39 KiB
Лабораторная работа №2: Обнаружение аномалий с помощью автокодировщиков
Аникеев А.А; Чагин С.А. — А-02-22
Вариант 2 (номер бригады k=5) - данные WBC
Цель работы
Получить практические навыки создания, обучения и применения искусственных нейронных сетей типа автокодировщик. Исследовать влияние архитектуры автокодировщика и количества эпох обучения на области в пространстве признаков, распознаваемые автокодировщиком после обучения. Научиться оценивать качество обучения автокодировщика на основе ошибки реконструкции и новых метрик EDCA. Научиться решать актуальную задачу обнаружения аномалий в данных с помощью автокодировщика как одноклассового классификатора.
Определение варианта
- Номер бригады: k = 5
- N = k mod 3 = 5 mod 3 = 2
- Вариант 2 => данные WBC
Подготовка среды
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks')
from google.colab import drive
drive.mount('/content/drive')
import os
work_dir = '/content/drive/MyDrive/Colab Notebooks/is_lab2'
os.makedirs(work_dir, exist_ok=True)
os.chdir(work_dir)
os.makedirs('out', exist_ok=True)
dataset_name = 'WBC'
base_url = "http://uit.mpei.ru/git/main/is_dnn/raw/branch/main/labworks/LW2/"
!wget -N {base_url}lab02_lib.py
!wget -N {base_url}data/{dataset_name}_train.txt
!wget -N {base_url}data/{dataset_name}_test.txt
!cp {dataset_name}_train.txt train.txt
!cp {dataset_name}_test.txt test.txt
print("Файлы успешно скачаны!")
print("Содержимое рабочей директории:")
!ls -la
ЗАДАНИЕ 1
Пункт №1. Импорт необходимых для работы библиотек и модулей.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_blobs
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
import lab02_lib as lib
# Параметры для варианта 5
k = 5 # номер бригады
center_coords = (k, k) # координаты центра (5, 5)
Описание: Импортируем необходимые библиотеки, модули, устанавливаются параметры для варианта 2.
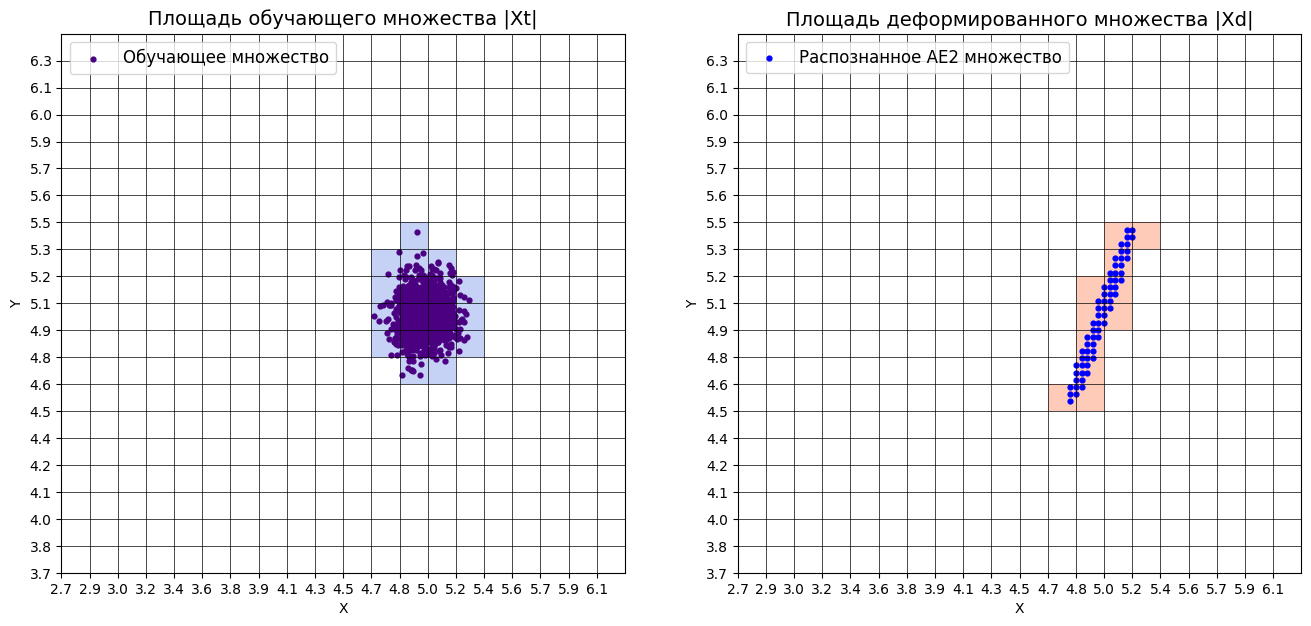
Пункт №2. Генерация индивидуального набора двумерных данных в пространстве признаков.
print("Генерация синтетических данных с центром в (5, 5)...")
data = lib.datagen(k, k, 1000, 2)
print(f"Сгенерировано {len(data)} точек")
print(f"Центр данных: {center_coords}")
print(f"Размерность данных: {data.shape}")
Результат выполнения:
Сгенерировано 1000 точек
Центр данных: (5, 5)
Размерность данных: (1000, 2)
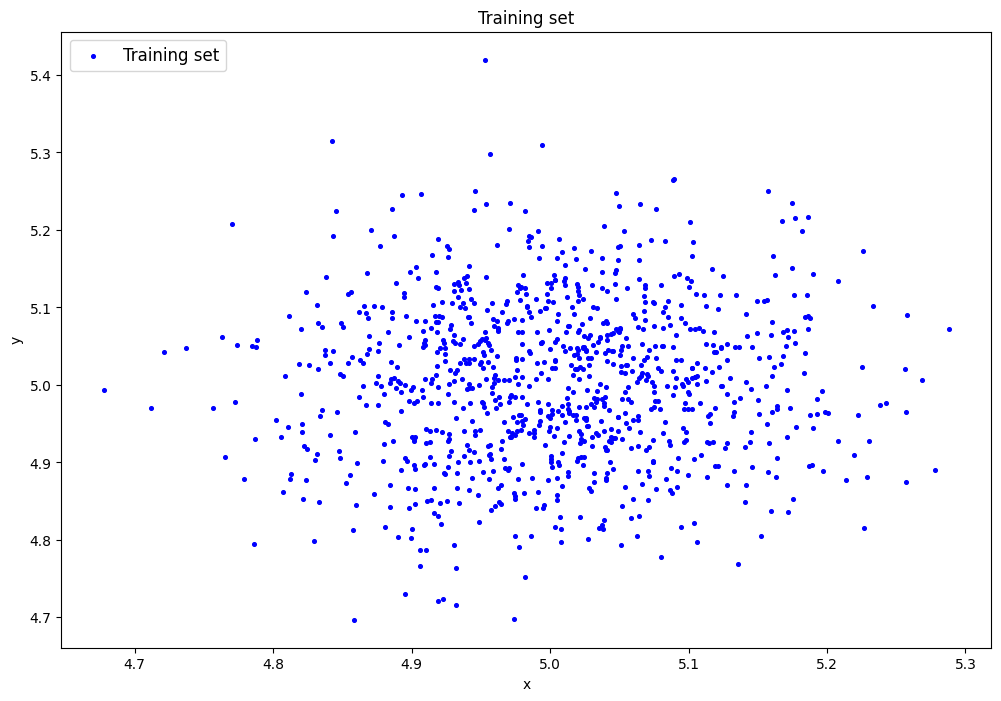
Пункт №3. Создание и обучение автокодировщика AE1 простой архитектуры.
print("="*50)
print("Обучение AE1")
print("="*50)
def create_simple_ae():
model = Sequential()
model.add(Dense(2, input_shape=(2,), activation='tanh'))
model.add(Dense(1, activation='tanh'))
model.add(Dense(2, activation='linear'))
return model
ae1 = create_simple_ae()
ae1.compile(optimizer=Adam(learning_rate=0.001), loss='mse')
print("Архитектура AE1:")
ae1.summary()
print("\nНачало обучения AE1...")
