22 KiB
Лабораторная работа №3: Распознавание изображений
Аникеев А.А; Чагин С.А. — А-02-22
Номер бригады - 5
Цель работы
Получить практические навыки создания, обучения и применения сверточных нейронных сетей для распознавания изображений. Познакомиться с классическими показателями качества классификации.
Определение варианта
- Номер бригады: k = 5
- random_state = (4k - 1) = 19
Подготовка среды
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/IS_LR3')
ЗАДАНИЕ 1
Пункт №1. Импорт необходимых для работы библиотек и модулей.
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
Пункт №2. Загрузка набора данных MNIST.
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
Пункт №3. Разбиение набора данных на обучающие и тестовые данные.
# создание своего разбиения датасета
from sklearn.model_selection import train_test_split
# объединяем в один набор
X = np.concatenate((X_train, X_test))
y = np.concatenate((y_train, y_test))
# разбиваем по вариантам
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 10000,
train_size = 60000,
random_state = 19)
# вывод размерностей
print('Shape of X train:', X_train.shape)
print('Shape of y train:', y_train.shape)
print('Shape of X test:', X_test.shape)
print('Shape of y test:', y_test.shape)
Результат выполнения:
Shape of X train: (60000, 28, 28)
Shape of y train: (60000,)
Shape of X test: (10000, 28, 28)
Shape of y test: (10000,)
Пункт №4. Проведене предобработки данных.
# Зададим параметры данных и модели
num_classes = 10
input_shape = (28, 28, 1)
# Приведение входных данных к диапазону [0, 1]
X_train = X_train / 255
X_test = X_test / 255
# Расширяем размерность входных данных, чтобы каждое изображение имело
# размерность (высота, ширина, количество каналов)
X_train = np.expand_dims(X_train, -1)
X_test = np.expand_dims(X_test, -1)
print('Shape of transformed X train:', X_train.shape)
print('Shape of transformed X test:', X_test.shape)
# переведем метки в one-hot
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('Shape of transformed y train:', y_train.shape)
print('Shape of transformed y test:', y_test.shape)
Результат выполнения:
Shape of transformed X train: (60000, 28, 28, 1)
Shape of transformed X test: (10000, 28, 28, 1)
Shape of transformed y train: (60000, 10)
Shape of transformed y test: (10000, 10)
Пункт №5. Реализация модели сверточной нейронной сети и ее обучение.
# создаем модель
model = Sequential()
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Dropout(0.5))
model.add(layers.Flatten())
model.add(layers.Dense(num_classes, activation="softmax"))
model.summary()
Результат выполнения:
| Layer (type) | Output Shape | Param # |
|---|---|---|
| conv2d (Conv2D) | (None, 26, 26, 32) | 320 |
| max_pooling2d (MaxPooling2D) | (None, 13, 13, 32) | 0 |
| conv2d_1 (Conv2D) | (None, 11, 11, 64) | 18,496 |
| max_pooling2d_1 (MaxPooling2D) | (None, 5, 5, 64) | 0 |
| dropout (Dropout) | (None, 5, 5, 64) | 0 |
| flatten (Flatten) | (None, 1600) | 0 |
| dense (Dense) | (None, 10) | 16,010 |
Model: "sequential" Total params: 34,826 (136.04 KB) Trainable params: 34,826 (136.04 KB) Non-trainable params: 0 (0.00 B)
batch_size = 512
epochs = 15
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
Пункт №6. Оценка качества обучения на тестовых данных.
# Оценка качества работы модели на тестовых данных
scores = model.evaluate(X_test, y_test)
print('Loss on test data:', scores[0])
print('Accuracy on test data:', scores[1])
Результат выполнения:
accuracy: 0.9885 - loss: 0.0418
Loss on test data: 0.04163474589586258
Accuracy on test data: 0.988099992275238
Пункт №7. Выведение изображения, истинных меток и результатов распознавания.
# вывод первого тестового изображения и результата распознавания
n = 222
result = model.predict(X_test[n:n+1])
print('NN output:', result)
plt.show()
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
print('Real mark: ', np.argmax(y_test[n]))
print('NN answer: ', np.argmax(result))
Результат выполнения:
NN output: [[4.3116913e-08 3.3146053e-13 2.1031238e-07 4.8524967e-06 4.2155320e-06 1.1801652e-05 3.3284198e-11 2.9875573e-05 2.4400490e-06 9.9994659e-01]]
Real mark: 9
NN answer: 9
# вывод второго тестового изображения и результата распознавания
n = 111
result = model.predict(X_test[n:n+1])
print('NN output:', result)
plt.show()
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray'))
print('Real mark: ', np.argmax(y_test[n]))
print('NN answer: ', np.argmax(result))
Результат выполнения:
NN output: [[1.5492931e-13 8.0427107e-16 6.5475694e-14 3.2799780e-06 1.5800725e-14 9.9999642e-01 1.6747580e-12 1.4161887e-15 1.3768246e-07 1.1293472e-07]]
Real mark: 5
NN answer: 5
Пункт №8. Вывод отчета о качестве классификации тестовой выборки.
