форкнуто от main/is_dnn
Вы не можете выбрать более 25 тем
Темы должны начинаться с буквы или цифры, могут содержать дефисы(-) и должны содержать не более 35 символов.
20 KiB
20 KiB
Лабораторная работа №4: Распознавание последовательностей
Аникеев А.А; Чагин С.А. — А-02-22
Номер бригады - 5
Цель работы
Получить практические навыки обработки текстовой информации с помощью рекуррентных искусственных нейронных сетей при решении задачи определения тональности текста.
Определение варианта
- Номер бригады: k = 5
- random_state = (4k - 1) = 19
Подготовка среды
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/IS_LR4')
Пункт №1. Настройка блокнота для работы с аппаратным ускорителем GPU.
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Пункт №2. Загрузка набора данных IMDb.
# загрузка датасета
from keras.datasets import imdb
vocabulary_size = 5000
index_from = 3
(X_train, y_train), (X_test, y_test) = imdb.load_data(path="imdb.npz",
num_words=vocabulary_size,
skip_top=0,
maxlen=None,
seed=19,
start_char=1,
oov_char=2,
index_from=index_from
)
Результат выполнения:
Размер обучающего множества X_train: (25000,)
Размер обучающих меток y_train: (25000,)
Размер тестового множества X_test: (25000,)
Размер тестовых меток y_test: (25000,)
Пункт №3. Вывод отзывов из обучающего множества в виде списка индексов слов.
# создание словаря для перевода индексов в слова
# заргузка словаря "слово:индекс"
word_to_id = imdb.get_word_index()
# уточнение словаря
word_to_id = {key:(value + index_from) for key,value in word_to_id.items()}
word_to_id["<PAD>"] = 0
word_to_id["<START>"] = 1
word_to_id["<UNK>"] = 2
word_to_id["<UNUSED>"] = 3
# создание обратного словаря "индекс:слово"
id_to_word = {value:key for key,value in word_to_id.items()}
idx = 19
review_indices = X_train[idx]
print("Отзыв в виде индексов:\n", review_indices)
review_text = " ".join(id_to_word.get(i, "?") for i in review_indices)
print("\nОтзыв в виде текста:\n", review_text)
print("\nДлина отзыва (количество индексов):", len(review_indices))
label = y_train[idx]
class_name = "Positive" if label == 1 else "Negative"
print("Метка класса:", label, "| Класс:", class_name)
Результат выполнения:
Отзыв в виде индексов:
[1, 13, 296, 14, 22, 171, 211, 5, 32, 13, 70, 135, 15, 14, 9, 364, 352, 1916, 5, 15, 12, 127, 24, 28, 233, 8, 81, 19, 6, 147, 479, 2309, 156, 354, 9, 55, 338, 21, 12, 9, 959, 7, 1763, 116, 4361, 259, 37, 296, 14, 22, 150, 242, 104, 7, 2145, 17, 49, 932, 2, 2, 37, 620, 19, 6, 1056, 40, 49, 4618, 2112, 13, 70, 64, 8, 135, 15, 50, 9, 76, 128, 108, 44, 2145, 5, 2321, 11, 148, 153, 5, 15, 2200, 7, 445, 9, 55, 76, 467, 856, 13, 70, 386, 1124, 22, 2, 11, 63, 25, 70, 67, 530, 239, 7, 2, 284, 2, 2, 11, 6, 1686, 7, 2, 2145]
Отзыв в виде текста:
<START> i watched this film few times and all i can say that this is low budget rubbish and that it does not have anything to do with a real history facts actors performances is very poor but it is result of limited acting possibilities anyone who watched this film now probably think of hitler as some crazy <UNK> <UNK> who running with a gun like some chicago gangster i can only to say that there is much better films about hitler and germany in those years and that rise of evil is very much under average i can recommend german film <UNK> in which you can see brilliant performance of <UNK> actor <UNK> <UNK> in a roll of <UNK> hitler
Длина отзыва (количество индексов): 121
Метка класса: 0 | Класс: Negative
Пункт №4. Вывод максимальной и минимальной длины отзыва в обучающем множестве.
print("Максимальная длина отзыва:", len(max(X_train, key=len)))
print("Минимальная длина отзыва:", len(min(X_train, key=len)))
Результат выполнения:
Максимальная длина отзыва: 2494
Минимальная длина отзыва: 11
Пункт №5. Проведение предобработки данных.
