12 KiB
Отчет по лабораторной работе №2
Артюшина Валерия, Хохлов Кирилл, А-01-22
Подготовка к работе
Номер бригады k = 4 N = 4 mod 3 = 1 Набор данных Letter
Задание 1
1. В среде GoogleColab создали блокнот(is_lab2.ipynb).
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/is_lab2')
- импорт модулей
import numpy as np
import lab02_lib as lib
2. Генерация набора двумерных данных
data = lib.datagen(4, 4, 1000, 2)
# вывод данных и размерности
print('Исходные данные:')
print(data)
print('Размерность данных:')
print(data.shape)

Исходные данные:
[[3.89754058 4.00467196]
[4.00996996 4.00696404]
[4.13181175 4.19264161]
...
[3.90249897 3.8890494 ]
[3.98817291 4.05824572]
[3.95966561 3.94263676]]
Размерность данных:
(1000, 2)
3. Создание и обучение автокодировщика AE1
patience = 100
ae1_trained, IRE1, IREth1 = lib.create_fit_save_ae(data,'out/AE1.h5','out/AE1_ire_th.txt',
500, True, patience)
Параметры архитектуры
Задать архитектуру автокодировщиков или использовать архитектуру по умолчанию? (1/2): 1
Задайте количество скрытых слоёв (нечетное число) : 3
Задайте архитектуру скрытых слоёв автокодировщика, например, в виде 3 1 3 : 3 1 3
4. Результаты обучения
Ошибка MSE, на которой обучение завершилось:
mse_stop_ae1 = 3.0205
# Построение графика ошибки реконструкции
lib.ire_plot('training', IRE1, IREth1, 'AE1')
 Порог ошибки реконструкции:
Порог ошибки реконструкции:
IREth1
np.float64(2.8)
5. Создание и обучение автокодировщика AE2
ae2_trained, IRE2, IREth2 = lib.create_fit_save_ae(data,'out/AE2.h5','out/AE2_ire_th.txt',
2000, True, patience)
lib.ire_plot('training', IRE2, IREth2, 'AE2')
6. Результаты обучения
Ошибка MSE, на которой обучение завершилось:
mse_stop_ae2 = 0.0121
# Построение графика ошибки реконструкции
lib.ire_plot('training', IRE2, IREth2, 'AE2')
 Порог ошибки реконструкции:
Порог ошибки реконструкции:
IREth2
np.float64(0.47)
7. Характеристики качества обучения
# построение областей покрытия и границ классов
# расчет характеристик качества обучения
numb_square = 20
xx, yy, Z1 = lib.square_calc(numb_square, data, ae1_trained, IREth1, '1', True)
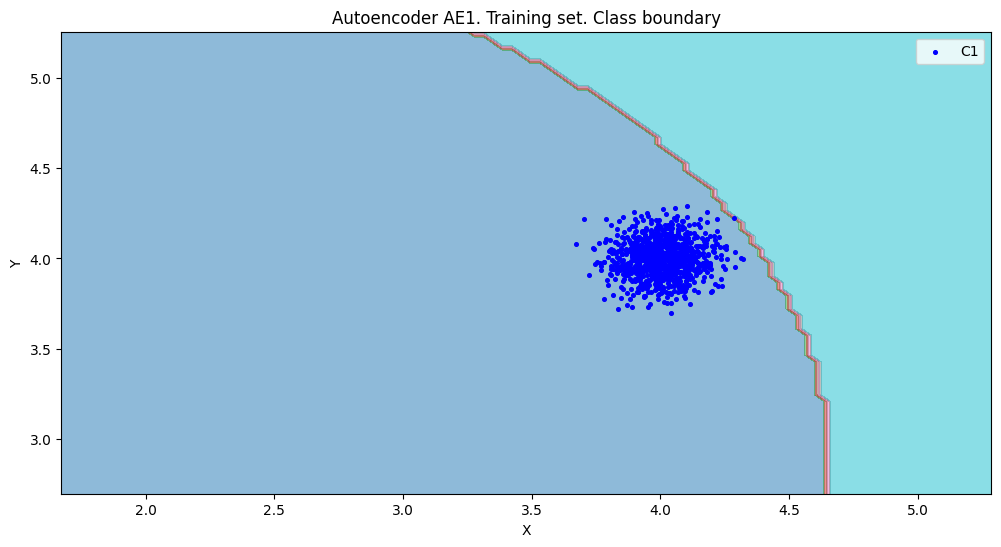 amount: 21
amount_ae: 294
amount: 21
amount_ae: 294

