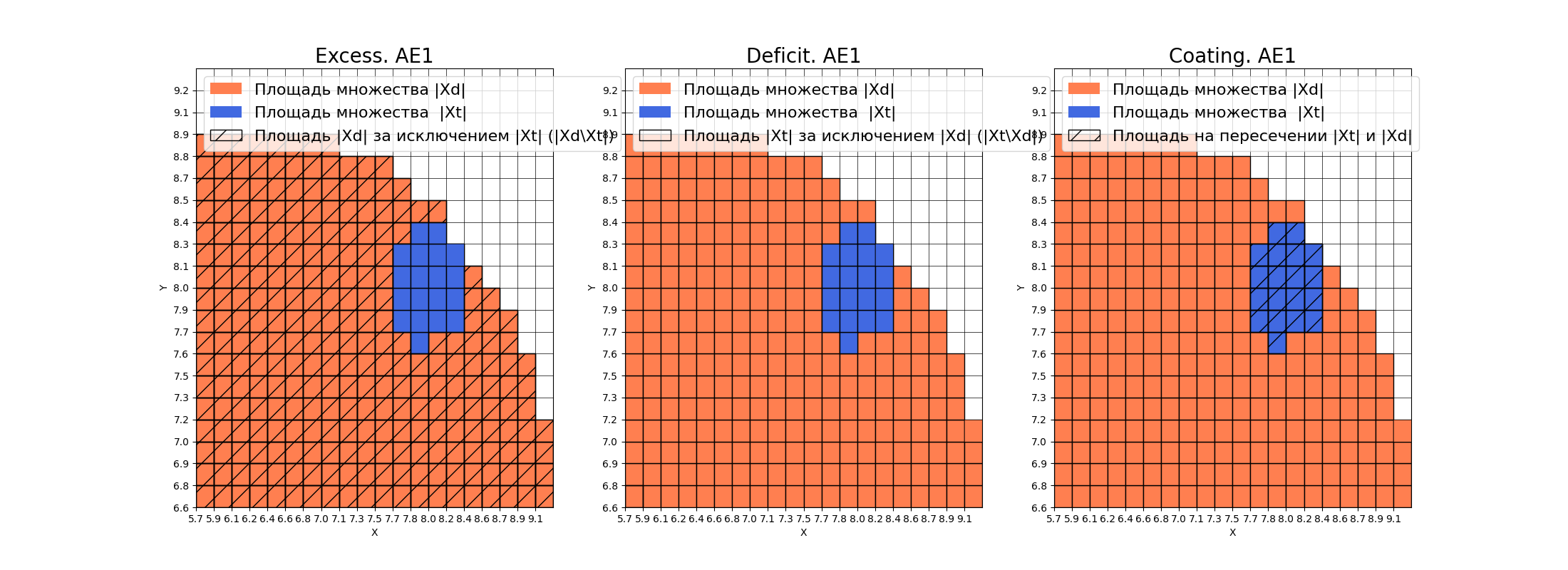
Оценка качества AE1
IDEAL = 0. Excess: 13.736842105263158
IDEAL = 0. Deficit: 0.0
IDEAL = 1. Coating: 1.0
summa: 1.0
IDEAL = 1. Extrapolation precision (Approx): 0.06785714285714287
7.2. AE2
numb_square = 20
xx, yy, Z2 = lib.square_calc(numb_square, data, ae2_trained, IREth2, '2', True)
Вывод:

amount: 19
amount_ae: 30
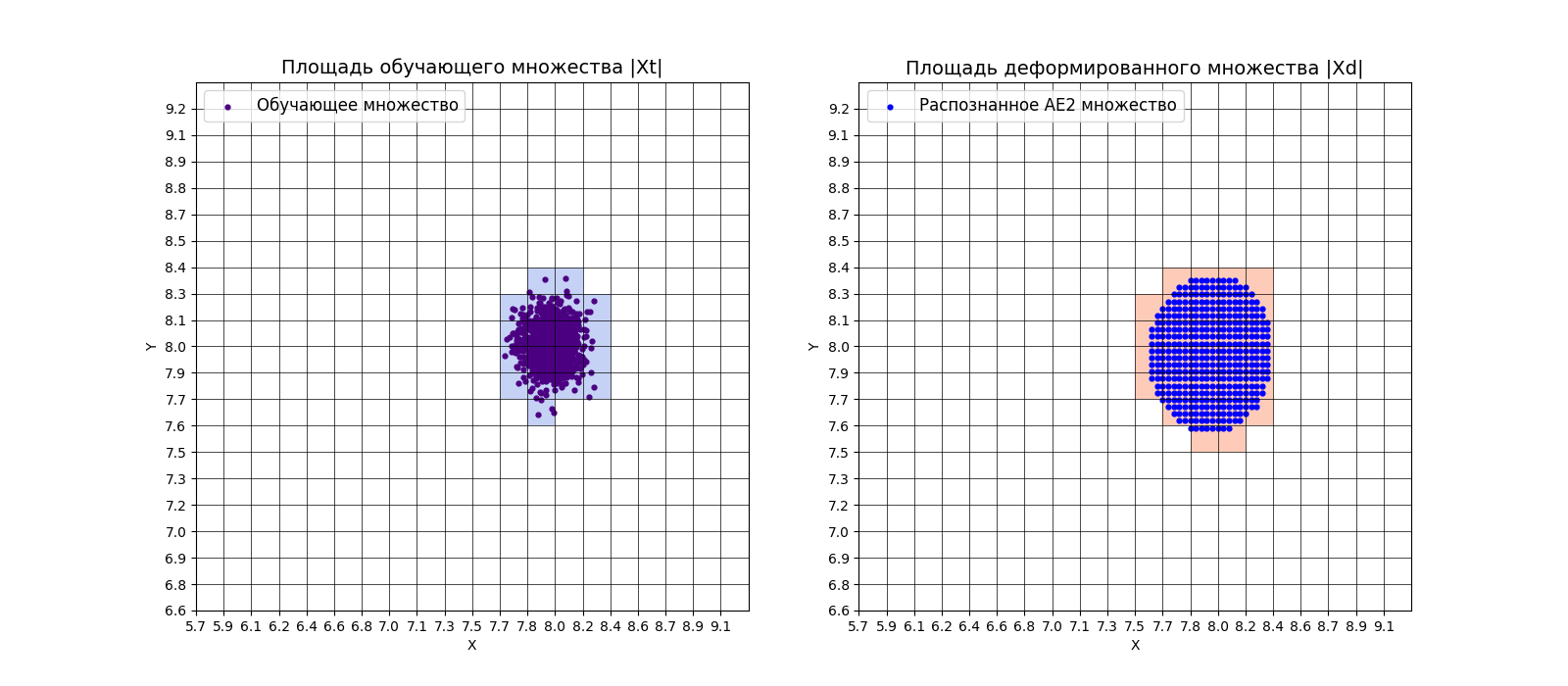
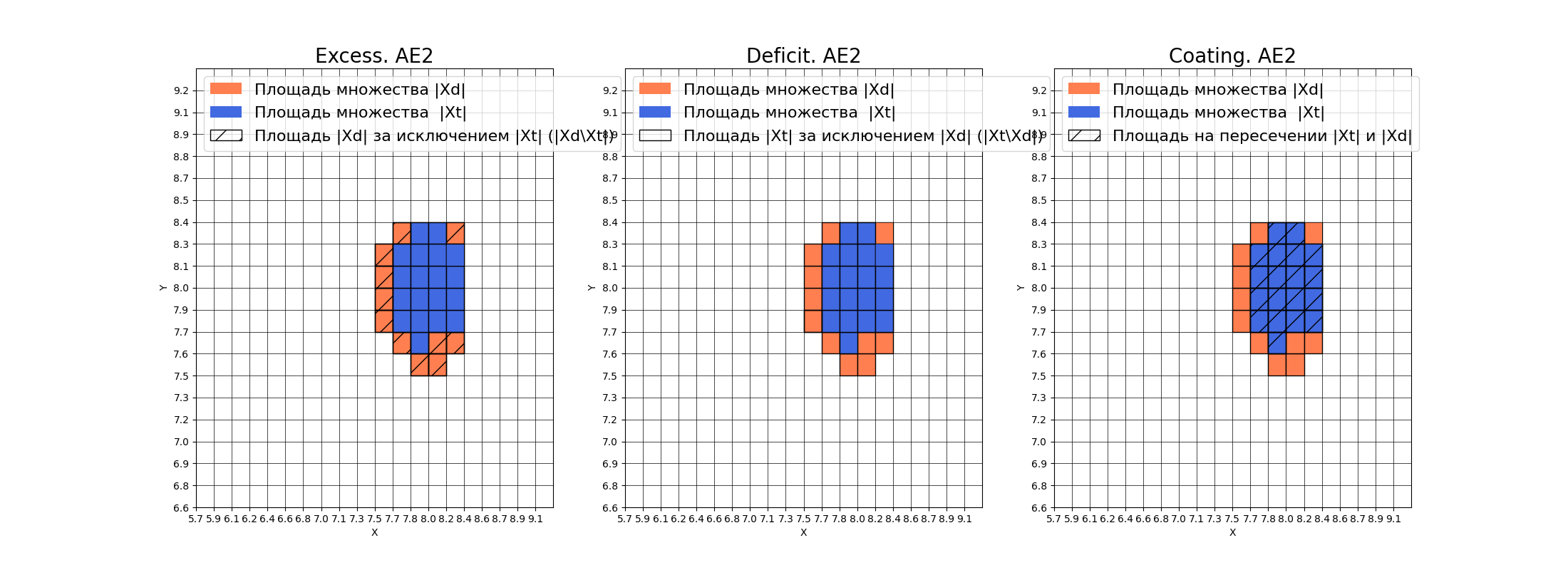
Оценка качества AE2
IDEAL = 0. Excess: 0.5789473684210527
IDEAL = 0. Deficit: 0.0
IDEAL = 1. Coating: 1.0
summa: 1.0
IDEAL = 1. Extrapolation precision (Approx): 0.6333333333333334