# истинные метки классов
true_labels = np.argmax(y_test, axis=1)
# предсказанные метки классов
predicted_labels = np.argmax(model.predict(X_test), axis=1)
# отчет о качестве классификации
print(classification_report(true_labels, predicted_labels))
# вычисление матрицы ошибок
conf_matrix = confusion_matrix(true_labels, predicted_labels)
# отрисовка матрицы ошибок в виде "тепловой карты"
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix)
display.plot()
plt.show()
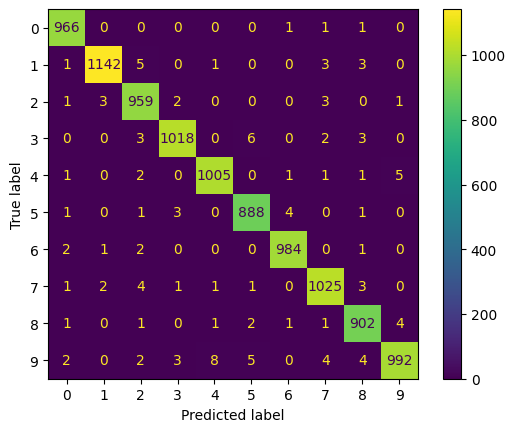
Результат выполнения:
precision recall f1-score support
0 0.99 1.00 0.99 969
1 0.99 0.99 0.99 1155
2 0.98 0.99 0.98 969
3 0.99 0.99 0.99 1032
4 0.99 0.99 0.99 1016
5 0.98 0.99 0.99 898
6 0.99 0.99 0.99 990
7 0.99 0.99 0.99 1038
8 0.98 0.99 0.98 913
9 0.99 0.97 0.98 1020
accuracy 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000
Пункт №9. Подача на вход обученной нейронной сети собственного изображения.
# загрузка собственного изображения 1
from PIL import Image
file_data = Image.open('test.png')
file_data = file_data.convert('L') # перевод в градации серого
test_img = np.array(file_data)
# вывод собственного изображения
plt.imshow(test_img, cmap=plt.get_cmap('gray'))
plt.show()
# предобработка
test_img = test_img / 255
test_img = np.reshape(test_img, (1,28,28,1))
# распознавание
result = model.predict(test_img)
print('I think it\'s ', np.argmax(result))
Результат выполнения:
I think it's 5
# загрузка собственного изображения 2
from PIL import Image
file_data = Image.open('test_2.png')
file_data = file_data.convert('L') # перевод в градации серого
test_img = np.array(file_data)
# вывод собственного изображения
plt.imshow(test_img, cmap=plt.get_cmap('gray'))
plt.show()
# предобработка
test_img = test_img / 255
test_img = np.reshape(test_img, (1,28,28,1))
# распознавание
result = model.predict(test_img)
print('I think it\'s ', np.argmax(result))
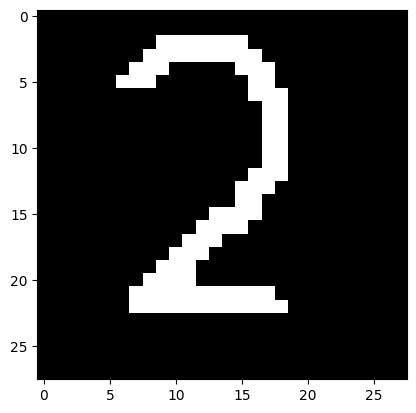
Результат выполнения:
I think it's 2
Пункт №10. Загрузка с диска модели, сохраненной при выполнении лабораторной работы №1.
