5.9 KiB
Индивидуальное контрольное задание по теме 9 вариант 6
Анисенков Павел А-01-23
Задание
- Создайте модуль М1, содержащий две функции:
-
функция 1: аргумент - словарь с исходными данными (ключи - страны, значения - списки с 2 значениями: население, объем некоторого ресурса); функция должна создать два списка: список стран и список с элементами - для каждой страны значение ресурса на душу населения, а также значение отношения суммарных ресурсов к суммарному населению;
-
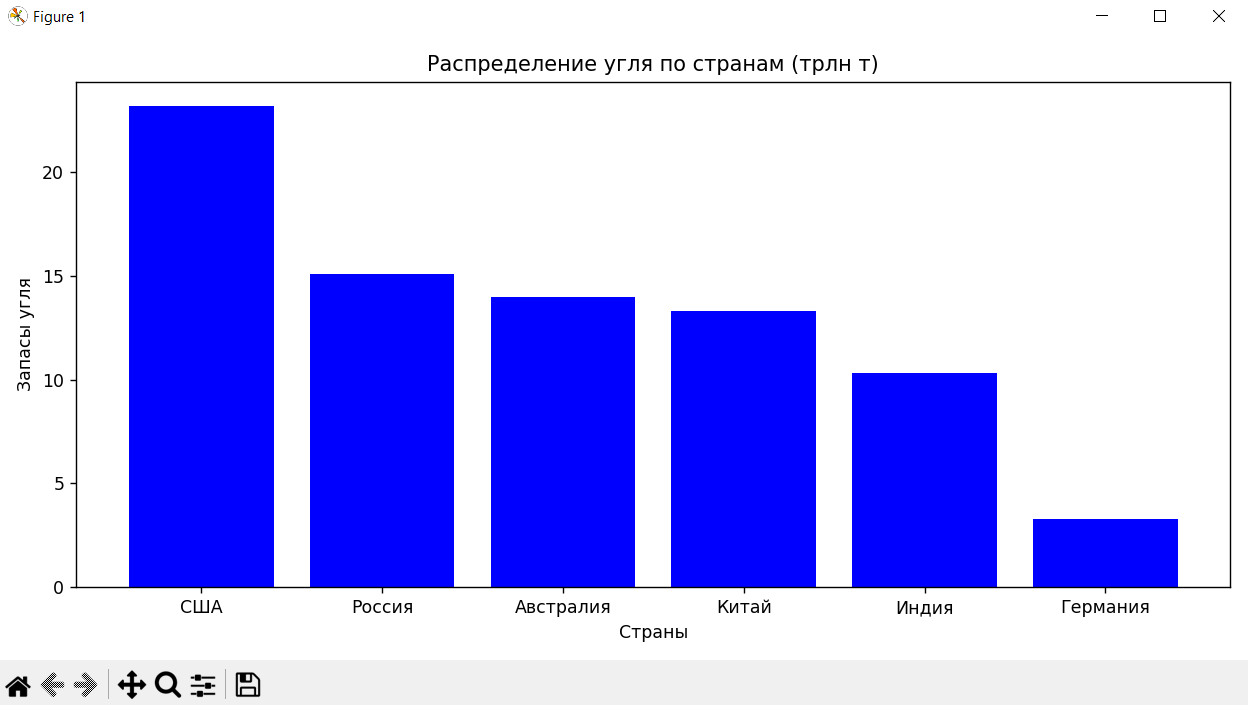
функция 2: аргумент - словарь, такой же, как в функции1; функция должна построить столбиковую диаграмму, демонстрирующую распределение ресурса по странам.
- Создайте еще один модуль М2, в котором должны выполняться операции:
-
запрашивается и вводится имя бинарного файла, проверяется его наличие, и если он существует, то из него считывается объект-словарь с исходными данными;
-
вызывается функция 1 и отображаются результаты;
-
вызывается функция 2.
-
Создайте модуль М0 - главную программу, которая вызывает М2 и после завершения ее работы записывает полученные результаты в текстовый файл Res3030.txt.
-
Проверьте программу с данными о запасах угля в разных странах:
США 302 23.2
Россия 146 15.1
Австралия 28 14
Китай 1443 13.3
Индия 1415 10.3
Германия 83 3.3
Решение
Сначала создадим бинарный файл с данными:
import pickle
data = {
"США": [302, 23.2],
"Россия": [146, 15.1],
"Австралия": [28, 14.0],
"Китай": [1443, 13.3],
"Индия": [1415, 10.3],
"Германия": [83, 3.3]
}
f = open("ugol.dat", "wb")
pickle.dump(data, f)
f.close()
print("Бинарный файл ugol.dat создан.")
M1
import pylab
def func1(data_dict):
"""
Аргумент: словарь {страна: [население, ресурс]}
Возвращает:
- список стран,
- список ресурс/душу,
- общее отношение суммарных ресурсов к суммарному населению
"""
countries = []
per_capita = []
total_pop = 0.0
total_res = 0.0
for country, values in data_dict.items():
pop = values[0]
res = values[1]
countries.append(country)
per_capita.append(res / pop if pop != 0 else 0)
total_pop += pop
total_res += res
overall_ratio = total_res / total_pop if total_pop != 0 else 0
return countries, per_capita, overall_ratio
def func2(data_dict):
"""
столбиковая диаграмма распределения ресурсов по странам.
"""
countries = list(data_dict.keys())
resources = []
for country in countries:
resources.append(data_dict[country][1])
pylab.figure(figsize=(10, 5))
pylab.bar(countries, resources, color='blue')
pylab.title("Распределение угля по странам (трлн т)")
pylab.xlabel("Страны")
pylab.ylabel("Запасы угля")
pylab.tight_layout()
pylab.show()
M2
import os
import pickle
from M1 import func1, func2
filename = input("Введите имя файла с данными: ").strip()
f = open(filename, "rb")
data = pickle.load(f)
f.close()
countries, per_capita, overall_ratio = func1(data)
print("\nСтраны и ресурс на душу населения:")
for i in range(len(countries)):
print(f"{countries[i]}: {per_capita[i]:.6f} трлн т/млн чел")
print(f"\nОбщее отношение суммарных ресурсов к суммарному населению: {overall_ratio:.6f}")
func2(data)
result_countries = countries
result_per_capita = per_capita
result_overall = overall_ratio
result_data = data
M0
import os
import M2
output_lines = []
output_lines.append("Результаты анализа данных о запасах угля")
for country, value in zip(M2.result_countries, M2.result_per_capita):
line = f"{country}: {value:.6f} трлн т/млн чел"
output_lines.append(line)
output_lines.append(f"\nОбщее отношение ресурсов к населению: {M2.result_overall:.6f}")
f = open("Res3030.txt", "w", encoding="utf-8")
for line in output_lines:
f.write(line + "\n")
f.close()
print("\nРезультаты записаны в файл Res3030.txt")
Отображение результата:
Введите имя файла с данными: ugol.dat
Страны и ресурс на душу населения:
США: 0.076821 трлн т/млн чел
Россия: 0.103425 трлн т/млн чел
Австралия: 0.500000 трлн т/млн чел
Китай: 0.009217 трлн т/млн чел
Индия: 0.007279 трлн т/млн чел
Германия: 0.039759 трлн т/млн чел
Общее отношение суммарных ресурсов к суммарному населению: 0.023178
Результаты записаны в файл Res3030.txt