 Оценка качества AE1
Оценка качества AE1
IDEAL = 0. Excess: 13.0
IDEAL = 0. Deficit: 0.0
IDEAL = 1. Coating: 1.0
summa: 1.0
IDEAL = 1. Extrapolation precision (Approx): 0.07142857142857144
# построение областей покрытия и границ классов
# расчет характеристик качества обучения
numb_square = 20
xx, yy, Z2 = lib.square_calc(numb_square, data, ae2_trained, IREth2, '2', True)
 amount: 21
amount_ae: 39
amount: 21
amount_ae: 39

 Оценка качества AE2
Оценка качества AE2
IDEAL = 0. Excess: 0.8571428571428571
IDEAL = 0. Deficit: 0.0
IDEAL = 1. Coating: 1.0
summa: 1.0
IDEAL = 1. Extrapolation precision (Approx): 0.5384615384615385
# сравнение характеристик качества обучения и областей аппроксимации
lib.plot2in1(data, xx, yy, Z1, Z2)

- Вывод: при увеличении количества скрытых слоев - показатели качества улучшаются. Таким образом, для качественного обнаружения аномалий стоит использовать автокодировщик AE2.
9. Создание тестовой выборки
test_data = np.array([[3.5, 4.2], [3.2, 4], [4.1, 3], [3.5,3.5], [3, 4], [3.5, 4.5]])