# путь к сохранённой модели из ЛР1
model_fc = keras.models.load_model('/content/drive/MyDrive/Colab Notebooks/best_model/model100.keras')
# архитектура модели
model_fc.summary()
Результат выполнения:
| Layer (type) | Output Shape | Param # |
|---|---|---|
| dense_19 (Dense) | (None, 100) | 78,500 |
| dense_20 (Dense) | (None, 10) | 1,010 |
Model: "sequential_10"
Total params: 79,512 (310.60 KB)
Trainable params: 79,510 (310.59 KB)
Non-trainable params: 0 (0.00 B)
Optimizer params: 2 (12.00 B)
# подготовка тестовых данных для полносвязной модели
X_test_fc = X_test.reshape(X_test.shape[0], 28*28) # (10000, 784)
y_test_fc = y_test # если в ЛР3 ты уже перевёл метки в one-hot
# оценка качества, как в п. 6
scores = model_fc.evaluate(X_test_fc, y_test_fc, verbose=0)
print('Loss on test data (FC model):', scores[0])
print('Accuracy on test data (FC model):', scores[1])
Результат выполнения:
Loss on test data (FC model): 0.19745591282844543
Accuracy on test data (FC model): 0.9442999958992004
Пункт №11. Сравнение обученной модели сверточной сети и наилучшей модели полносвязной сети из лабораторной работы №1.
Сравнение моделей:
Количество настраиваемых параметров в сети:
Сверточная сеть: 34 826 параметров.
Полносвязная сеть: 79 512 параметров.
При том что число параметров сверточной сети меньше в 2 раза, она показывает более высокие результаты. Это связано с более эффективным использовании весов за счёт свёрток и фильтров.
Количество эпох обучения:
Сверточная сеть обучалась 15 эпох.
Полносвязная сеть обучалась 100 эпох.
Cверточная модель достигает лучшего результата при меньшем количестве эпох, то есть сходится быстрее и обучается эффективнее.
Качество классификации тестовой выборки:
Сверточная сеть: Accuracy ≈ 0.988, loss ≈ 0.042.
Полносвязная сеть: Accuracy ≈ 0.944, loss ≈ 0.197.
Сверточная нейросеть точнее на 4,5 процента, при этом её ошибка почти в 5 раз меньше.
Вывод:
Использование сверточной нейронной сети для распознавания изображений даёт ощутимо лучший результат по сравнению с полносвязной моделью. CNN требует меньше параметров, быстрее обучается и точнее распознаёт изображения, поскольку учитывает их структуру и выделяет важные визуальные особенности.
ЗАДАНИЕ 2
Пункт №1. Импорт необходимых для работы библиотек и модулей.
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
Пункт №2. Загрузка набора данных CIFAR-10.
from keras.datasets import cifar10
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
Пункт №3. Разбиение набора данных на обучающие и тестовые данные.
# создание своего разбиения датасета
from sklearn.model_selection import train_test_split
# объединяем в один набор
X = np.concatenate((X_train, X_test))
y = np.concatenate((y_train, y_test))
# разбиваем по вариантам
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 10000,
train_size = 50000,
random_state = 19)
# вывод размерностей
print('Shape of X train:', X_train.shape)
print('Shape of y train:', y_train.shape)
print('Shape of X test:', X_test.shape)
print('Shape of y test:', y_test.shape)
Результат выполнения:
Shape of X train: (50000, 32, 32, 3)
Shape of y train: (50000, 1)
Shape of X test: (10000, 32, 32, 3)
Shape of y test: (10000, 1)
# вывод 25 изображений из обучающей выборки с подписями классов
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(X_train[i])
plt.xlabel(class_names[y_train[i][0]])
plt.show()

Пункт №4. Проведене предобработки данных.
# Зададим параметры данных и модели
num_classes = 10
input_shape = (32, 32, 3)
# Приведение входных данных к диапазону [0, 1]
X_train = X_train / 255
X_test = X_test / 255
# Расширяем размерность входных данных, чтобы каждое изображение имело
# размерность (высота, ширина, количество каналов)
print('Shape of transformed X train:', X_train.shape)
print('Shape of transformed X test:', X_test.shape)
# переведем метки в one-hot
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('Shape of transformed y train:', y_train.shape)
print('Shape of transformed y test:', y_test.shape)
Результат выполнения:
Shape of transformed X train: (50000, 32, 32, 3)
Shape of transformed X test: (10000, 32, 32, 3)
Shape of transformed y train: (50000, 10)
Shape of transformed y test: (10000, 10)
Пункт №5. Реализация модели сверточной нейронной сети и ее обучение.
