форкнуто от main/is_dnn
Вы не можете выбрать более 25 тем
Темы должны начинаться с буквы или цифры, могут содержать дефисы(-) и должны содержать не более 35 символов.
20 KiB
20 KiB
Отчёт по лабораторной работе №4
Фонов А.Д., Хнытченков А.М. — А-01-22
1. В среде Google Colab создали новый блокнот (notebook). Настроили блокнот для работы с аппаратным ускорителем GPU.
from google.colab import drive
drive.mount('/content/drive')
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab4')
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
2. Загрузили набор данных IMDb, содержащий оцифрованные отзывы на фильмы, размеченные на два класса: позитивные и негативные. При загрузке набора данных параметр seed выбрали равным (4k – 1) = 11, где k = 3 – номер бригады. Вывели размеры полученных обучающих и тестовых массивов данных.
# загрузка датасета
from keras.datasets import imdb
vocabulary_size = 5000
index_from = 3
(X_train, y_train), (X_test, y_test) = imdb.load_data(
path="imdb.npz",
num_words=vocabulary_size,
skip_top=0,
maxlen=None,
seed=11,
start_char=1,
oov_char=2,
index_from=index_from
)
# вывод размерностей
print('Shape of X train:', X_train.shape)
print('Shape of y train:', y_train.shape)
print('Shape of X test:', X_test.shape)
print('Shape of y test:', y_test.shape)
Shape of X train: (25000,)
Shape of y train: (25000,)
Shape of X test: (25000,)
Shape of y test: (25000,)
3. Вывели один отзыв из обучающего множества в виде списка индексовслов. Преобразовали список индексов в текст и вывели отзыв в виде текста. Вывели длину отзыва. Вывели метку класса данного отзыва и название класса (1 – Positive, 0 – Negative).
# создание словаря для перевода индексов в слова
# загрузка словаря "слово:индекс"
word_to_id = imdb.get_word_index()
# уточнение словаря
word_to_id = {key:(value + index_from) for key,value in word_to_id.items()}
word_to_id["<PAD>"] = 0
word_to_id["<START>"] = 1
word_to_id["<UNK>"] = 2
word_to_id["<UNUSED>"] = 3
# создание обратного словаря "индекс:слово"
id_to_word = {value:key for key,value in word_to_id.items()}
print(X_train[39])
print('len:',len(X_train[39]))
[1, 3206, 2, 3413, 3852, 2, 2, 73, 256, 19, 4396, 3033, 34, 488, 2, 47, 2993, 4058, 11, 63, 29, 4653, 1496, 27, 4122, 54, 4, 1334, 1914, 380, 1587, 56, 351, 18, 147, 2, 2, 15, 29, 238, 30, 4, 455, 564, 167, 1024, 2, 2, 2, 4, 2, 65, 33, 6, 2, 1062, 3861, 6, 3793, 1166, 7, 1074, 1545, 6, 171, 2, 1134, 388, 7, 3569, 2, 567, 31, 255, 37, 47, 6, 3161, 1244, 3119, 19, 6, 2, 11, 12, 2611, 120, 41, 419, 2, 17, 4, 3777, 2, 4952, 2468, 1457, 6, 2434, 4268, 23, 4, 1780, 1309, 5, 1728, 283, 8, 113, 105, 1037, 2, 285, 11, 6, 4800, 2905, 182, 5, 2, 183, 125, 19, 6, 327, 2, 7, 2, 668, 1006, 4, 478, 116, 39, 35, 321, 177, 1525, 2294, 6, 226, 176, 2, 2, 17, 2, 1220, 119, 602, 2, 2, 592, 2, 17, 2, 2, 1405, 2, 597, 503, 1468, 2, 2, 17, 2, 1947, 3702, 884, 1265, 3378, 1561, 2, 17, 2, 2, 992, 3217, 2393, 4923, 2, 17, 2, 2, 1255, 2, 2, 2, 117, 17, 6, 254, 2, 568, 2297, 5, 2, 2, 17, 1047, 2, 2186, 2, 1479, 488, 2, 4906, 627, 166, 1159, 2552, 361, 7, 2877, 2, 2, 665, 718, 2, 2, 2, 603, 4716, 127, 4, 2873, 2, 56, 11, 646, 227, 531, 26, 670, 2, 17, 6, 2, 2, 3510, 2, 17, 6, 2, 2, 2, 3014, 17, 6, 2, 668, 2, 503, 1468, 2, 19, 11, 4, 1746, 5, 2, 4778, 11, 31, 7, 41, 1273, 154, 255, 555, 6, 1156, 5, 737, 431]
len: 274
review_as_text = ' '.join(id_to_word[id] for id in X_train[39])
print(review_as_text)
print('len:',len(review_as_text))
<START> troubled <UNK> magazine photographer <UNK> <UNK> well played with considerable intensity by michael <UNK> has horrific nightmares in which he brutally murders his models when the lovely ladies start turning up dead for real <UNK> <UNK> that he might be the killer writer director william <UNK> <UNK> <UNK> the <UNK> story at a <UNK> pace builds a reasonable amount of tension delivers a few <UNK> effective moments of savage <UNK> violence one woman who has a plastic garbage bag with a <UNK> in it placed over her head <UNK> as the definite <UNK> inducing highlight puts a refreshing emphasis on the nicely drawn and engaging true to life characters further <UNK> everything in a plausible everyday world and <UNK> things off with a nice <UNK> of <UNK> female nudity the fine acting from an excellent cast helps matters a whole lot <UNK> <UNK> as <UNK> charming love interest <UNK> <UNK> james <UNK> as <UNK> <UNK> double <UNK> brother b j <UNK> <UNK> as <UNK> concerned psychiatrist dr frank curtis don <UNK> as <UNK> <UNK> gay assistant louis pamela <UNK> as <UNK> <UNK> detective <UNK> <UNK> <UNK> little as a hard <UNK> police chief and <UNK> <UNK> as sweet <UNK> model <UNK> r michael <UNK> polished cinematography makes impressive occasional use of breathtaking <UNK> <UNK> shots jack <UNK> <UNK> <UNK> score likewise does the trick <UNK> up in cool bit parts are robert <UNK> as a <UNK> <UNK> sally <UNK> as a <UNK> <UNK> <UNK> shower as a <UNK> female <UNK> b j <UNK> with in the ring and <UNK> bay in one of her standard old woman roles a solid and enjoyable picture
len: 1584
4. Вывели максимальную и минимальную длину отзыва в обучающем множестве.