test_data
array([[3.5, 4.2],
[3.2, 4. ],
[4.1, 3. ],
[3.5, 3.5],
[3. , 4. ],
[3.5, 4.5]])
10. Применение автокодировщиков к тестовым данным
# тестирование AE1
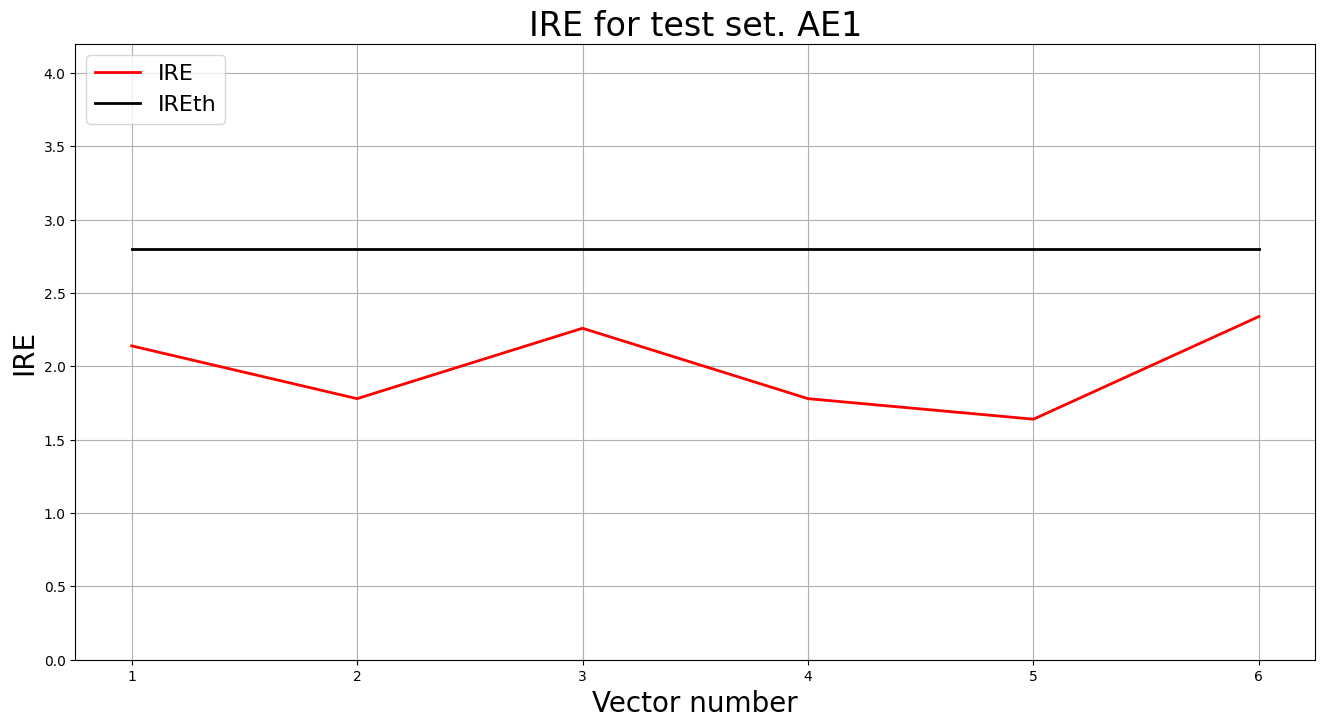
predicted_labels1, ire1 = lib.predict_ae(ae1_trained, test_data, IREth1)
lib.anomaly_detection_ae(predicted_labels1, ire1, IREth1)
lib.ire_plot('test', ire1, IREth1, 'AE1')
Аномалий не обнаружено
# тестирование AE2
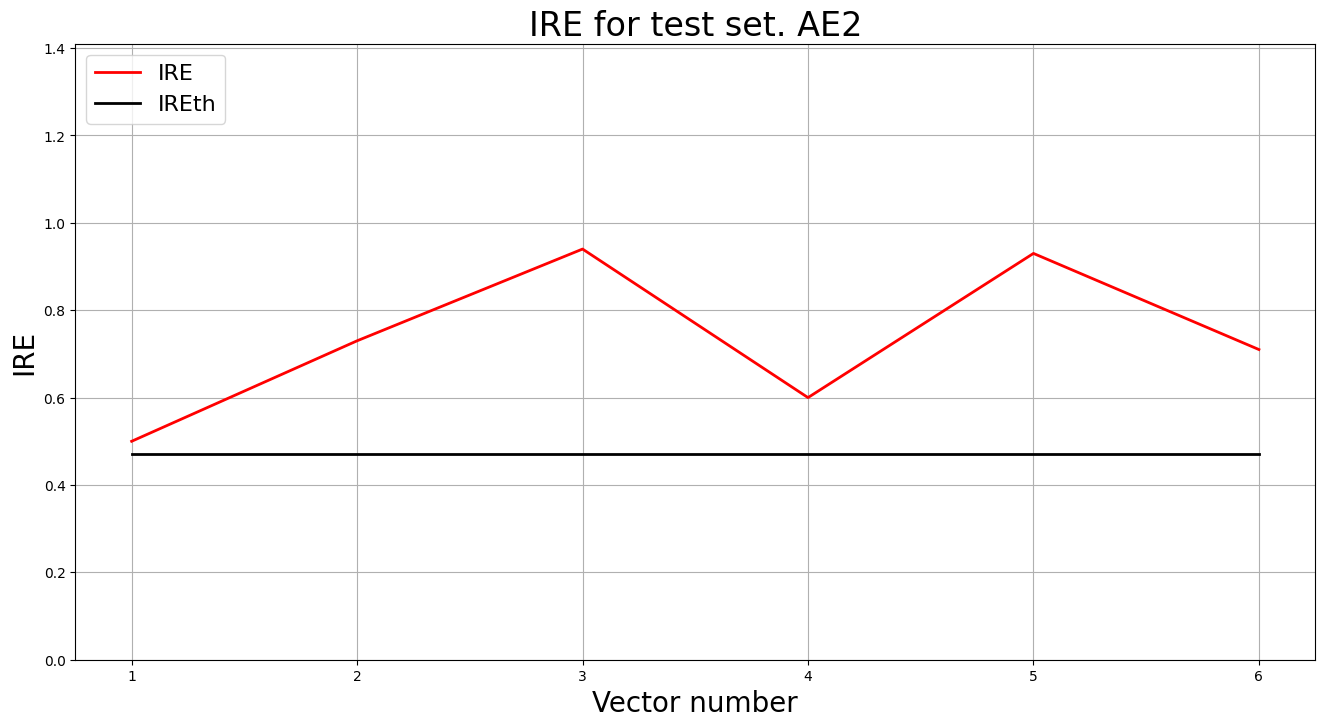
predicted_labels2, ire2 = lib.predict_ae(ae2_trained, test_data, IREth2)
lib.anomaly_detection_ae(predicted_labels2, ire2, IREth2)
lib.ire_plot('test', ire2, IREth2, 'AE2')
i Labels IRE IREth
0 [1.] [0.5] 0.47
1 [1.] [0.73] 0.47
2 [1.] [0.94] 0.47
3 [1.] [0.6] 0.47
4 [1.] [0.93] 0.47
5 [1.] [0.71] 0.47
Обнаружено 6.0 аномалий
11. Построение областей аппроксимации и точек тестового набора
lib.plot2in1_anomaly(data, xx, yy, Z1, Z2, test_data)

12. Результаты исследования
Табл. 1 Результаты задания №1.

