форкнуто от main/is_dnn
Вы не можете выбрать более 25 тем
Темы должны начинаться с буквы или цифры, могут содержать дефисы(-) и должны содержать не более 35 символов.
18 KiB
18 KiB
Отчёт по лабораторной работе №4
Касимов Азамат, Немыкин Никита — А-01-22
Задание 1
1) В среде Google Colab создали новый блокнот (notebook). Импортировали необходимые для работы библиотеки и модули. Настроили блокнот для работы с аппаратным ускорителем GPU.
# импорт модулей
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab4')
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
2) Загрузили набор данных IMDb, содержащий оцифрованные отзывы на фильмы, размеченные на два класса: позитивные и негативные. При загрузке набора данных параметр seed выбрали равным значению (4k – 1)=23, где k=6 – номер бригады. Вывели размеры полученных обучающих и тестовых массивов данных.
# загрузка датасета
from keras.datasets import imdb
vocabulary_size = 5000
index_from = 3
(X_train, y_train), (X_test, y_test) = imdb.load_data(
path="imdb.npz",
num_words=vocabulary_size,
skip_top=0,
maxlen=None,
seed=23,
start_char=1,
oov_char=2,
index_from=index_from
)
# вывод размерностей
print('Shape of X train:', X_train.shape)
print('Shape of y train:', y_train.shape)
print('Shape of X test:', X_test.shape)
print('Shape of y test:', y_test.shape)
Shape of X train: (25000,)
Shape of y train: (25000,)
Shape of X test: (25000,)
Shape of y test: (25000,)
3) Вывели один отзыв из обучающего множества в виде списка индексов слов. Преобразовали список индексов в текст и вывели отзыв в виде текста. Вывели длину отзыва. Вывели метку класса данного отзыва и название класса (1 – Positive, 0 – Negative).
# создание словаря для перевода индексов в слова
# заргузка словаря "слово:индекс"
word_to_id = imdb.get_word_index()
# уточнение словаря
word_to_id = {key:(value + index_from) for key,value in word_to_id.items()}
word_to_id["<PAD>"] = 0
word_to_id["<START>"] = 1
word_to_id["<UNK>"] = 2
word_to_id["<UNUSED>"] = 3
# создание обратного словаря "индекс:слово"
id_to_word = {value:key for key,value in word_to_id.items()}
print(X_train[21])
print('len:',len(X_train[21]))
[1, 14, 20, 9, 290, 149, 48, 25, 358, 2, 120, 318, 302, 50, 26, 49, 221, 2057, 10, 10, 1212, 39, 15, 45, 801, 2, 2, 363, 2396, 7, 2, 209, 2327, 283, 8, 4, 425, 10, 10, 45, 24, 290, 3613, 972, 4, 65, 198, 40, 3462, 1224, 2, 23, 6, 4457, 225, 24, 76, 50, 8, 895, 19, 45, 164, 204, 5, 24, 55, 318, 38, 92, 140, 11, 18, 4, 65, 33, 32, 43, 168, 33, 4, 302, 10, 10, 17, 47, 77, 1046, 12, 188, 6, 117, 2, 33, 4, 130, 2, 4, 2, 7, 87, 3709, 2199, 7, 35, 2504, 5, 33, 211, 320, 2504, 132, 190, 48, 25, 2754, 4, 1273, 2, 45, 6, 1682, 8, 2, 42, 24, 8, 2, 10, 10, 32, 11, 32, 45, 6, 542, 3709, 22, 290, 319, 18, 15, 1288, 5, 15, 584]
len: 146
review_as_text = ' '.join(id_to_word[id] for id in X_train[26])
print(review_as_text)
print('len:',len(review_as_text))
<START> this movie is worth watching if you enjoy <UNK> over special effects there are some interesting visuals br br aside from that it's typical <UNK> <UNK> hollywood fare of <UNK> without substance true to the title br br it's not worth picking apart the story that's like performing brain <UNK> on a dinosaur there's not much there to begin with it's nothing original and not very special so don't go in for the story at all just look at the effects br br as has been mentioned it got a little <UNK> at the end <UNK> the <UNK> of great fx treatment of an invisible and at times half invisible man however if you ignore the standard <UNK> it's a sight to <UNK> or not to <UNK> br br all in all it's a decent fx film worth seeing for that purpose and that alone
len: 763
4) Вывели максимальную и минимальную длину отзыва в обучающем множестве.
print('MAX Len: ',len(max(X_train, key=len)))
print('MIN Len: ',len(min(X_train, key=len)))
MAX Len: 2494
MIN Len: 11
5) Провели предобработку данных. Выбрали единую длину, к которой будут приведены все отзывы. Короткие отзывы дополнили спецсимволами, а длинные обрезали до выбранной длины.