print('MAX Len: ',len(max(X_train, key=len)))
print('MIN Len: ',len(min(X_train, key=len)))
MAX Len: 2494
MIN Len: 11
5. Провели предобработку данных. Выбрали единую длину, к которой будутприведены все отзывы. Короткие отзывы дополнили спецсимволами, а длинные обрезали до выбранной длины.
#предобработка данных
from tensorflow.keras.utils import pad_sequences
max_words = 500
X_train = pad_sequences(X_train, maxlen=max_words, value=0, padding='pre', truncating='post')
X_test = pad_sequences(X_test, maxlen=max_words, value=0, padding='pre', truncating='post')
6. Повторили п. 4.
print('MAX Len: ',len(max(X_train, key=len)))
print('MIN Len: ',len(min(X_train, key=len)))
MAX Len: 500
MIN Len: 500
7. Повторили п. 3. Сделали вывод о том, как отзыв преобразовался после предобработки.
print(X_train[39])
print('len:',len(X_train[39]))
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 1 3206 2 3413 3852 2 2 73 256 19 4396 3033
34 488 2 47 2993 4058 11 63 29 4653 1496 27 4122 54
4 1334 1914 380 1587 56 351 18 147 2 2 15 29 238
30 4 455 564 167 1024 2 2 2 4 2 65 33 6
2 1062 3861 6 3793 1166 7 1074 1545 6 171 2 1134 388
7 3569 2 567 31 255 37 47 6 3161 1244 3119 19 6
2 11 12 2611 120 41 419 2 17 4 3777 2 4952 2468
1457 6 2434 4268 23 4 1780 1309 5 1728 283 8 113 105
1037 2 285 11 6 4800 2905 182 5 2 183 125 19 6
...
2 2 3510 2 17 6 2 2 2 3014 17 6 2 668
2 503 1468 2 19 11 4 1746 5 2 4778 11 31 7
41 1273 154 255 555 6 1156 5 737 431]
len: 500
review_as_text = ' '.join(id_to_word[id] for id in X_train[17])
print(review_as_text)
print('len:',len(review_as_text))
<PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <START> when many people say it's the worst movie i've ever seen they tend to say that about virtually any movie they didn't like however of the nearly <UNK> movies i can remember ever seeing this one is one of two that i walked away from feeling personally <UNK> and angry this is my first movie review by the way and i <UNK> with imdb just to <UNK> at this movie's <UNK> i went to see it when it was in the theaters myself and my two buddies were 3 of 5 people there and after 15 years i can't remember very many <UNK> but my attitude upon leaving the theater is still <UNK> clear br br spoiler alert br br oh my where to begin fat loser left at <UNK> goes on <UNK> weekend meets blonde <UNK> who takes an interest in him takes him home to meet the family they're all <UNK> and he's the main course pathetic attempt at a dramatic escape kicks all their <UNK> and runs off with the <UNK> girlfriend they live happily ever after <UNK> firstly the gags are so bad that it took me a while to understand that they were trying to be funny and that this was a comedy the special effects what few there are look like they were done 15 years earlier the big dramatic ending was so <UNK> and poorly acted that it was nearly unbearable to watch he <UNK> out the entire <UNK> family with <UNK> <UNK> in the <UNK> that stand up tom and jerry style when they step on them i'm sure that there's much much more but i have no intention on seeing it again for a <UNK>
len: 2741
После предобработки отзыв был приведён к фиксированной длине: в начале последовательности появились токены , которые заполнили недостающие позиции. Содержательная часть отзыва сохранилась, но была сдвинута вправо, что обеспечивает единый формат данных для подачи в нейронную сеть.
8. Вывели предобработанные массивы обучающих и тестовых данных и их размерности.