# предобработка данных
from tensorflow.keras.utils import pad_sequences
max_words = 500
X_train = pad_sequences(X_train, maxlen=max_words, value=0, padding='pre', truncating='post')
X_test = pad_sequences(X_test, maxlen=max_words, value=0, padding='pre', truncating='post')
Пункт №6. Повторение пункта 4.
print("Максимальная длина отзыва после предобработки:", len(max(X_train, key=len)))
print("Минимальная длина отзыва после предобработки:", len(min(X_train, key=len)))
Результат выполнения:
Максимальная длина отзыва после предобработки: 500
Минимальная длина отзыва после предобработки: 500
Пункт №7. Повторение пункта 3.
idx = 19
review_indices = X_train[idx]
print("Отзыв в виде индексов:\n", review_indices)
review_text = " ".join(id_to_word.get(i, "?") for i in review_indices)
print("\nОтзыв в виде текста:\n", review_text)
print("\nДлина отзыва (количество индексов):", len(review_indices))
label = y_train[idx]
class_name = "Positive" if label == 1 else "Negative"
print("Метка класса:", label, "| Класс:", class_name)
Результат выполнения:
Отзыв в виде индексов:
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 1 13 296 14 22 171 211 5 32 13 70 135 15
14 9 364 352 1916 5 15 12 127 24 28 233 8 81
19 6 147 479 2309 156 354 9 55 338 21 12 9 959
7 1763 116 4361 259 37 296 14 22 150 242 104 7 2145
17 49 932 2 2 37 620 19 6 1056 40 49 4618 2112
13 70 64 8 135 15 50 9 76 128 108 44 2145 5
2321 11 148 153 5 15 2200 7 445 9 55 76 467 856
13 70 386 1124 22 2 11 63 25 70 67 530 239 7
2 284 2 2 11 6 1686 7 2 2145
Отзыв в виде текста:
<PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <START> i watched this film few times and all i can say that this is low budget rubbish and that it does not have anything to do with a real history facts actors performances is very poor but it is result of limited acting possibilities anyone who watched this film now probably think of hitler as some crazy <UNK> <UNK> who running with a gun like some chicago gangster i can only to say that there is much better films about hitler and germany in those years and that rise of evil is very much under average i can recommend german film <UNK> in which you can see brilliant performance of <UNK> actor <UNK> <UNK> in a roll of <UNK> hitler
Длина отзыва (количество индексов): 500
Метка класса: 0 | Класс: Negative
Вывод:
После предобработки длина всех отзывов была приведена к 500 словам. Рассматриваемый отзыв был дополнен нулями (<PAD>) в начале,
так как его исходная длина была меньше выбранного максимума. Обрезания текста не произошло.
Функция pad_sequences выровняла все отзывы к единой длине.
Пункт №8. Вывод предобработанных массивов обучающих и тестовых данных.
print("Предобработанное обучающее множество X_train (первые 5 примеров):")
print(X_train[:5])
print("\nПредобработанное тестовое множество X_test (первые 5 примеров):")
print(X_test[:5])
print("Размер обучающего множества X_train:", X_train.shape)
print("Размер обучающих меток y_train:", y_train.shape)
print("Размер тестового множества X_test:", X_test.shape)
print("Размер тестовых меток y_test:", y_test.shape)
Результат выполнения:
Предобработанное обучающее множество X_train (первые 5 примеров):
[ 0 0 0 ... 786 7 12]
[ 0 0 0 ... 35 709 790]
[ 0 0 0 ... 11 4 2]
[ 0 0 0 ... 358 4 2]
[ 0 0 0 ... 2 3174 2]
Предобработанное тестовое множество X_test (первые 5 примеров):
[ 0 0 0 ... 67 14 20]
[ 0 0 0 ... 48 24 6]
[ 1 146 6 ... 15 12 16]
[ 0 0 0 ... 141 17 134]
[ 1 12 9 ... 320 7 51]
Размер обучающего множества X_train: (25000, 500)
Размер обучающих меток y_train: (25000,)
Размер тестового множества X_test: (25000, 500)
Размер тестовых меток y_test: (25000,)
Пункт №9. Реализация модели рекуррентной нейронной сети.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dropout, Dense
vocabulary_size = 5000
embedding_dim = 32
lstm_units = 64
dropout_rate = 0.5
model = Sequential()
model.add(Embedding(
input_dim=vocabulary_size + index_from,
output_dim=embedding_dim,
input_length=max_words
))
model.add(LSTM(lstm_units))
model.add(Dropout(dropout_rate))
model.add(Dense(1, activation='sigmoid'))
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
model.build(input_shape=(None, max_words))
model.summary()
# Обучение модели
history = model.fit(
X_train,
y_train,
epochs=5,
batch_size=64,
validation_split=0.2,
verbose=1
)
Результат выполнения:
| Layer (type) | Output Shape | Param # |
|---|---|---|
| embedding_3 (Embedding) | (None, 500, 32) | 160,096 |
| lstm_3 (LSTM) | (None, 64) | 24,832 |
| dropout_3 (Dropout) | (None, 64) | 0 |
| dense_3 (Dense) | (None, 1) | 65 |
Total params: 184,993 (722.63 KB)
Trainable params: 184,993 (722.63 KB)
Non-trainable params: 0 (0.00 B)
Качество обучения по эпохам
Эпоха 1: accuracy = 0.9302, val_accuracy = 0.8686
Эпоха 2: accuracy = 0.9298, val_accuracy = 0.8416
Эпоха 3: accuracy = 0.9351, val_accuracy = 0.8576
Эпоха 4: accuracy = 0.9311, val_accuracy = 0.8678
Эпоха 5: accuracy = 0.9522, val_accuracy = 0.8670
Добились качества обучения по метрике accuracy не менее 0.8.