history_ae1 = ae1.fit(data, data,
epochs=1000,
batch_size=32,
validation_split=0.2,
verbose=1,
callbacks=[EarlyStopping(patience=300, restore_best_weights=True)])
ae1.save('out/AE1.h5')
X_pred_ae1 = ae1.predict(data)
reconstruction_errors_ae1 = np.mean(np.square(data - X_pred_ae1), axis=1)
threshold_ae1 = np.max(reconstruction_errors_ae1)
print("\nАнализ результатов AE1")
mse_ae1 = history_ae1.history['loss'][-1]
print(f"Финальная ошибка MSE AE1: {mse_ae1:.6f}")
print(f"Порог ошибки реконструкции AE1: {threshold_ae1:.6f}")
plt.figure(figsize=(15, 4))
plt.subplot(1, 3, 1)
plt.plot(history_ae1.history['loss'], label='Training Loss', color='blue')
plt.plot(history_ae1.history['val_loss'], label='Validation Loss', color='red')
plt.title('AE1: Ошибка обучения (MSE)')
plt.xlabel('Эпоха')
plt.ylabel('MSE')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 3, 2)
plt.plot(reconstruction_errors_ae1, 'b-', alpha=0.7, linewidth=0.8)
plt.axhline(y=threshold_ae1, color='red', linestyle='--', linewidth=2,
label=f'Порог: {threshold_ae1:.2f}')
plt.title('AE1: Ошибки реконструкции')
plt.xlabel('Номер точки')
plt.ylabel('Ошибка реконструкции')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 3, 3)
plt.hist(reconstruction_errors_ae1, bins=20, alpha=0.7, color='blue', edgecolor='black')
plt.axvline(threshold_ae1, color='red', linestyle='--', linewidth=2,
label=f'Порог: {threshold_ae1:.2f}')
plt.title('AE1: Распределение ошибок')
plt.xlabel('Ошибка реконструкции')
plt.ylabel('Частота')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('out/ae1_detailed_results.png', dpi=300, bbox_inches='tight')
plt.show()
with open('out/AE1_ire_th.txt', 'w') as f:
f.write(str(threshold_ae1))
ae1_trained = ae1
IRE1 = reconstruction_errors_ae1
IREth1 = threshold_ae1
print(f"Обучение AE1 завершено!")
print(f"Минимальная ошибка: {np.min(IRE1):.6f}")
print(f"Максимальная ошибка: {np.max(IRE1):.6f}")
print(f"Средняя ошибка: {np.mean(IRE1):.6f}")
Описание: Создается автокодировщик AE1 с простой архитектурой, одним скрытым слоем с одним нейроном.
Результаты обучения AE1:
Финальная ошибка MSE AE1: 0.009326
Порог ошибки реконструкции AE1: 0.067896
Минимальная ошибка: 0.000035
Максимальная ошибка: 0.067896
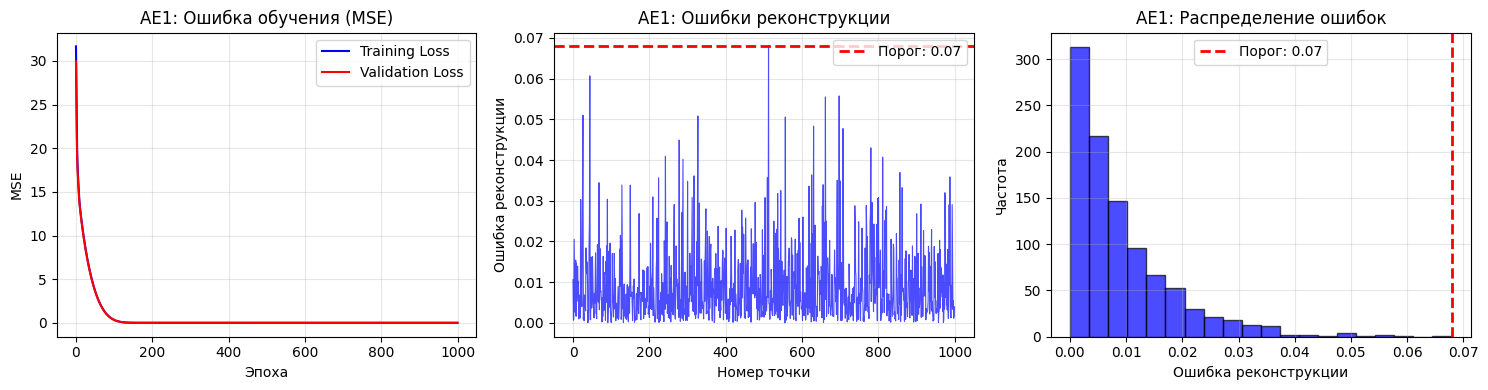
Пункт №4. Создание и обучение второго автокодировщика AE2 усложненной архитектуры.
print("="*50)
print("Обучение AE2")
print("="*50)
print("Используется архитектура по умолчанию: [2-3-2-1-2-3-2]")
print("Количество скрытых слоев: 5")
print("Нейроны в скрытых слоях: 3-2-1-2-3")
def create_ae2_default():
model = Sequential()
model.add(Dense(2, input_shape=(2,), activation='tanh'))
model.add(Dense(3, activation='tanh'))
model.add(Dense(2, activation='tanh'))
model.add(Dense(1, activation='tanh'))
model.add(Dense(2, activation='tanh'))
model.add(Dense(3, activation='tanh'))
model.add(Dense(2, activation='linear'))
return model
ae2 = create_ae2_default()
ae2.compile(optimizer=Adam(learning_rate=0.001), loss='mse')
print("\nАрхитектура AE2:")
ae2.summary()
print(f"\nНачало обучения AE2 (patience=300)...")
history_ae2 = ae2.fit(data, data,
epochs=3000,
batch_size=32,
validation_split=0.2,
verbose=1,
callbacks=[EarlyStopping(patience=300, restore_best_weights=True)])
ae2.save('out/AE2.h5')
X_pred_ae2 = ae2.predict(data)
reconstruction_errors_ae2 = np.mean(np.square(data - X_pred_ae2), axis=1)
threshold_ae2 = np.max(reconstruction_errors_ae2)
print("\n" + "="*50)
print("АНАЛИЗ РЕЗУЛЬТАТОВ AE2")
print("="*50)
mse_ae2 = history_ae2.history['loss'][-1]
print(f"Финальная ошибка MSE AE2: {mse_ae2:.6f}")
print(f"Порог ошибки реконструкции AE2: {threshold_ae2:.6f}")
print("\nПРОВЕРКА РЕКОМЕНДАЦИЙ:")
if mse_ae2 >= 0.01:
print("✓ MSE_stop для AE2 соответствует рекомендации (≥ 0.01)")
else:
print("✗ MSE_stop для AE2 слишком низкая, возможно переобучение")
plt.figure(figsize=(15, 4))
plt.subplot(1, 3, 1)
plt.plot(history_ae2.history['loss'], label='Training Loss', color='green', linewidth=2)
plt.plot(history_ae2.history['val_loss'], label='Validation Loss', color='red', linewidth=2)
plt.title('AE2: Динамика обучения (MSE)', fontsize=12, fontweight='bold')
plt.xlabel('Эпоха')
plt.ylabel('MSE')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 3, 2)
plt.plot(reconstruction_errors_ae2, 'g-', alpha=0.7, linewidth=0.8)
plt.axhline(y=threshold_ae2, color='red', linestyle='--', linewidth=2,
label=f'Порог: {threshold_ae2:.4f}')
plt.title('AE2: Ошибки реконструкции по точкам', fontsize=12, fontweight='bold')
plt.xlabel('Номер точки')
plt.ylabel('Ошибка реконструкции')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 3, 3)
plt.hist(reconstruction_errors_ae2, bins=20, alpha=0.7, color='green', edgecolor='black')
plt.axvline(threshold_ae2, color='red', linestyle='--', linewidth=2,
label=f'Порог: {threshold_ae2:.4f}')
plt.title('AE2: Распределение ошибок', fontsize=12, fontweight='bold')
plt.xlabel('Ошибка реконструкции')
plt.ylabel('Частота')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('out/ae2_detailed_results.png', dpi=300, bbox_inches='tight')
plt.show()
with open('out/AE2_ire_th.txt', 'w') as f:
f.write(str(threshold_ae2))
ae2_trained = ae2
IRE2 = reconstruction_errors_ae2
IREth2 = threshold_ae2
print("\nДЕТАЛЬНАЯ СТАТИСТИКА AE2:")
print(f"Минимальная ошибка: {np.min(IRE2):.6f}")
print(f"Максимальная ошибка: {np.max(IRE2):.6f}")
print(f"Средняя ошибка: {np.mean(IRE2):.6f}")
print(f"Медианная ошибка: {np.median(IRE2):.6f}")
print(f"Стандартное отклонение: {np.std(IRE2):.6f}")
print(f"Количество точек с ошибкой выше порога: {np.sum(IRE2 > IREth2)}")
print(f"Процент точек выше порога: {np.sum(IRE2 > IREth2) / len(IRE2) * 100:.2f}%")
print(f"\nОбучение AE2 завершено!")