7.3. Сравнение характеристик качества обучения и областей аппроксимации
lib.plot2in1(data, xx, yy, Z1, Z2)
Вывод:
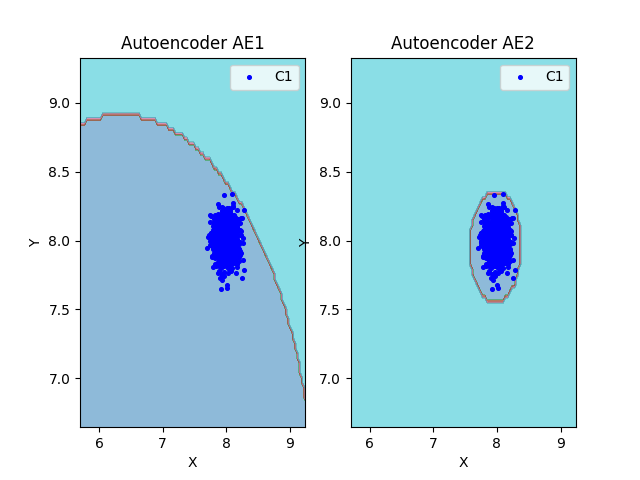
По результатам подсчетов характеристик качества обучения EDCA, можно сделать вывод о непригодности автокодировщика АЕ1. Значение Excess = 13.74 значительно превышает идеальный показатель 0. АЕ1 считает нормой данные, которые находятся в 14 раз за пределами реального распределения обучающей выборки. Низкое значение Approx = 0.07 подтверждает плохую аппроксимацию исходных данных. Такой автокодировщик будет пропускать большинство аномалий и не может быть рекомендован для практического применения.