# предобработка данных
from tensorflow.keras.utils import pad_sequences
max_words = 500
X_train = pad_sequences(X_train, maxlen=max_words, value=0, padding='pre', truncating='post')
X_test = pad_sequences(X_test, maxlen=max_words, value=0, padding='pre', truncating='post')
6) Повторили пункт 4.
print('MAX Len: ',len(max(X_train, key=len)))
print('MIN Len: ',len(min(X_train, key=len)))
MAX Len: 500
MIN Len: 500
7) Повторили пункт 3. Сделали вывод о том, как отзыв преобразовался после предобработки.
print(X_train[23])
print('len:',len(X_train[23]))
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 1 14 20 9 290 149 48 25 358 2
120 318 302 50 26 49 221 2057 10 10 1212 39 15 45
801 2 2 363 2396 7 2 209 2327 283 8 4 425 10
10 45 24 290 3613 972 4 65 198 40 3462 1224 2 23
6 4457 225 24 76 50 8 895 19 45 164 204 5 24
55 318 38 92 140 11 18 4 65 33 32 43 168 33
4 302 10 10 17 47 77 1046 12 188 6 117 2 33
4 130 2 4 2 7 87 3709 2199 7 35 2504 5 33
211 320 2504 132 190 48 25 2754 4 1273 2 45 6 1682
8 2 42 24 8 2 10 10 32 11 32 45 6 542
3709 22 290 319 18 15 1288 5 15 584]
len: 500
review_as_text = ' '.join(id_to_word[id] for id in X_train[23])
print(review_as_text)
print('len:',len(review_as_text))
<PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <START> this movie is worth watching if you enjoy <UNK> over special effects there are some interesting visuals br br aside from that it's typical <UNK> <UNK> hollywood fare of <UNK> without substance true to the title br br it's not worth picking apart the story that's like performing brain <UNK> on a dinosaur there's not much there to begin with it's nothing original and not very special so don't go in for the story at all just look at the effects br br as has been mentioned it got a little <UNK> at the end <UNK> the <UNK> of great fx treatment of an invisible and at times half invisible man however if you ignore the standard <UNK> it's a sight to <UNK> or not to <UNK> br br all in all it's a decent fx film worth seeing for that purpose and that alone
len: 2887
После обработки в начало отзыва добавилось необходимое количество токенов , чтобы отзыв был длинной в 500 индексов.
8) Вывели предобработанные массивы обучающих и тестовых данных и их размерности.
# вывод данных
print('X train: \n',X_train)
print('X train: \n',X_test)
# вывод размерностей
print('Shape of X train:', X_train.shape)
print('Shape of X test:', X_test.shape)
X train:
[[ 0 0 0 ... 6 52 106]
[ 0 0 0 ... 87 22 231]
[ 0 0 0 ... 6 158 158]
...
[ 0 0 0 ... 1005 4 1630]
[ 0 0 0 ... 9 6 991]
[ 0 0 0 ... 7 32 58]]
X train:
[[ 0 0 0 ... 4 2 2]
[ 0 0 0 ... 6 2 123]
[ 0 0 0 ... 2 11 831]
...