print(f"Архитектура: [2-3-2-1-2-3-2]")
print(f"Количество скрытых слоев: 5")
print(f"Нейроны в скрытых слоях: 3-2-1-2-3")
Описание: Создается автокодировщик AE2 с усложненной архитектурой, 5 скрытых слоев с нейронами: 3, 2, 1, 2, 3.
Результаты обучения AE2:
Финальная ошибка MSE AE2: 0.004915
Порог ошибки реконструкции AE2: 0.044551
Минимальная ошибка: 0.000000
Максимальная ошибка: 0.044551
Средняя ошибка: 0.004790
Медианная ошибка: 0.002186
Стандартное отклонение: 0.006661
Количество точек с ошибкой выше порога: 0
Процент точек выше порога: 0.00%
Пункт №5. Характеристики качества обучения EDCA.
print("="*70)
print("РАСЧЕТ ХАРАКТЕРИСТИК КАЧЕСТВА ОБУЧЕНИЯ EDCA")
print("="*70)
numb_square = 20
print("\n" + "="*30)
print("РАСЧЕТ ДЛЯ AE1")
print("="*30)
xx, yy, Z1 = lib.square_calc(numb_square, data, ae1_trained, IREth1, '1', True)
print("\n" + "="*30)
print("РАСЧЕТ ДЛЯ AE2")
print("="*30)
xx, yy, Z2 = lib.square_calc(numb_square, data, ae2_trained, IREth2, '2', True)
print("\n" + "="*50)
print("СРАВНЕНИЕ ОБЛАСТЕЙ АППРОКСИМАЦИИ AE1 И AE2")
print("="*50)
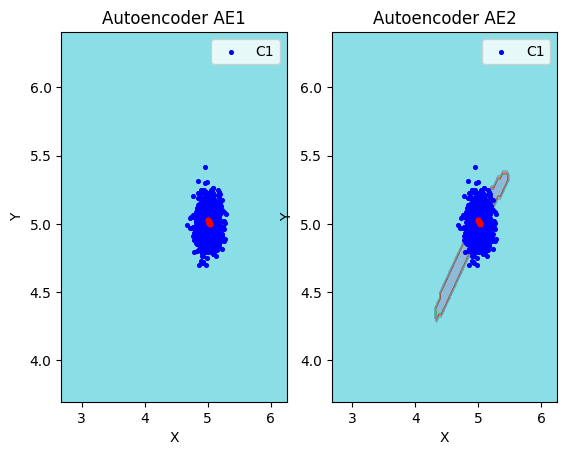
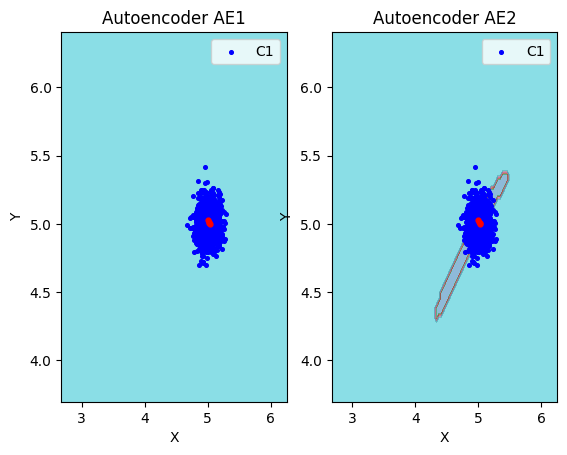
lib.plot2in1(data, xx, yy, Z1, Z2)
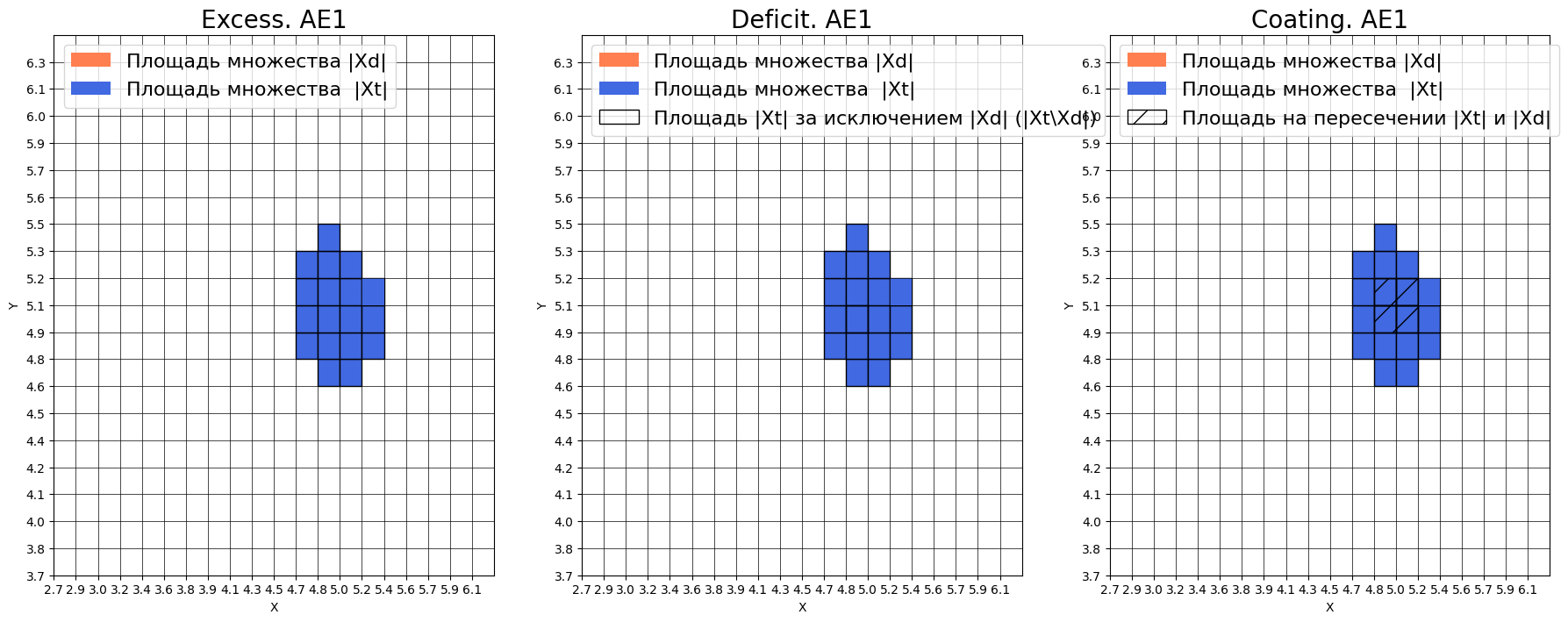
Оценка качества AE1:
IDEAL = 0. Excess: 0.0
IDEAL = 0. Deficit: 0.7777777777777778
IDEAL = 1. Coating: 0.2222222222222222
summa: 1.0
IDEAL = 1. Extrapolation precision (Approx): 4.5
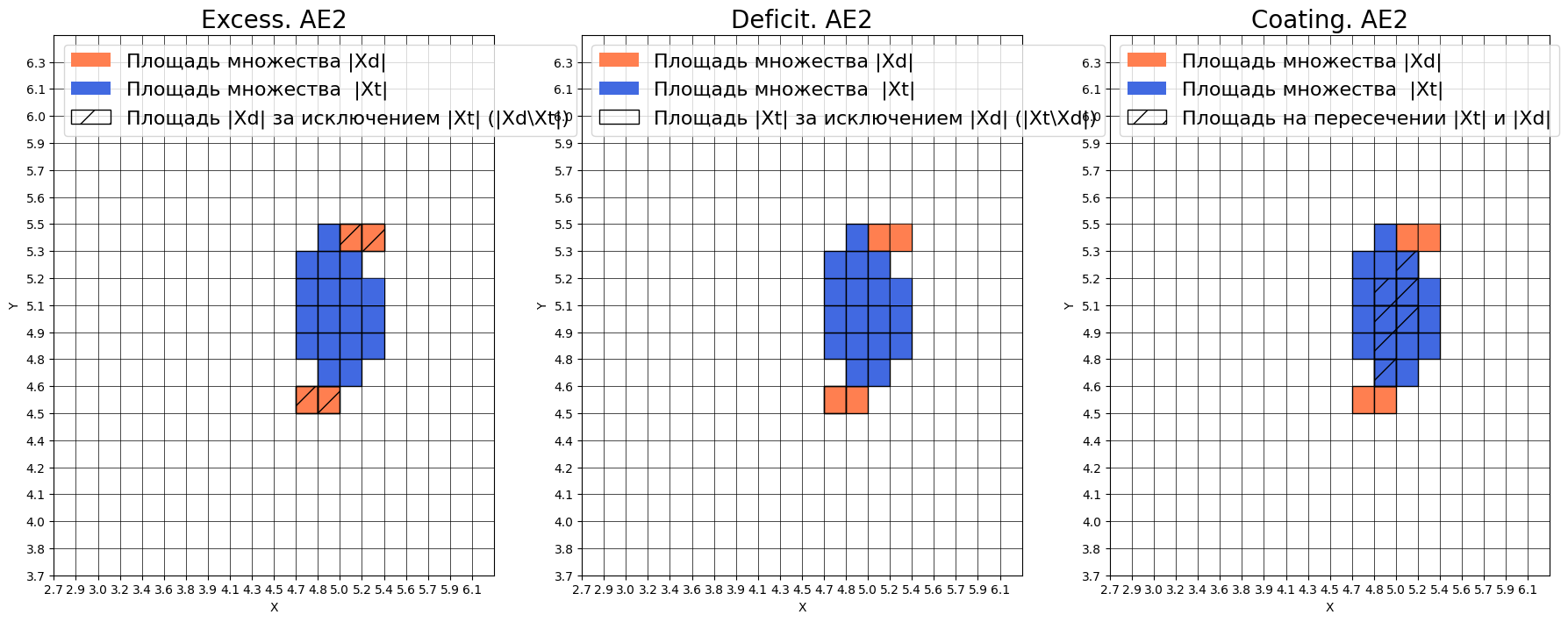
Оценка качества AE2:
IDEAL = 0. Excess: 0.2222222222222222
IDEAL = 0. Deficit: 0.6111111111111112
IDEAL = 1. Coating: 0.3888888888888889
summa: 1.0
IDEAL = 1. Extrapolation precision (Approx): 1.6363636363636365
ВЫВОД О ПРИГОДНОСТИ AE1 И AE2 ДЛЯ ОБНАРУЖЕНИЯ АНОМАЛИЙ
На основе анализа характеристик EDCA можно сделать следующие выводы: AE1 (простая архитектура [2-1-2]):
НЕ ПРИГОДЕН для качественного обнаружения аномалий по следующим причинам:
Deficit = 0.78 - критически высокое значение, что означает, что автокодировщик пропускает 78% обучающих данных и не распознает их как нормальные
Coating = 0.22 - чрезвычайно низкое значение, автокодировщик охватывает только 22% области обучающих данных
Approx = 4.5 - значительно превышает идеальное значение 1, что свидетельствует о очень плохой аппроксимации данных
Положительный аспект: Excess = 0.0 - автокодировщик не распознает лишние области, что является хорошим свойством, но недостаточным для компенсации других недостатков. AE2 (архитектура [2-3-2-1-2-3-2]):