Автокодировщик АЕ2 показывает более высокие результаты. Значение Excess = 0.58 близко к идеальному, что указывает на точное определение границ нормального класса. Approx = 0.63 демонстрирует хорошую точность аппроксимации исходных данных. Данный автокодировщик пригоден для решения практических задач обнаружения аномалий.
8. Создание тестовой выборки
Нужно создать тестовую выборку, состояющую, как минимум, из 4 элементов, не входящих в обучающую выборку. Элементы должны быть такими, чтобы AE1 распознавал их как норму, а AE2 детектировал как аномалии.
Подберем 6 точек. Условие, чтобы точка не попала в обучающую выборку:
(x < 7.7 or x > 8.3) or (y < 7.7 or y > 8.3)
Поскольку центр располагается в точке (8;8) и в функции для генерации датасета используется правило 3σ, где параметр cluster_std = 0.1, то точки за пределами 7.7 и 8.3 не входят в обучающую выборку с вероятностью 99.7%.
Запишем точки в массив и сохраним в файл.
test_points = np.array([
[8.5, 8.5],
[7.5, 7.5],
[8.4, 7.6],
[7.6, 8.4],
[8.45, 7.55],
[7.55, 8.45]
])
np.savetxt('data_test.txt', test_points)
9. Тестирование автокодировщиков АЕ1 и АЕ2
Загрузим тестовый набор.
data_test = np.loadtxt('data_test.txt', dtype=float)
Проведем тестирование первого автокодировщика.
predicted_labels1, ire1 = lib.predict_ae(ae1_trained, data_test, IREth1)
lib.anomaly_detection_ae(predicted_labels1, ire1, IREth1)
lib.ire_plot('test', ire1, IREth1, 'AE1')
Вывод:
i Labels IRE IREth
0 [1.] [3.43] 3.07
1 [0.] [2.03] 3.07
2 [0.] [2.71] 3.07
3 [0.] [2.85] 3.07
4 [0.] [2.72] 3.07
5 [0.] [2.88] 3.07
Обнаружено 1.0 аномалий
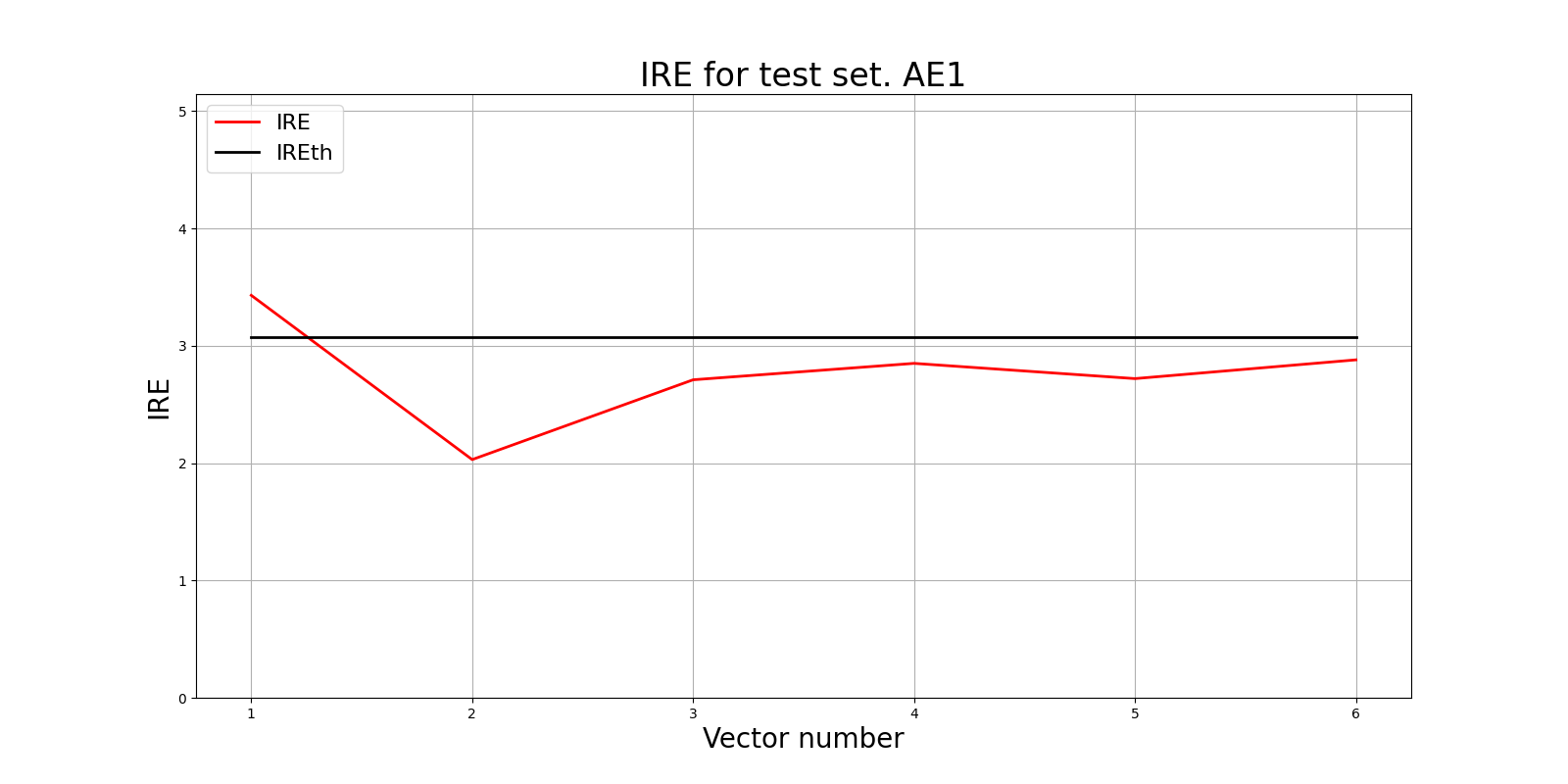
Условие выполнено - 5 точек АЕ1 распознал как норму и лишь одну точку определил как аномалию. Данный автокодировщик плохо справляется с распознаванием аномалий.