# создаем модель
model = Sequential()
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu"))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(128, kernel_size=(3, 3), activation="relu"))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(num_classes, activation="softmax"))
model.summary()
Результат выполнения:
| Layer (type) | Output Shape | Param # |
|---|---|---|
| conv2d_2 (Conv2D) | (None, 30, 30, 32) | 896 |
| max_pooling2d_2 (MaxPooling2D) | (None, 15, 15, 32) | 0 |
| conv2d_3 (Conv2D) | (None, 13, 13, 64) | 18,496 |
| max_pooling2d_3 (MaxPooling2D) | (None, 6, 6, 64) | 0 |
| conv2d_4 (Conv2D) | (None, 4, 4, 128) | 73,856 |
| max_pooling2d_4 (MaxPooling2D) | (None, 2, 2, 128) | 0 |
| flatten_1 (Flatten) | (None, 512) | 0 |
| dense_1 (Dense) | (None, 128) | 65,664 |
| dropout_1 (Dropout) | (None, 128) | 0 |
| dense_2 (Dense) | (None, 10) | 1,290 |
Model: "sequential_1"
Total params: 160,202 (625.79 KB)
Trainable params: 160,202 (625.79 KB)
Non-trainable params: 0 (0.00 B)
batch_size = 512
epochs = 15
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
Пункт №6. Оценка качества обучения на тестовых данных.
# Оценка качества работы модели на тестовых данных
scores = model.evaluate(X_test, y_test)
print('Loss on test data:', scores[0])
print('Accuracy on test data:', scores[1])
Результат выполнения:
accuracy: 0.6676 - loss: 0.9584
Loss on test data: 0.9374598860740662
Accuracy on test data: 0.6726999878883362
Пункт №7. Выведение изображения, истинных меток и результатов распознавания.
# правильно распознанное изображение
n = 0
result = model.predict(X_test[n:n+1])
print('NN output:', result)
plt.imshow(X_test[n])
plt.show()
print('Real class: ', np.argmax(y_test[n]), '->', class_names[np.argmax(y_test[n])])
print('NN answer:', np.argmax(result), '->', class_names[np.argmax(result)])
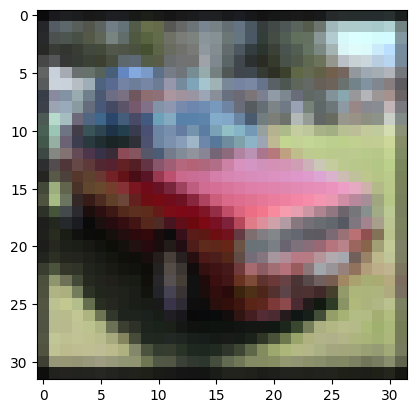
Результат выполнения:
NN output: [[1.2349103e-03 8.2268691e-01 1.0979634e-03 2.3796519e-03 1.2556769e-02 6.0236914e-04 1.7611842e-03 1.2650734e-03 3.5482903e-03 1.5286703e-01]]
Real class: 1 -> automobile
NN answer: 1 -> automobile
# неверно распознанное изображение
n = 9
result = model.predict(X_test[n:n+1])
print('NN output:', result)
plt.imshow(X_test[n])
plt.show()
print('Real class: ', np.argmax(y_test[n]), '->', class_names[np.argmax(y_test[n])])
print('NN answer:', np.argmax(result), '->', class_names[np.argmax(result)])

Результат выполнения:
NN output: [[0.00157286 0.2169207 0.03160945 0.03033627 0.00178993 0.06459528 0.0421534 0.00500837 0.00139859 0.60461515]]
Real class: 1 -> automobile
NN answer: 9 -> truck
Пункт №8. Вывод отчета о качестве классификации тестовой выборки.
# истинные метки классов
true_labels = np.argmax(y_test, axis=1)
# предсказанные метки классов
predicted_labels = np.argmax(model.predict(X_test), axis=1)
# отчет о качестве классификации
print(classification_report(true_labels, predicted_labels, target_names=class_names))
# вычисление матрицы ошибок
conf_matrix = confusion_matrix(true_labels, predicted_labels)
# отрисовка матрицы ошибок в виде "тепловой карты"
display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix,
display_labels=class_names)
display.plot(xticks_rotation=45)
plt.show()

Результат выполнения:
precision recall f1-score support
airplane 0.64 0.76 0.70 1015
automobile 0.74 0.85 0.79 1015
bird 0.55 0.58 0.56 1008
cat 0.52 0.42 0.46 966
deer 0.65 0.61 0.63 1026
dog 0.56 0.62 0.58 985
frog 0.75 0.74 0.74 946
horse 0.75 0.71 0.73 1007
ship 0.78 0.77 0.78 1012
truck 0.80 0.68 0.74 1020
accuracy 0.67 10000
macro avg 0.67 0.67 0.67 10000
weighted avg 0.67 0.67 0.67 10000