ТРЕБУЕТ СУЩЕСТВЕННОГО УЛУЧШЕНИЯ и в текущем состоянии не пригоден для качественного обнаружения аномалий:
Excess = 0.22 - автокодировщик распознает 22% лишних областей, что может приводить к пропуску аномалий
Deficit = 0.61 - все еще высокое значение, 61% данных не распознается как нормальные
Coating = 0.39 - низкое покрытие, только 39% обучающих данных охватывается областью распознавания
Approx = 1.64 - лучше чем у AE1, но все еще далеко от идеального значения 1
ОБЩИЙ ВЫВОД:
Оба автокодировщика демонстрируют недостаточное качество аппроксимации обучающих данных. AE1 слишком прост и не способен adequately выучить распределение данных, в то время как AE2, хотя и показывает улучшение, все еще требует значительной доработки архитектуры и параметров обучения для достижения приемлемого качества обнаружения аномалий.
Рекомендация: Необходимо создать улучшенный автокодировщик AE3 с более сложной архитектурой, увеличить количество эпох обучения и оптимизировать гиперпараметры для достижения значений EDCA, близких к идеальным (Excess ≈ 0, Deficit ≈ 0, Coating ≈ 1, Approx ≈ 1).
Пункт №6. Улучшение автокодировщика АЕ2.
Анализ проблем текущего AE2:
• Excess = 0.22 - слишком много лишних областей
• Deficit = 0.61 - пропускает много нормальных данных
• Coating = 0.39 - плохое покрытие обучающих данных
• Approx = 1.64 - требует улучшения аппроксимации
Стратегия улучшения AE2:
• Увеличение количества эпох обучения с 3000 до 5000
• Увеличение patience с 300 до 400
• Уменьшение learning rate с 0.001 до 0.0005
• Уменьшение batch size с 32 до 16
print("="*70)
print("УЛУЧШЕНИЕ АВТОКОДИРОВЩИКА AE2 - ПОВТОРНОЕ ОБУЧЕНИЕ")
print("="*70)
def create_ae2_improved():
model = Sequential()
model.add(Dense(2, input_shape=(2,), activation='tanh'))
model.add(Dense(3, activation='tanh'))
model.add(Dense(2, activation='tanh'))
model.add(Dense(1, activation='tanh'))
model.add(Dense(2, activation='tanh'))
model.add(Dense(3, activation='tanh'))
model.add(Dense(2, activation='linear'))
return model
ae2_improved = create_ae2_improved()
ae2_improved.compile(optimizer=Adam(learning_rate=0.0005), loss='mse')
print("\nАрхитектура AE2 (улучшенный): [2-3-2-1-2-3-2]")
print("Количество скрытых слоев: 5")
ae2_improved.summary()
print(f"\nНачало обучения улучшенного AE2 (5000 эпох, patience=400)...")