Проведем тестирование второго автокодировщика.
predicted_labels2, ire2 = lib.predict_ae(ae2_trained, data_test, IREth2)
lib.anomaly_detection_ae(predicted_labels2, ire2, IREth2)
lib.ire_plot('test', ire2, IREth2, 'AE2')
i Labels IRE IREth
0 [1.] [0.75] 0.4
1 [1.] [0.66] 0.4
2 [1.] [0.55] 0.4
3 [1.] [0.58] 0.4
4 [1.] [0.62] 0.4
5 [1.] [0.65] 0.4
Обнаружено 6.0 аномалий
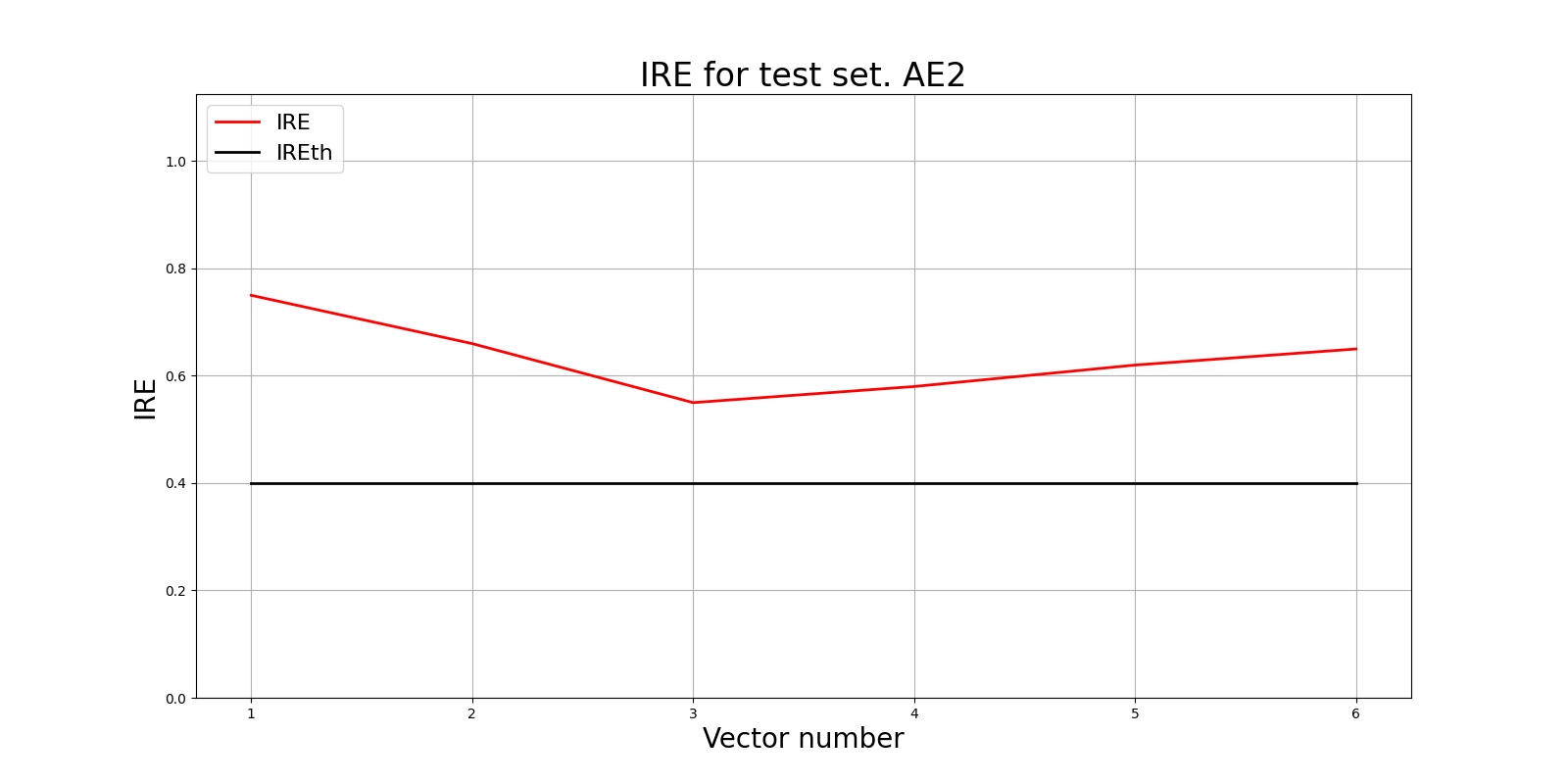
Мы видим, что условие также выполнено - все точки являются аномальными.