# вывод данных
print('X train: \n',X_train)
print('X train: \n',X_test)
# вывод размерностей
print('Shape of X train:', X_train.shape)
print('Shape of X test:', X_test.shape)
X train:
[[ 0 0 0 ... 7 4 2407]
[ 0 0 0 ... 34 705 2]
[ 0 0 0 ... 2222 8 369]
...
[ 0 0 0 ... 11 4 4596]
[ 0 0 0 ... 574 42 24]
[ 0 0 0 ... 7 13 3891]]
X train:
[[ 0 0 0 ... 6 52 20]
[ 0 0 0 ... 62 30 821]
[ 0 0 0 ... 24 3081 25]
...
[ 0 0 0 ... 19 666 3159]
[ 0 0 0 ... 7 15 1716]
[ 0 0 0 ... 1194 61 113]]
Shape of X train: (25000, 500)
Shape of X test: (25000, 500)
9. Реализовали модель рекуррентной нейронной сети, состоящей из слоев Embedding, LSTM, Dropout, Dense, и обучили ее на обучающих данных с выделением части обучающих данных в качестве валидационных. Вывели информацию об архитектуре нейронной сети. Добились качества обучения по метрике accuracy не менее 0.8.
embed_dim = 32
lstm_units = 64
model = Sequential()
model.add(layers.Embedding(input_dim=vocabulary_size, output_dim=embed_dim, input_length=max_words, input_shape=(max_words,)))
model.add(layers.LSTM(lstm_units))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
Model: "sequential_2"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ embedding_2 (Embedding) │ (None, 500, 32) │ 160,000 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ lstm_2 (LSTM) │ (None, 64) │ 24,832 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout_2 (Dropout) │ (None, 64) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_2 (Dense) │ (None, 1) │ 65 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 184,897 (722.25 KB)
Trainable params: 184,897 (722.25 KB)
Non-trainable params: 0 (0.00 B)
# компилируем и обучаем модель
batch_size = 64
epochs = 3
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.2)
Epoch 1/3
313/313 ━━━━━━━━━━━━━━━━━━━━ 8s 20ms/step - accuracy: 0.6648 - loss: 0.5901 - val_accuracy: 0.8204 - val_loss: 0.4243
Epoch 2/3
313/313 ━━━━━━━━━━━━━━━━━━━━ 7s 22ms/step - accuracy: 0.8623 - loss: 0.3341 - val_accuracy: 0.8492 - val_loss: 0.3553
Epoch 3/3
313/313 ━━━━━━━━━━━━━━━━━━━━ 6s 19ms/step - accuracy: 0.8987 - loss: 0.2659 - val_accuracy: 0.8632 - val_loss: 0.3416
<keras.src.callbacks.history.History at 0x7f1e723806b0>
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f"\nTest accuracy: {test_acc}")
782/782 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.8770 - loss: 0.3202
Test accuracy: 0.8710799813270569
10. Оценили качество обучения на тестовых данных:
- вывести значение метрики качества классификации на тестовых данных,
- вывести отчет о качестве классификации тестовой выборки.
- построить ROC-кривую по результату обработки тестовой выборки и вычислить площадь под ROC-кривой (AUC ROC).
#значение метрики качества классификации на тестовых данных
print(f"\nTest accuracy: {test_acc}")
Test accuracy: 0.8710799813270569
#отчет о качестве классификации тестовой выборки
y_score = model.predict(X_test)
y_pred = [1 if y_score[i,0]>=0.5 else 0 for i in range(len(y_score))]
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred, labels = [0, 1], target_names=['Negative', 'Positive']))
782/782 ━━━━━━━━━━━━━━━━━━━━ 5s 7ms/step
precision recall f1-score support
Negative 0.89 0.85 0.87 12500
Positive 0.86 0.89 0.87 12500
accuracy 0.87 25000
macro avg 0.87 0.87 0.87 25000
weighted avg 0.87 0.87 0.87 25000
#построение ROC-кривой и AUC ROC
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_test, y_score)
plt.plot(fpr, tpr)
plt.grid()
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC')
plt.show()
print('AUC ROC:', auc(fpr, tpr))
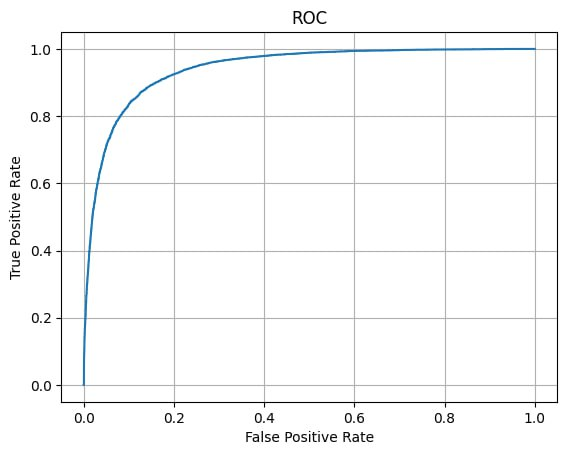
AUC ROC: 0.9419218976