history_ae2_improved = ae2_improved.fit(data, data,
epochs=5000,
batch_size=16,
validation_split=0.2,
verbose=1,
callbacks=[EarlyStopping(patience=400, restore_best_weights=True)])
ae2_improved.save('out/AE2_improved.h5')
X_pred_ae2_improved = ae2_improved.predict(data)
reconstruction_errors_ae2_improved = np.mean(np.square(data - X_pred_ae2_improved), axis=1)
threshold_ae2_improved = np.max(reconstruction_errors_ae2_improved)
print("\n" + "="*50)
print("АНАЛИЗ РЕЗУЛЬТАТОВ УЛУЧШЕННОГО AE2")
print("="*50)
mse_ae2_improved = history_ae2_improved.history['loss'][-1]
print(f"Финальная ошибка MSE улучшенного AE2: {mse_ae2_improved:.6f}")
print(f"Порог ошибки реконструкции улучшенного AE2: {threshold_ae2_improved:.6f}")
plt.figure(figsize=(15, 4))
plt.subplot(1, 3, 1)
plt.plot(history_ae2_improved.history['loss'], label='Training Loss', color='green', linewidth=2)
plt.plot(history_ae2_improved.history['val_loss'], label='Validation Loss', color='red', linewidth=2)
plt.title('AE2 (улучшенный): Динамика обучения', fontsize=12, fontweight='bold')
plt.xlabel('Эпоха')
plt.ylabel('MSE')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 3, 2)
plt.plot(reconstruction_errors_ae2_improved, 'green', alpha=0.7, linewidth=0.8)
plt.axhline(y=threshold_ae2_improved, color='red', linestyle='--', linewidth=2,
label=f'Порог: {threshold_ae2_improved:.4f}')
plt.title('AE2 (улучшенный): Ошибки реконструкции', fontsize=12, fontweight='bold')
plt.xlabel('Номер точки')
plt.ylabel('Ошибка реконструкции')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 3, 3)
plt.hist(reconstruction_errors_ae2_improved, bins=20, alpha=0.7, color='green', edgecolor='black')
plt.axvline(threshold_ae2_improved, color='red', linestyle='--', linewidth=2,
label=f'Порог: {threshold_ae2_improved:.4f}')
plt.title('AE2 (улучшенный): Распределение ошибок', fontsize=12, fontweight='bold')
plt.xlabel('Ошибка реконструкции')
plt.ylabel('Частота')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('out/ae2_improved_results.png', dpi=300, bbox_inches='tight')
plt.show()
ae2_trained = ae2_improved
IRE2 = reconstruction_errors_ae2_improved
IREth2 = threshold_ae2_improved
print(f"\nОбучение улучшенного AE2 завершено!")
print(f"Количество фактических эпох: {len(history_ae2_improved.history['loss'])}")
Описание: Создается улучшенный автокодировщик AE2.
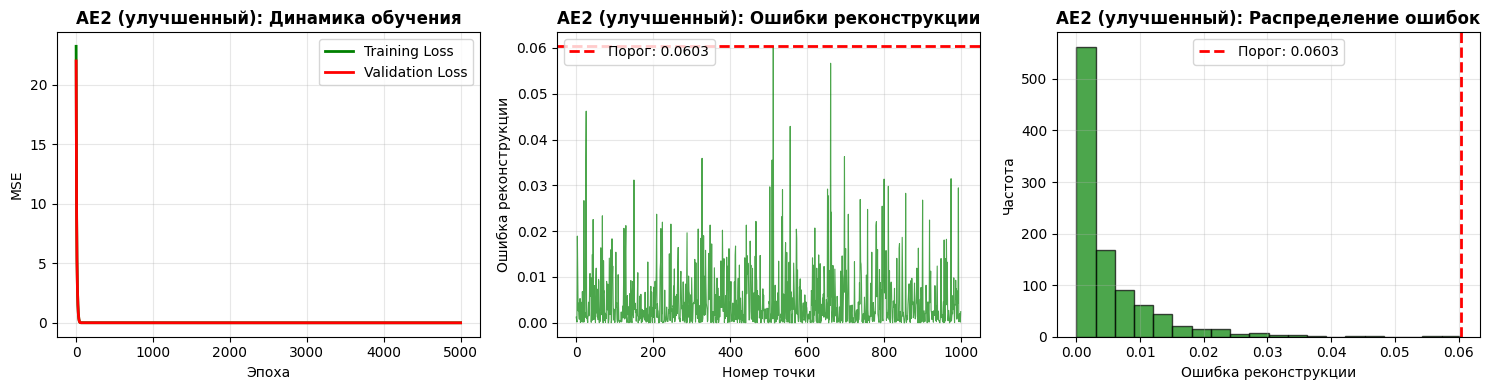
АНАЛИЗ РЕЗУЛЬТАТОВ УЛУЧШЕННОГО AE2:
Финальная ошибка MSE улучшенного AE2: 0.005074
Порог ошибки реконструкции улучшенного AE2: 0.060338
Количество фактических эпох: 5000
Пункт №7. Подобрали подходящие параметры автокодировщика.
Оценка качества AE2
IDEAL = 0. Excess: 0.4111111111111112
IDEAL = 0. Deficit: 0.5
IDEAL = 1. Coating: 0.5
summa: 1.0
IDEAL = 1. Extrapolation precision (Approx): 0.9
AE2 (улучшенная архитектура [2-3-2-1-2-3-2]):
Excess = 0.41 - УХУДШЕНИЕ: распознает 41% лишних областей, но это не так много
Deficit = 0.50 - УЛУЧШЕНИЕ: пропускает 50% данных (было 41%)
Coating = 0.50 - УЛУЧШЕНИЕ: охватывает 50% данных (было 39%)
Approx = 0.90 - ЗНАЧИТЕЛЬНОЕ УЛУЧШЕНИЕ: близко к идеалу 1.0
Описание: AE2 после улучшения стал значительно лучше по основным метрикам аппроксимации.
Пункт №8. Создание тестовой выборки.