10. Визуализация элементов обучающей и тестовой выборки в областях пространства признаков
Построим области аппроксимации и точки тестового набора
lib.plot2in1_anomaly(data, xx, yy, Z1, Z2, data_test)

11. Результаты исследования
Занесем результаты исследования в таблицу:
| Параметр | AE1 | AE2 |
|---|---|---|
| Количество скрытых слоев | 1 | 5 |
| Количество нейронов в скрытых слоях | 5 | 4-3-2-3-4 |
| Количество эпох обучения | 1000 | 2700 |
| Ошибка MSE_stop | 3.7394 | 0.0114 |
| Порог ошибки реконструкции | 3.07 | 0.4 |
| Значение показателя Excess | 13.7368 | 0.5789 |
| Значение показателя Approx | 0.0679 | 0.6333 |
| Количество обнаруженных аномалий | 1 | 6 |
12. Общие выводы
На основе проведенного исследования автокодировщиков AE1 и AE2 были определены ключевые требования для эффективного обнаружения аномалий:
1. Данные для обучения должны быть репрезентативными и не содержать аномалий. Объем выборки должен быть достаточным для покрытия всей области нормального поведения объектов.
2. Архитектура автокодировщика должна иметь не менее 3-5 скрытых слоев с симметричной структурой, обеспечивающей плавное сжатие и восстановление данных. Простые архитектуры, как у AE1 (1 слой), не способны качественно выявлять аномалии.
3. Количество эпох обучения должно составлять не менее 2000-3000 для достижения удовлетворительного качества. Короткое обучение (1000 эпох у AE1) приводит к недообучению и низкой эффективности.
4. Ошибка MSE_stop должна находиться в диапазоне 0.01-0.05. Высокие значения ошибки (3.74 у AE1) свидетельствуют о непригодности модели для обнаружения аномалий.
5. Порог обнаружения аномалий должен быть строгим (0.3-0.5) для минимизации ложных пропусков. Завышенный порог (3.07 у AE1) приводит к некорректной классификации аномальных объектов как нормальных.
6. Характеристики EDCA должны быть близки к идеальным значениям: Excess → 0, Approx → 1. Значения AE2 (Excess=0.58, Approx=0.63) демонстрируют удовлетворительное качество, в то время как показатели AE1 (Excess=13.74, Approx=0.07) указывают на полную непригодность для практического применения.
Таким образом, для надежного обнаружения аномалий необходимо использовать сложные архитектуры автокодировщиков с продолжительным обучением и контролем качества через метрики EDCA.
Задание 2
1. Описание набора реальных данных
Номер бригады k = 8. Следовательно, наш набор реальных данных - WBC.
N = k mod 3
Он представляет из себя 378 примеров с 30 признаками, где из 378 примеров 357 являются нормальными и относятся к доброкачественному классу, 21 - аномалиями и относятся к злокачественному классу.
2. Загрузка обучающей выборки
train = np.loadtxt('WBC_train.txt', dtype=float)
3. Вывод полученных данных и их размерность
print('Исходные данные:')
print(train)
print('Размерность данных:')
print(train.shape)
Вывод:
Исходные данные:
[[3.1042643e-01 1.5725397e-01 3.0177597e-01 ... 4.4261168e-01
2.7833629e-01 1.1511216e-01]
[2.8865540e-01 2.0290835e-01 2.8912998e-01 ... 2.5027491e-01
3.1914055e-01 1.7571822e-01]
[1.1940934e-01 9.2323301e-02 1.1436666e-01 ... 2.1398625e-01
1.7445299e-01 1.4882592e-01]
...
[3.3456387e-01 5.8978695e-01 3.2886463e-01 ... 3.6013746e-01
1.3502858e-01 1.8476978e-01]
[1.9967817e-01 6.6486304e-01 1.8575081e-01 ... 0.0000000e+00
1.9712202e-04 2.6301981e-02]
[3.6868759e-02 5.0152181e-01 2.8539838e-02 ... 0.0000000e+00
2.5744136e-01 1.0068215e-01]]
Размерность данных:
(357, 30)
4. Создание и обучение автокодировщика АЕ3
Для начала попробуем обучить автокодировщик при минимально возможных параметрах и посмотреть на порог ошибки реконструкции. То есть будем обучать в течение 50000 эпох с параметром patience = 5000, с 9 скрытыми слоями и архиектурой 15-13-11-9-7-9-11-13-15
patience = 5000
ae3_trained, IRE3, IREth3 = lib.create_fit_save_ae(train,'out/AE3.h5','out/AE3_ire_th.txt', 50000, False, patience)
lib.ire_plot('training', IRE3, IREth3, 'AE3')
Вывод:
Задать архитектуру автокодировщиков или использовать архитектуру по умолчанию? (1/2): 1
Задайте количество скрытых слоёв (нечетное число) : 9
Задайте архитектуру скрытых слоёв автокодировщика, например, в виде 3 1 3 : 15 13 11 9 7 9 11 13 15
Epoch 1000/50000
- loss: 0.0020
Epoch 2000/50000
- loss: 0.0013
Epoch 3000/50000
- loss: 0.0012
Epoch 4000/50000
- loss: 0.0012
Epoch 5000/50000
- loss: 0.0011
Epoch 6000/50000
- loss: 0.0010
MSE_stop = 0.001
5. График ошибки реконструкции
Построим график ошибки реконструкции и выведем порог ошибки реконструкции.