Пункт №10.1 Оценка качества обучения на тестовых данных.
test_loss, test_accuracy = model.evaluate(X_test, y_test, verbose=0)
print("Качество классификации на тестовой выборке")
print(f"Test accuracy: {test_accuracy:.4f}")
Результат выполнения:
Качество классификации на тестовой выборке
Test accuracy: 0.8607
Пункт №10.2
y_score = model.predict(X_test)
y_pred = [1 if y_score[i,0]>=0.5 else 0 for i in range(len(y_score))]
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred, labels = [0, 1], target_names=['Negative', 'Positive']))
Результат выполнения:
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Negative | 0.84 | 0.89 | 0.86 | 12500 |
| Positive | 0.88 | 0.83 | 0.86 | 12500 |
| Macro Avg | 0.86 | 0.86 | 0.86 | 25000 |
| Weighted Avg | 0.86 | 0.86 | 0.86 | 25000 |
accuracy: 0.86 25000
Пункт №10.3
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
fpr, tpr, thresholds = roc_curve(y_test, y_score)
plt.plot(fpr, tpr)
plt.grid()
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC')
plt.show()
print('Area under ROC is', auc(fpr, tpr))
Результат выполнения:
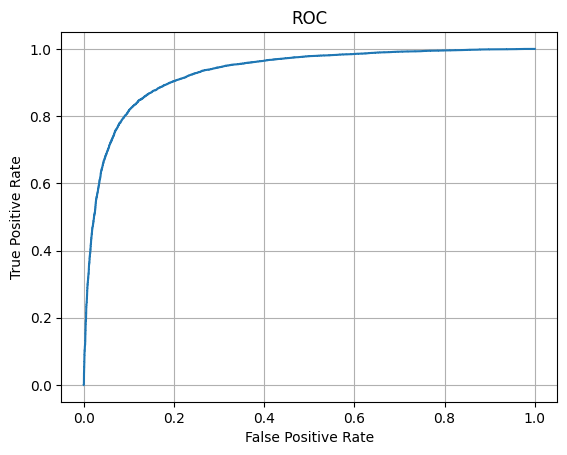
Area under ROC is 0.9304564479999999
Пункт №11. Выводы по результатам применения рекуррентной нейронной сети.
Выводы по лабораторной работе:
В ходе выполнения лабораторной работы была построена и обучена рекуррентная нейронная сеть на основе слоя LSTM для решения задачи определения тональности текстов из датасета IMDb. После предварительной обработки данных (приведение длины отзывов к фиксированному размеру и преобразование слов в числовые индексы) модель успешно обучилась классифицировать отзывы на положительные и отрицательные.
По итогам эксперимента качество модели на тестовой выборке составило accuracy ≈ 0.86, что означает, что сеть правильно классифицировала около 86% отзывов. Анализ отчёта о качестве классификации (precision, recall, f1-score) показал, что модель обеспечивает близкие значения метрик для обоих классов.
ROC-кривая модели проходит значительно выше диагонали случайного классификатора, а значение AUC ROC ≈ 0.93 указывает на высокую способность модели различать положительные и отрицательные отзывы.
Таким образом, использование рекуррентной нейронной сети, основанной на LSTM, оказалось эффективным для анализа тональности текста. Модель успешно улавливает зависимости в последовательностях слов и демонстрирует высокое качество классификации. Данная архитектура подходит для практических задач анализа текста, таких как фильтрация отзывов, определение эмоциональной окраски сообщений или анализ пользовательских комментариев.