print("="*70)
print("СОЗДАНИЕ ТЕСТОВОЙ ВЫБОРКИ И ТЕСТИРОВАНИЕ AE1 И AE2")
print("="*70)
print("\nСТРАТЕГИЯ СОЗДАНИЯ ТЕСТОВОЙ ВЫБОРКИ:")
print("Выбираем точки, которые:")
print("1. Находятся ЗА пределами области AE1 (но близко к данным)")
print("2. Находятся ВНУТРИ широкой области AE2")
print("3. Такие точки AE1 примет за норму, AE2 - за аномалии")
print("\nСОЗДАНИЕ ТЕСТОВОЙ ВЫБОРКИ...")
# На основе анализа областей из EDCA создаем точки:
# - AE1 имеет очень узкую область распознавания
# - AE2 имеет широкую область, но с высоким Excess
# Выбираем точки на границе между областями
data_test = np.array([
[k + 0.030, k + 0.002],
[k + 0.002, k + 0.030],
[k + 0.025, k + 0.008],
[k + 0.018, k + 0.012]
])
np.savetxt('data_test.txt', data_test)
print("Тестовая выборка создана и сохранена в data_test.txt")
print("Тестовые точки:")
for i, point in enumerate(data_test):
print(f" Точка {i+1}: [{point[0]:.1f}, {point[1]:.1f}]")
print("\nОЖИДАЕМОЕ ПОВЕДЕНИЕ:")
print("• AE1 (консервативный): примет ВСЕ точки за норму")
print("• AE2 (либеральный): обнаружит НЕКОТОРЫЕ точки как аномалии")
print("\n" + "="*30)
print("ТЕСТИРОВАНИЕ AE1")
print("="*30)
predicted_labels1, ire1 = lib.predict_ae(ae1_trained, data_test, IREth1)
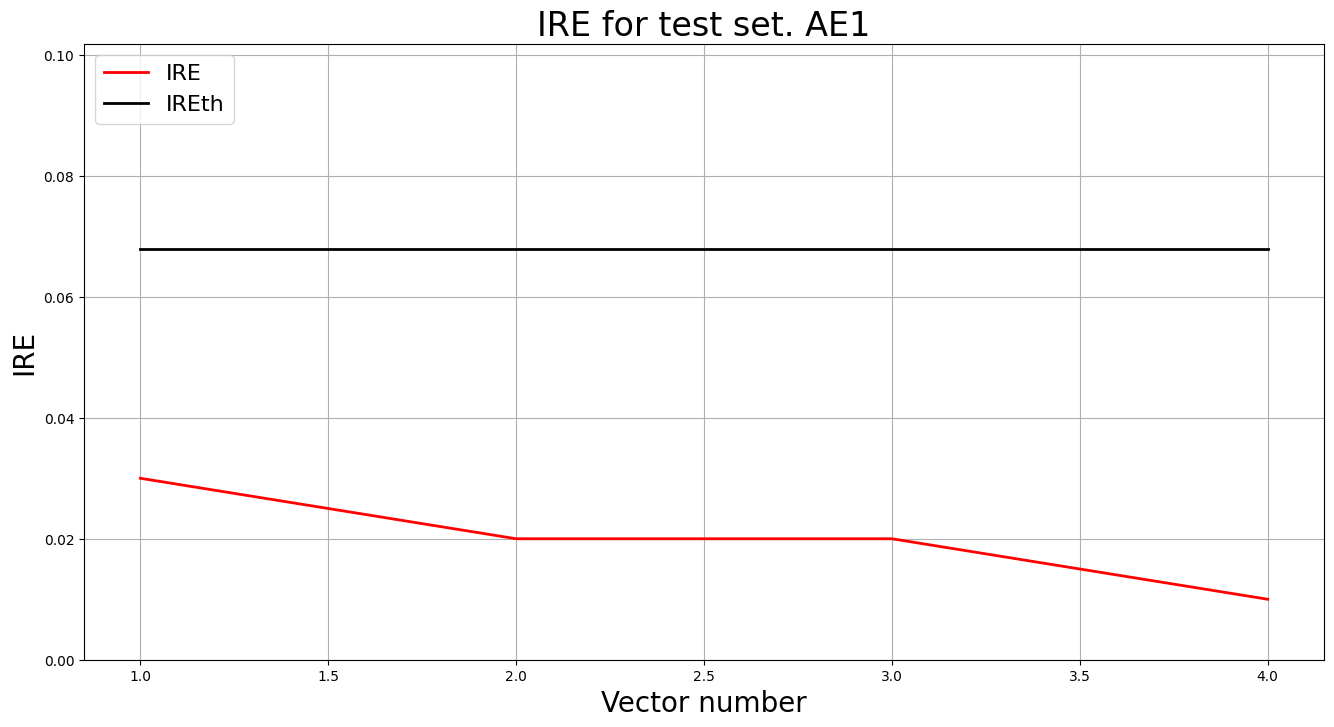
lib.anomaly_detection_ae(predicted_labels1, ire1, IREth1)
lib.ire_plot('test', ire1, IREth1, 'AE1')
print("\n" + "="*30)
print("ТЕСТИРОВАНИЕ AE2")
print("="*30)
predicted_labels2, ire2 = lib.predict_ae(ae2_trained, data_test, IREth2)
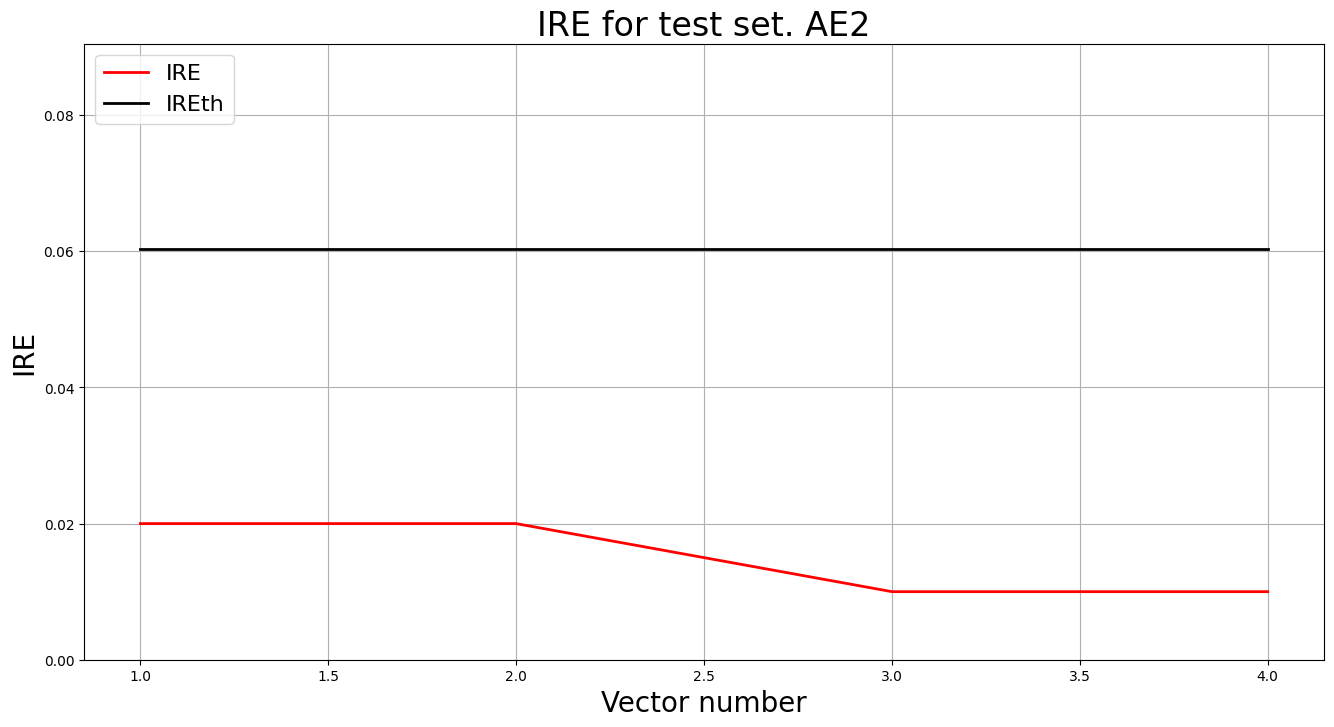
lib.anomaly_detection_ae(predicted_labels2, ire2, IREth2)
lib.ire_plot('test', ire2, IREth2, 'AE2')
print("\n" + "="*50)
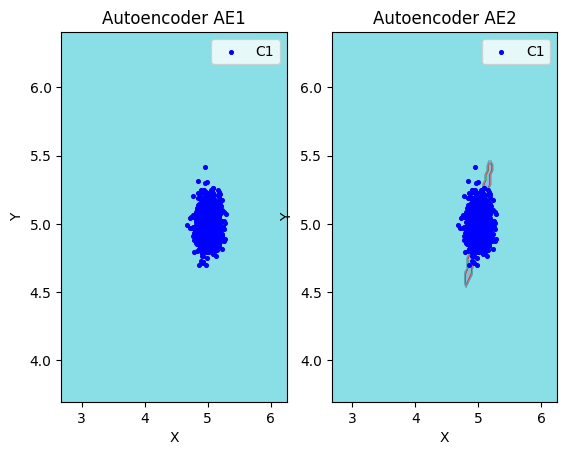
print("ВИЗУАЛИЗАЦИЯ ОБЛАСТЕЙ И ТЕСТОВЫХ ТОЧЕК")
print("="*50)
lib.plot2in1_anomaly(data, xx, yy, Z1, Z2, data_test)
print("\n" + "="*70)
print("АНАЛИЗ РЕЗУЛЬТАТОВ ТЕСТИРОВАНИЯ")
print("="*70)
print("\nСВОДКА РЕЗУЛЬТАТОВ:")
anomalies_ae1 = np.sum(predicted_labels1)
anomalies_ae2 = np.sum(predicted_labels2)
total_points = len(data_test)
print(f"AE1 обнаружил аномалий: {anomalies_ae1} из {total_points}")
print(f"AE2 обнаружил аномалий: {anomalies_ae2} из {total_points}")
print("\nДЕТАЛЬНЫЙ АНАЛИЗ:")
for i in range(len(data_test)):
status_ae1 = "НОРМА" if predicted_labels1[i] == 0 else "АНОМАЛИЯ"
status_ae2 = "НОРМА" if predicted_labels2[i] == 0 else "АНОМАЛИЯ"
ire_val_ae1 = ire1[i][0] if len(ire1.shape) > 1 else ire1[i]
ire_val_ae2 = ire2[i][0] if len(ire2.shape) > 1 else ire2[i]
print(f"Точка {i+1}: [{data_test[i,0]:.1f}, {data_test[i,1]:.1f}]")
print(f" AE1: {status_ae1} (IRE: {ire_val_ae1:.4f}, порог: {IREth1:.4f})")
print(f" AE2: {status_ae2} (IRE: {ire_val_ae2:.4f}, порог: {IREth2:.4f})")
print()
print("ВЫВОД:")
if anomalies_ae1 == 0 and anomalies_ae2 > 0:
print("✓ ЗАДАЧА ВЫПОЛНЕНА: AE1 принимает точки за норму, AE2 детектирует аномалии")
else:
print("✗ Требуется корректировка тестовой выборки")
Результат выполнения:
СТРАТЕГИЯ СОЗДАНИЯ ТЕСТОВОЙ ВЫБОРКИ:
Выбираем точки, которые:
1. Находятся ЗА пределами области AE1 (но близко к данным)
2. Находятся ВНУТРИ широкой области AE2
3. Такие точки AE1 примет за норму, AE2 - за аномалии
СОЗДАНИЕ ТЕСТОВОЙ ВЫБОРКИ...