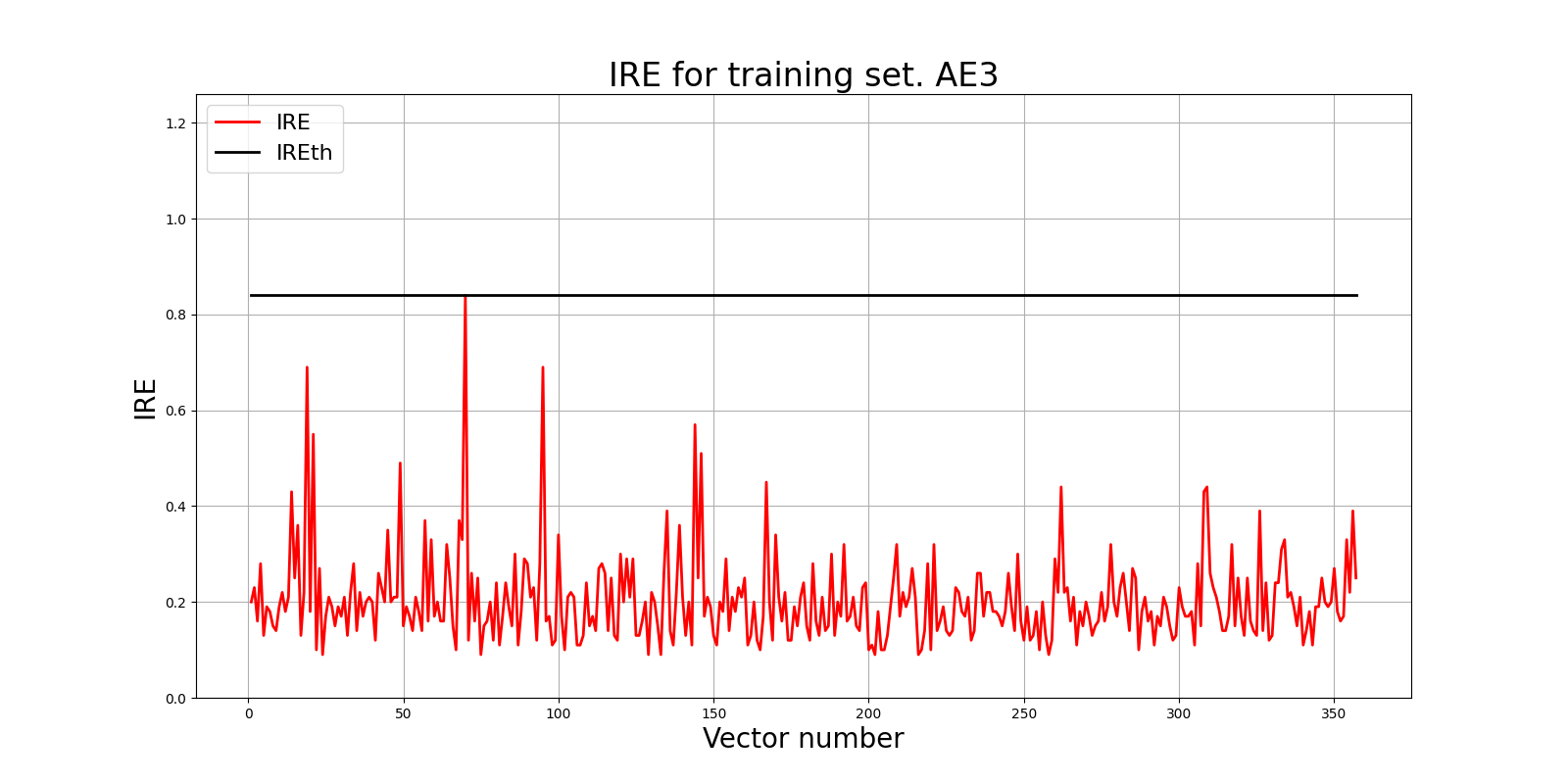
IREth3 = 0.84
6. Вывод о пригодности обученного автокодировщика
Обученный автокодировщик демонстрирует удовлетворительные результаты для обнаружения аномалий. Модель со архитектурой 15-13-11-9-7-9-11-13-15 успешно прошла обучение, достигнув MSE = 0.001 за 6000 эпох. Стабильное снижение функции потерь свидетельствует о корректной работе алгоритма.
Установленный порог IREth = 0.84 является разумным для разделения нормальных и аномальных образцов. Узкое горлышко из 7 нейронов обеспечивает необходимое сжатие данных для выделения ключевых признаков.
Модель можно считать пригодной для практического использования при условии, что тестирование подтвердит достижение целевых 70% обнаружения аномалий.
7. Загрузка тестовой выборки
test = np.loadtxt('WBC_test.txt', dtype=float)
print('Исходные данные:')
print(test)
print('Размерность данных:')
print(test.shape)
Вывод:
Исходные данные:
[[0.18784609 0.3936422 0.19425057 0.09654295 0.632572 0.31415251
0.24461106 0.28175944 0.42171717 0.3946925 0.04530147 0.23598833
0.05018141 0.01899148 0.21589557 0.11557064 0.0655303 0.19643872
0.08003602 0.07411246 0.17467094 0.62153518 0.18332586 0.08081007
0.79066235 0.23528442 0.32132588 0.48934708 0.2757737 0.26905418]
[0.71129727 0.41224214 0.71460162 0.56776246 0.48451747 0.53990553
0.57357076 0.74602386 0.38585859 0.24094356 0.3246424 0.07507514
0.32059558 0.23047901 0.0769963 0.19495599 0.09030303 0.27865126
0.10269038 0.10023078 0.70188545 0.36727079 0.72010558 0.50181872
0.38453411 0.35044775 0.3798722 0.83573883 0.23181549 0.20136429]
..............