13. Выводы о требованиях
Для успешного обучения автокодировщика для задачи одноклассовой классификации должны быть соблюдены следующие требования:
- Данные для обучения: данные должны быть без аномалий, чтобы автокодировщик смог рассчитать верное пороговое значение. Данные должны соответствовать одному классу и в пространстве признаков образовывать сплошной кластер
- Архитектура автокодировщика: автокодировщик должен содержать более одного внутреннего слоя. Архитектура автокодировщика имеет форму «бабочки»
- Количество эпох обучения: количество эпох обучения должно быть порядка тысяч. В рамках данного набора данных оптимально использовать 3000 с patience 300 эпох
- Ошибка MSE_stop: оптимальная ошибка для остановки обучения составляет 0,01 (для предотвращения переобучения)
- Ошибка реконструкции: должна быть минимальной
- Характеристики качества обучения EDCA: Excess не больше 0.5, Deficit = 0, Coating = 1, Approx не меньше 0.7
Задание 2
1. Набор данных Letter
Набор предназначен для распознавания черно-белых пиксельных прямоугольников как одну из 26 заглавных букв английского алфавита, где буквы алфавита представлены в 16 измерениях. (32 признака, 1600 примеров - 1500 нормальных, 100 аномальных)
2. Загрузка многомерной обучающей выборки
train = np.loadtxt('letter_train.txt', dtype=float)
3. Вывод данных и размерности
print('Исходные данные:')
print(train)
print('Размерность данных:')
print(train.shape)
Исходные данные:
[[ 6. 10. 5. ... 10. 2. 7.]
[ 0. 6. 0. ... 8. 1. 7.]
[ 4. 7. 5. ... 8. 2. 8.]
...
[ 7. 10. 10. ... 8. 5. 6.]
[ 7. 7. 10. ... 6. 0. 8.]
[ 3. 4. 5. ... 9. 5. 5.]]
Размерность данных:
(1500, 32)
4. Создание и обучение автокодировщика AE3 (100000 эпох)
patience= 20000
ae3_trained, IRE3, IREth3= lib.create_fit_save_ae(train,'out/AE3.h5','out/AE3_ire_th.txt', 100000, False, patience, early_stopping_delta = 0.001)
Параметры архитектуры
Задайте количество скрытых слоёв (нечетное число) : 9
Задайте архитектуру скрытых слоёв автокодировщика, например, в виде 3 1 3 : 64 48 32 24 16 24 32 48 64
5. Результаты обучения
Ошибка MSE, на которой обучение завершилось:
mse_stop_ae3 = 0.1056
# Построение графика ошибки реконструкции
lib.ire_plot('training', IRE3, IREth3, 'AE3')
 Порог ошибки реконструкции:
Порог ошибки реконструкции:
IREth3
np.float64(3.64)
6. Вывод о пригодности автокодировщика
Нейронная сеть обучена оптимально и порог обнаружения аномалий адекватно описывает границу области генеральной совокупности исследуемых данных.
7. Загрузка тестовой выборки
test = np.loadtxt('letter_test.txt', dtype=float)
# вывод данных и размерности
print('Исходные данные:')
print(test)
print('Размерность данных:')
print(test.shape)
Исходные данные:
[[ 8. 11. 8. ... 7. 4. 9.]
[ 4. 5. 4. ... 13. 8. 8.]
[ 3. 3. 5. ... 8. 3. 8.]
...
[ 4. 9. 4. ... 8. 3. 8.]
[ 6. 10. 6. ... 9. 8. 8.]
[ 3. 1. 3. ... 9. 1. 7.]]
Размерность данных:
(100, 32)
8. Применение автокодировщика к тестовым данным
#тестирование АE3
predicted_labels3, ire3 = lib.predict_ae(ae3_trained, test, IREth3)
#вывод результатов классификации
lib.anomaly_detection_ae(predicted_labels3, ire3, IREth3)
# Построение графика ошибки реконструкции
lib.ire_plot('test', ire3, IREth3, 'AE3')
Обнаружено 98.0 аномалий

10. Результаты обнаружения аномалий
Обнаружено более 70% аномалий, результаты удовлетворены.
10. Результаты исследования
Табл. 2 Результаты задания №2.

11. Выводы о требованиях
для качественного обнаружения аномалий в случае, когда размерность пространства признаков высока.
- Данные для обучения: должны быть без аномалий, чтобы автокодировщик смог рассчитать верное пороговое значение
- Архитектура автокодировщика: многомерный автокодировщик должен иметь достаточно большое количество внутренних слоев (в данном датасете не менее 7) и нейронов в них. Размеры определяются размерностью исходных данных.
- Количество эпох обучения: в рамках данного набора данных оптимальное кол-во эпох 100000 с patience 5000 эпох
- Ошибка MSE-stop: оптимальная ошибка MSE-stop 0.001
- Ошибка реконструкции: значение ошибки реконструкции должно как можно меньше