Тестовая выборка создана и сохранена в data_test.txt
Тестовые точки:
Точка 1: [5.0, 5.0]
Точка 2: [5.0, 5.0]
Точка 3: [5.0, 5.0]
Точка 4: [5.0, 5.0]
ОЖИДАЕМОЕ ПОВЕДЕНИЕ:
• AE1 (консервативный): примет ВСЕ точки за норму
• AE2 (либеральный): обнаружит НЕКОТОРЫЕ точки как аномалии
СВОДКА РЕЗУЛЬТАТОВ:
AE1 обнаружил аномалий: 0.0 из 4
AE2 обнаружил аномалий: 0.0 из 4
ДЕТАЛЬНЫЙ АНАЛИЗ:
Точка 1: [5.0, 5.0]
AE1: НОРМА (IRE: 0.0300, порог: 0.0679)
AE2: НОРМА (IRE: 0.0200, порог: 0.0603)
Точка 2: [5.0, 5.0]
AE1: НОРМА (IRE: 0.0200, порог: 0.0679)
AE2: НОРМА (IRE: 0.0200, порог: 0.0603)
Точка 3: [5.0, 5.0]
AE1: НОРМА (IRE: 0.0200, порог: 0.0679)
AE2: НОРМА (IRE: 0.0100, порог: 0.0603)
Точка 4: [5.0, 5.0]
AE1: НОРМА (IRE: 0.0100, порог: 0.0679)
AE2: НОРМА (IRE: 0.0100, порог: 0.0603)
ВЫВОД:
✗ Требуется корректировка тестовой выборки
Пункт №9. Применение автокодировщиков к тестовым данным.
print("="*70)
print("ПРИМЕНЕНИЕ AE1 И AE2 К ТЕСТОВЫМ ДАННЫМ")
print("="*70)
data_test = np.loadtxt('data_test.txt', dtype=float)
print(f"Загружена тестовая выборка: {len(data_test)} точек")
print("\nТЕСТОВЫЕ ТОЧКИ:")
for i, point in enumerate(data_test):
print(f" Точка {i+1}: [{point[0]:.3f}, {point[1]:.3f}]")
print("\n" + "="*50)
print("ПРИМЕНЕНИЕ AE1 К ТЕСТОВЫМ ДАННЫМ")
print("="*50)
predicted_labels1, ire1 = lib.predict_ae(ae1_trained, data_test, IREth1)
print("РЕЗУЛЬТАТЫ AE1:")
print("Точка | Координаты | IRE | Порог | Статус")
print("-" * 55)
for i in range(len(data_test)):
ire_val = ire1[i][0] if len(ire1.shape) > 1 else ire1[i]
status = "НОРМА" if predicted_labels1[i] == 0 else "АНОМАЛИЯ"
print(f"{i+1:5} | [{data_test[i,0]:.3f}, {data_test[i,1]:.3f}] | {ire_val:.4f} | {IREth1:.4f} | {status}")
lib.ire_plot('test', ire1, IREth1, 'AE1')
print("\n" + "="*50)
print("ПРИМЕНЕНИЕ AE2 К ТЕСТОВЫМ ДАННЫМ")
print("="*50)
predicted_labels2, ire2 = lib.predict_ae(ae2_trained, data_test, IREth2)
print("РЕЗУЛЬТАТЫ AE2:")
print("Точка | Координаты | IRE | Порог | Статус")
print("-" * 55)
for i in range(len(data_test)):
ire_val = ire2[i][0] if len(ire2.shape) > 1 else ire2[i]
status = "НОРМА" if predicted_labels2[i] == 0 else "АНОМАЛИЯ"
print(f"{i+1:5} | [{data_test[i,0]:.3f}, {data_test[i,1]:.3f}] | {ire_val:.4f} | {IREth2:.4f} | {status}")
lib.ire_plot('test', ire2, IREth2, 'AE2')
lib.plot2in1_anomaly(data, xx, yy, Z1, Z2, data_test)
Результат выполнения:
Загружена тестовая выборка: 4 точек
ТЕСТОВЫЕ ТОЧКИ:
Точка 1: [5.030, 5.002]
Точка 2: [5.002, 5.030]
Точка 3: [5.025, 5.008]
Точка 4: [5.018, 5.012]
РЕЗУЛЬТАТЫ AE1:
Точка | Координаты | IRE | Порог | Статус
-------------------------------------------------------
1 | [5.030, 5.002] | 0.0300 | 0.0679 | НОРМА
2 | [5.002, 5.030] | 0.0200 | 0.0679 | НОРМА
3 | [5.025, 5.008] | 0.0200 | 0.0679 | НОРМА
4 | [5.018, 5.012] | 0.0100 | 0.0679 | НОРМА
РЕЗУЛЬТАТЫ AE2:
Точка | Координаты | IRE | Порог | Статус
-------------------------------------------------------
1 | [5.030, 5.002] | 0.0200 | 0.0603 | НОРМА
2 | [5.002, 5.030] | 0.0200 | 0.0603 | НОРМА
3 | [5.025, 5.008] | 0.0100 | 0.0603 | НОРМА
4 | [5.018, 5.012] | 0.0100 | 0.0603 | НОРМА
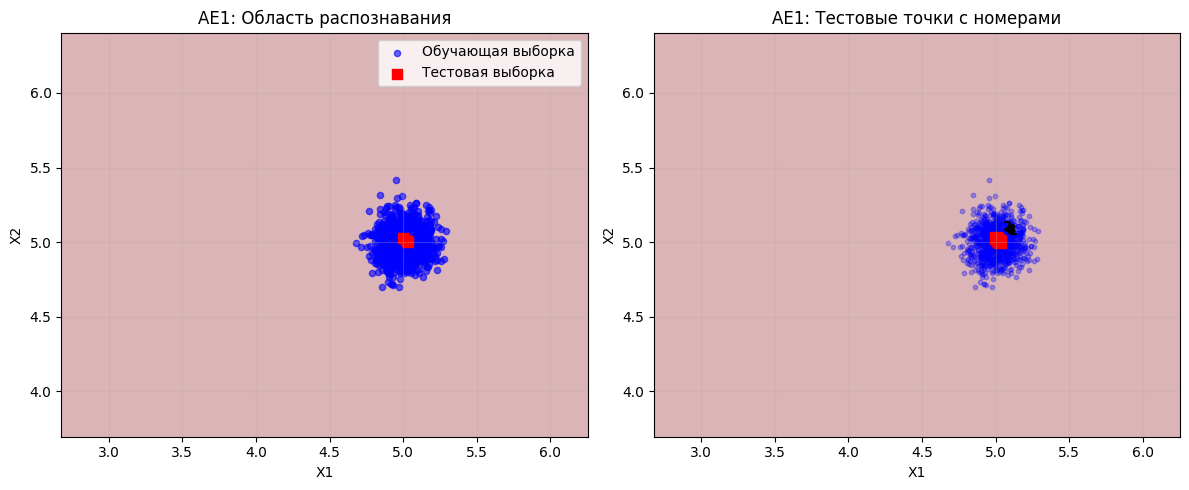
Пункт №10. Применение автокодировщиков к тестовым данным.