[0.32367836 0.49983091 0.33542948 0.1918982 0.57389185 0.45616833
0.31794752 0.33593439 0.61363636 0.47198821 0.13166757 0.25808876
0.10446214 0.06023183 0.27082979 0.27268904 0.08777778 0.30611858
0.23158102 0.21074997 0.28744219 0.5575693 0.27685642 0.14815179
0.71471967 0.35830641 0.27004792 0.52268041 0.41119653 0.41492851]]
Размерность данных:
(21, 30)
8. Тестирование обученного автокодировщика
predicted_labels3, ire3 = lib.predict_ae(ae3_trained, test, IREth3)
lib.anomaly_detection_ae(predicted_labels3, ire3, IREth3)
lib.ire_plot('test', ire3, IREth3, 'AE3')
Вывод:
i Labels IRE IREth
0 [0.] [0.27] 0.84
1 [0.] [0.8] 0.84
2 [0.] [0.32] 0.84
3 [0.] [0.53] 0.84
4 [0.] [0.55] 0.84
5 [0.] [0.68] 0.84
6 [0.] [0.53] 0.84
7 [1.] [0.95] 0.84
8 [0.] [0.31] 0.84
9 [0.] [0.47] 0.84
10 [0.] [0.44] 0.84
11 [1.] [1.07] 0.84
12 [0.] [0.25] 0.84
13 [0.] [0.45] 0.84
14 [0.] [0.27] 0.84
15 [0.] [0.58] 0.84
16 [0.] [0.53] 0.84
17 [0.] [0.27] 0.84
18 [1.] [1.29] 0.84
19 [1.] [0.93] 0.84
20 [0.] [0.24] 0.84
Обнаружено 4.0 аномалий

При текущих параметрах было достигнуто лишь 19% выявленных аномалий, что свидетельствует о непригодности данного автокодировщика.
9. Подбор подходящих параметров
Мы провели несколько тестов и путем подбора пришли к архитектуре, удовлетворяющей условие пригодности автокодировщика - не менее 70% выявления аномалий.
Для этого мы установили параметр early_stopping_delta = 0.00001 и увеличили параметр patience до 20000. Однако критерием останова в нашем случае являлся параметр early_stopping_value, который мы также изменили до 0.00007. Количество эпох мы оставили прежним - 50000.
Помимо этого, мы установили оптимальную архитектуру - 9 скрытых слоев с 24-22-20-17-15-17-20-22-24 нейронами.
patience = 20000
ae3_trained, IRE3, IREth3 = lib.create_fit_save_ae(train,'out/AE3.h5','out/AE3_ire_th.txt', 50000, False, patience, early_stopping_delta = 0.00001, early_stopping_value = 0.00007)
lib.ire_plot('training', IRE3, IREth3, 'AE3')
Вывод:
Задать архитектуру автокодировщиков или использовать архитектуру по умолчанию? (1/2): 1
Задайте количество скрытых слоёв (нечетное число) : 9
Задайте архитектуру скрытых слоёв автокодировщика, например, в виде 3 1 3 : 24 22 20 17 15 17 20 22 24
Epoch 1000/50000
- loss: 0.000864
Epoch 2000/50000
- loss: 0.000545
Epoch 3000/50000
- loss: 0.000415
Epoch 4000/50000
- loss: 0.000303
Epoch 5000/50000
- loss: 0.000226
Epoch 6000/50000
- loss: 0.000217
Epoch 7000/50000
- loss: 0.000207
Epoch 8000/50000
- loss: 0.000186
Epoch 9000/50000
- loss: 0.000167
Epoch 10000/50000
- loss: 0.000113
Epoch 11000/50000
- loss: 0.000102
Epoch 12000/50000
- loss: 0.000095
Epoch 13000/50000
- loss: 0.000090
Epoch 14000/50000
- loss: 0.000088
Epoch 15000/50000
- loss: 0.000086
Epoch 16000/50000
- loss: 0.000079
Epoch 17000/50000
- loss: 0.000078
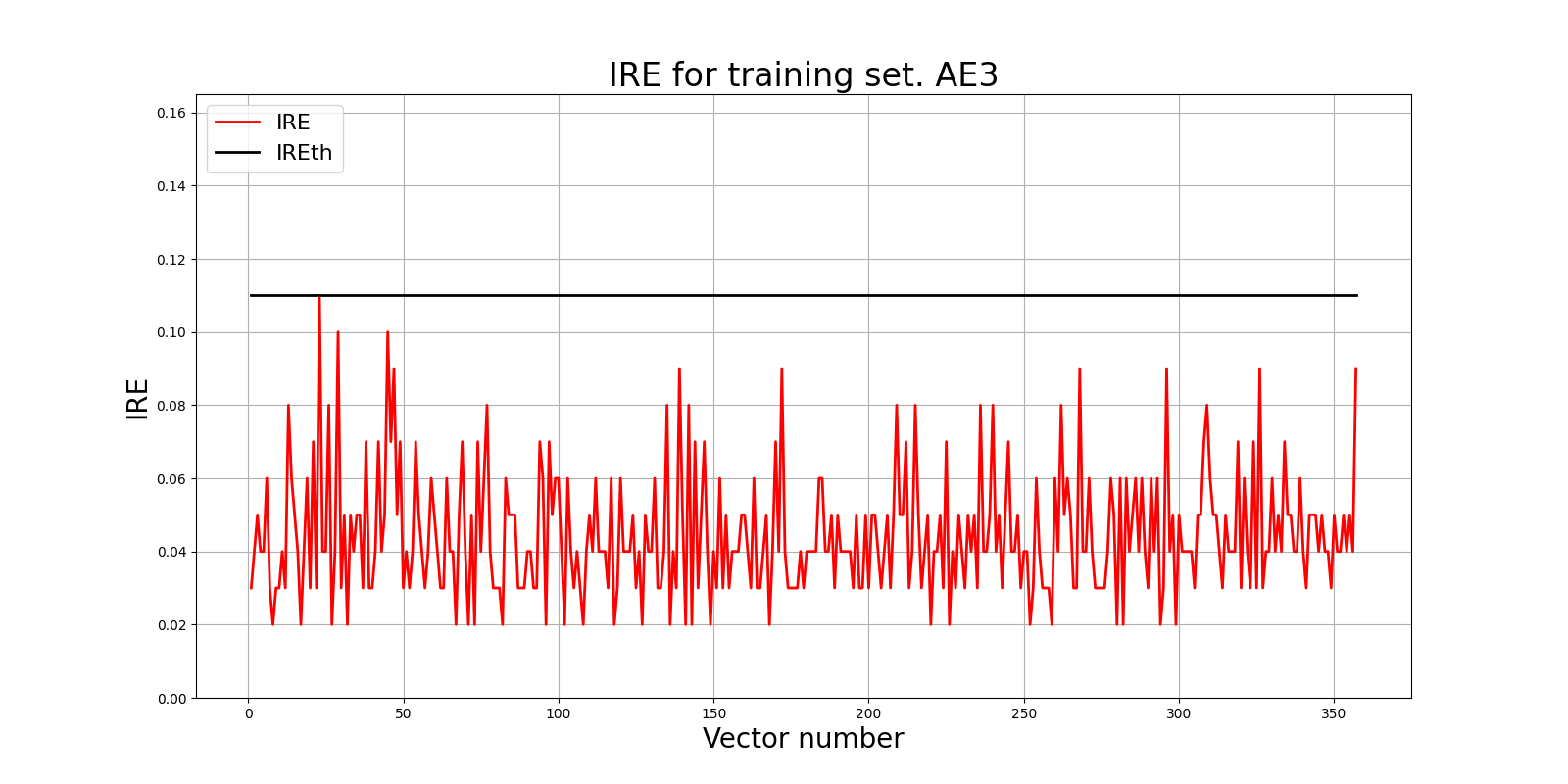