[ 1 14 402 ... 819 45 131]
[ 0 0 0 ... 17 1540 2]
[ 1 17 6 ... 1026 362 37]]
Shape of X train: (25000, 500)
Shape of X test: (25000, 500)
9) Реализовали модель рекуррентной нейронной сети, состоящей из слоев Embedding, LSTM, Dropout, Dense, и обучили ее на обучающих данных с выделением части обучающих данных в качестве валидационных. Вывели информацию об архитектуре нейронной сети. Добились качества обучения по метрике accuracy не менее 0.8.
embed_dim = 32
lstm_units = 64
model = Sequential()
model.add(layers.Embedding(input_dim=vocabulary_size, output_dim=embed_dim, input_length=max_words, input_shape=(max_words,)))
model.add(layers.LSTM(lstm_units))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
Model: "sequential"
| Layer (type) | Output Shape | Param # |
|---|---|---|
| embedding_4 (Embedding) | (None, 500, 32) | 160,000 |
| lstm_4 (LSTM) | (None, 64) | 24,832 |
| dropout_4 (Dropout) | (None, 64) | 0 |
| dense_4 (Dense) | (None, 1) | 65 |
Total params: 184,897 (722.25 KB) Trainable params: 184,897 (722.25 KB) Non-trainable params: 0 (0.00 B)
# компилируем и обучаем модель
batch_size = 64
epochs = 3
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.2)
Epoch 1/3
313/313 ━━━━━━━━━━━━━━━━━━━━ 12s 23ms/step - accuracy: 0.6705 - loss: 0.5794 - val_accuracy: 0.6740 - val_loss: 1.3409
Epoch 2/3
313/313 ━━━━━━━━━━━━━━━━━━━━ 6s 19ms/step - accuracy: 0.6394 - loss: 0.8250 - val_accuracy: 0.7424 - val_loss: 0.5590
Epoch 3/3
313/313 ━━━━━━━━━━━━━━━━━━━━ 7s 22ms/step - accuracy: 0.7780 - loss: 0.4830 - val_accuracy: 0.8268 - val_loss: 0.4142
<keras.src.callbacks.history.History at 0x784aa347c710>
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f"\nTest accuracy: {test_acc}")
782/782 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.8389 - loss: 0.3970
Test accuracy: 0.8352800011634827
10) Оценили качество обучения на тестовых данных:
- вывели значение метрики качества классификации на тестовых данных
- вывели отчет о качестве классификации тестовой выборки
- построили ROC-кривую по результату обработки тестовой выборки и вычислили площадь под ROC-кривой (AUC ROC)
#значение метрики качества классификации на тестовых данных
print(f"\nTest accuracy: {test_acc}")
Test accuracy: 0.8352800011634827
#отчет о качестве классификации тестовой выборки
y_score = model.predict(X_test)
y_pred = [1 if y_score[i,0]>=0.5 else 0 for i in range(len(y_score))]
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred, labels = [0, 1], target_names=['Negative', 'Positive']))
precision recall f1-score support
Negative 0.86 0.80 0.83 12500
Positive 0.81 0.87 0.84 12500
accuracy 0.84 25000
macro avg 0.84 0.84 0.84 25000
weighted avg 0.84 0.84 0.84 25000
#построение ROC-кривой и AUC ROC
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_test, y_score)
plt.plot(fpr, tpr)
plt.grid()
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC')
plt.show()
print('AUC ROC:', auc(fpr, tpr))
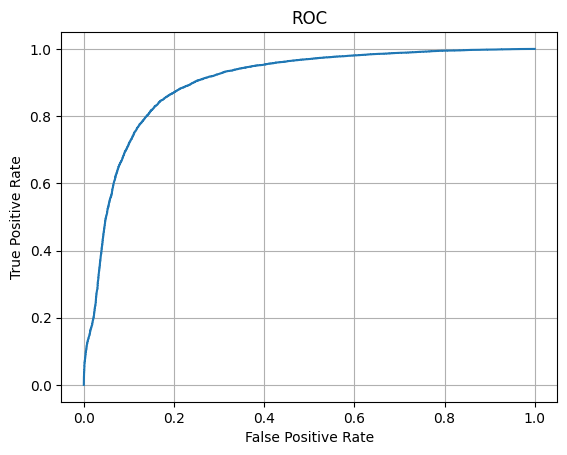
AUC ROC: 0.9009091648
11) Сделали выводы по результатам применения рекуррентной нейронной сети для решения задачи определения тональности текста.
Таблица1:
| Модель | Количество настраиваемых параметров | Количество эпох обучения | Качество классификации тестовой выборки |
|---|---|---|---|
| Рекуррентная | 184 897 | 3 | accuracy:0.8389 ; loss:0.3970 ; AUC ROC:0.9009 |