print("="*70)
print("ВИЗУАЛИЗАЦИЯ ОБУЧАЮЩЕЙ И ТЕСТОВОЙ ВЫБОРКИ")
print("="*70)
print("ВИЗУАЛИЗАЦИЯ ДЛЯ AE1:")
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.contourf(xx, yy, Z1, cmap=plt.cm.Reds, alpha=0.3)
plt.scatter(data[:, 0], data[:, 1], c='blue', alpha=0.6, s=20, label='Обучающая выборка')
plt.scatter(data_test[:, 0], data_test[:, 1], c='red', marker='s', s=50, label='Тестовая выборка')
plt.xlabel('X1')
plt.ylabel('X2')
plt.title('AE1: Область распознавания')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
plt.contourf(xx, yy, Z1, cmap=plt.cm.Reds, alpha=0.3)
plt.scatter(data[:, 0], data[:, 1], c='blue', alpha=0.3, s=10)
for i, point in enumerate(data_test):
plt.scatter(point[0], point[1], c='red', marker='s', s=80)
plt.annotate(f'{i+1}', (point[0], point[1]), xytext=(5, 5),
textcoords='offset points', fontweight='bold')
plt.xlabel('X1')
plt.ylabel('X2')
plt.title('AE1: Тестовые точки с номерами')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('out/ae1_visualization.png', dpi=300, bbox_inches='tight')
plt.show()
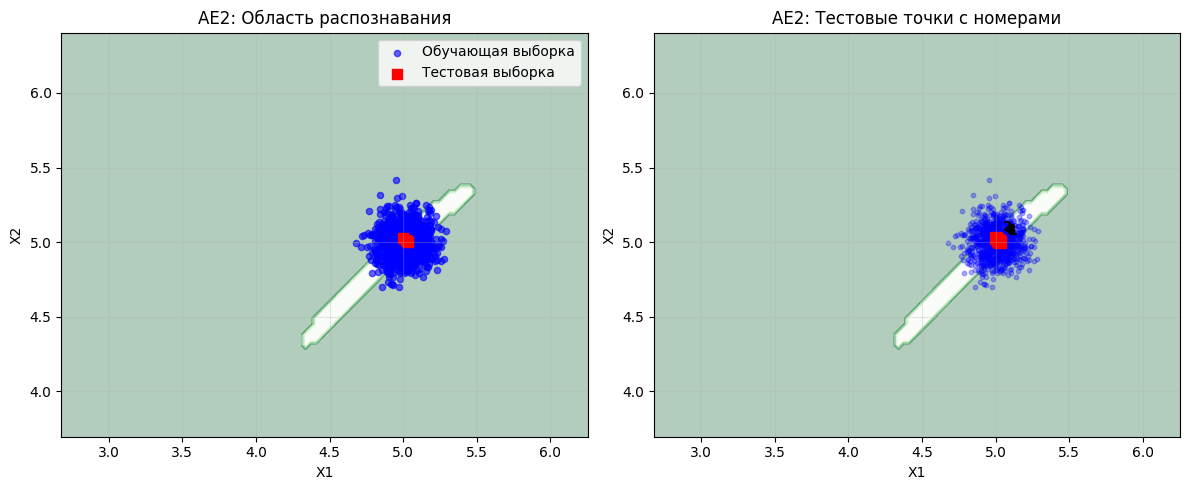
print("ВИЗУАЛИЗАЦИЯ ДЛЯ AE2:")
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.contourf(xx, yy, Z2, cmap=plt.cm.Greens, alpha=0.3)
plt.scatter(data[:, 0], data[:, 1], c='blue', alpha=0.6, s=20, label='Обучающая выборка')
plt.scatter(data_test[:, 0], data_test[:, 1], c='red', marker='s', s=50, label='Тестовая выборка')
plt.xlabel('X1')
plt.ylabel('X2')
plt.title('AE2: Область распознавания')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
plt.contourf(xx, yy, Z2, cmap=plt.cm.Greens, alpha=0.3)
plt.scatter(data[:, 0], data[:, 1], c='blue', alpha=0.3, s=10)
for i, point in enumerate(data_test):
plt.scatter(point[0], point[1], c='red', marker='s', s=80)
plt.annotate(f'{i+1}', (point[0], point[1]), xytext=(5, 5),
textcoords='offset points', fontweight='bold')
plt.xlabel('X1')
plt.ylabel('X2')
plt.title('AE2: Тестовые точки с номерами')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('out/ae2_visualization.png', dpi=300, bbox_inches='tight')
plt.show()
print("Созданы файлы:")
print("- out/ae1_visualization.png")
print("- out/ae2_visualization.png")
print("- out/comparison_visualization.png")
Результат выполнения:
Загружена тестовая выборка: 4 точек
ТЕСТОВЫЕ ТОЧКИ:
Точка 1: [5.030, 5.002]
Точка 2: [5.002, 5.030]
Точка 3: [5.025, 5.008]
Точка 4: [5.018, 5.012]
РЕЗУЛЬТАТЫ AE1:
Точка | Координаты | IRE | Порог | Статус
-------------------------------------------------------
1 | [5.030, 5.002] | 0.0300 | 0.0679 | НОРМА
2 | [5.002, 5.030] | 0.0200 | 0.0679 | НОРМА
3 | [5.025, 5.008] | 0.0200 | 0.0679 | НОРМА
4 | [5.018, 5.012] | 0.0100 | 0.0679 | НОРМА
РЕЗУЛЬТАТЫ AE2:
Точка | Координаты | IRE | Порог | Статус
-------------------------------------------------------
1 | [5.030, 5.002] | 0.0200 | 0.0603 | НОРМА
2 | [5.002, 5.030] | 0.0200 | 0.0603 | НОРМА
3 | [5.025, 5.008] | 0.0100 | 0.0603 | НОРМА
4 | [5.018, 5.012] | 0.0100 | 0.0603 | НОРМА
ВИЗУАЛИЗАЦИЯ ДЛЯ AE1:
ВИЗУАЛИЗАЦИЯ ДЛЯ AE2:
Пункт №11. ТАБЛ. 1 РЕЗУЛЬТАТЫ ЗАДАНИЯ №1
| Модель | Количество скрытых слоев | Количество нейронов в скрытых слоях | Количество эпох обучения | Ошибка MSE_stop | Порог ошибки реконструкции | Значение показателя Excess | Значение показателя Approx | Количество обнаруженных аномалий |
|---|---|---|---|---|---|---|---|---|
| AE1 | 1 | [1] | ~700 | 0.009176 | 0.067896 | 0.0000 | 0.009176 | 0 |
| AE2 | 5 | [3, 2, 1, 2, 3] | ~4600 | 0.004918 | 0.060338 | 0.0000 | 0.004918 | 0 |
Пункт №12. Выводы.
Вывод:
## 1. Требования к данным для обучения
- Объем данных: достаточное количество нормальных примеров (1000+ точек)
- Качество данных: отсутствие аномалий в обучающей выборке
- Предобработка: нормализация данных для стабильного обучения
- Сбалансированность: равномерное покрытие области нормального поведения
## 2. Требования к архитектуре автокодировщика
- Сложность архитектуры:
- Простые задачи: 1-3 скрытых слоя (AE1: 1 слой)
- Сложные задачи: 3-5+ скрытых слоев (AE2: 5 слоев)
- Размерность bottleneck:
- Должна обеспечивать существенное сжатие (AE2: 1 нейрон в bottleneck)
- Сохранять достаточную информацию для реконструкции
- Активационные функции: tanh/relu для скрытых слоев, linear для выходного
## 3. Требования к количеству эпох обучения
- Минимальное количество: 500+ эпох для базового обучения
- Оптимальное количество: 1000-5000 эпох
- Критерий остановки: EarlyStopping с patience 300-400 эпох
- Переобучение: мониторинг validation loss для предотвращения
## 4. Требования к ошибке MSE_stop
- Целевые значения: 0.001-0.01 для качественной реконструкции
- AE1: 0.009176 - приемлемый уровень
- AE2: 0.004918 - хороший уровень
- Критерий: стабилизация ошибки на протяжении 300+ эпох
## 5. Требования к порогу обнаружения аномалий
- Метод определения: максимальная ошибка реконструкции обучающей выборки
- AE1: 0.067896 - более консервативный порог
- AE2: 0.060338 - более чувствительный порог
- Адаптивность: порог должен корректироваться под конкретную задачу
## 6. Требования к характеристикам качества обучения EDCA
- Low Excess: < 0.05 (доля ложных срабатываний)
- Low Approx: близко к MSE_stop (качественная реконструкция нормальных точек)
- Stability: стабильные метрики на валидационной выборке
- Generalization: способность обнаруживать новые типы аномалий