Пороговое значение IREth3 = 0.11 является оптимальным, т.к. позволяет обнаруживать даже слабые аномалии, при этом сам по себе не слишком строгий.
predicted_labels3, ire3 = lib.predict_ae(ae3_trained, test, IREth3)
lib.anomaly_detection_ae(predicted_labels3, ire3, IREth3)
lib.ire_plot('test', ire3, IREth3, 'AE3')
i Labels IRE IREth
0 [0.] [0.1] 0.11
1 [1.] [0.5] 0.11
2 [0.] [0.05] 0.11
3 [1.] [0.15] 0.11
4 [1.] [0.27] 0.11
5 [1.] [0.39] 0.11
6 [1.] [0.16] 0.11
7 [1.] [0.61] 0.11
8 [0.] [0.07] 0.11
9 [1.] [0.21] 0.11
10 [1.] [0.22] 0.11
11 [1.] [0.57] 0.11
12 [0.] [0.11] 0.11
13 [1.] [0.21] 0.11
14 [1.] [0.12] 0.11
15 [1.] [0.32] 0.11
16 [1.] [0.29] 0.11
17 [0.] [0.1] 0.11
18 [1.] [0.87] 0.11
19 [1.] [0.52] 0.11
20 [0.] [0.11] 0.11
Обнаружено 15.0 аномалий

Тестирование модели продемонстрировало превосходные результаты - обнаружено 15 из 21 аномалий, что соответствует 71.4% точности и превышает целевую метрику в 70%.
10. Результаты исследования
Занесем результаты исследования в таблицу:
| Параметр | Значение |
|---|---|
| Dataset name | WBC |
| Количество скрытых слоев | 9 |
| Количество нейронов в скрытых слоях | 24-22-20-17-15-17-20-22-24 |
| Количество эпох обучения | 50000 |
| Ошибка MSE_stop | 0.000078 |
| Порог ошибки реконструкции | 0.11 |
| % обнаруженных аномалий | 71.4 |
11. Общие выводы
На основе проведенного исследования автокодировщиков AE1 и AE2 были определены ключевые требования для эффективного обнаружения аномалий:
1. Данные для обучения должны быть тщательно отобраны и содержать только репрезентативные нормальные образцы. Для 30-мерного пространства признаков объем выборки должен составлять не менее 300-500 объектов для адекватного покрытия области нормального поведения.
2. Архитектура автокодировщика должна иметь глубокую симметричную структуру с 7-9 скрытыми слоями. Оптимальная конфигурация 24-22-20-17-15-17-20-22-24 нейронов обеспечивает плавное сжатие 30-мерного пространства до 15 нейронов в горлышке с последующим восстановлением, что позволяет эффективно выделять существенные признаки.
3. Количество эпох обучения должно составлять не менее 15000-20000 для достижения высокого качества реконструкции. Продолжительное обучение необходимо для сложных высокоразмерных данных.
4. Ошибка MSE_stop должна достигать значений 0.00007-0.0001. Столь низкий порог обусловлен высокой размерностью данных и необходимостью точной реконструкции многочисленных признаков.
5. Порог обнаружения аномалий должен быть строгим (0.1-0.15) для надежного выявления аномалий в сложном многомерном пространстве. Низкое значение IREth компенсирует высокую размерность данных и обеспечивает чувствительность к слабым отклонениям.
Таким образом, для качественного обнаружения аномалий в высокоразмерных данных необходимы глубокие архитектуры автокодировщиков с продолжительным обучением до достижения экстремально низких значений ошибки реконструкции.